【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
2015年4月6日,ZStack企业版发布,转眼5年过去,从技术革新到产品落地,从市场推广到实现上千用户应用部署。
5年,走最难的路,做最简单的IaaS;
5年,重塑IaaS架构,代码量从0到上百万行;
5年,搭建zstack.io社区,活跃用户从0到10000+;
5年,赢得合作伙伴信赖,服务商用客户超过1200家;
5年,我们共同见证了一家优秀企业的成长!
...
值此ZStack5周年&2020年ZStack新品线上超级发布会之际,我们特别邀请了zstack.io社区的老朋友们,分享他们与ZStack的难忘瞬间!
ZStack社区网友祝福
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
本文作者:y****n
新基建浪潮下,作为人工智能的动力和“灵魂”,数据服务行业正在高速增长。
6月17日,百度智能云举办线上Techday技术分享日,畅聊AI基础数据服务行业新机遇、新增长和社会价值。百度智能云数据众包作为国内最大的AI数据服务提供者,2019年业务年度增长率超50%,正在为各行各业智能化转型提供动能,促进智能经济发展。同时,百度智能云数据众包预计5年内为山西提供超过5万个就业岗位,支持后疫情时代“保就业”。 新基建,新增长
近年来,国内AI发展驶入快车道,而作为AI技术发展的基石,数据需求与日俱增,这也使得AI数据服务行业迎来了空前的发展。
艾瑞咨询《2019年中国人工智能基础数据服务行业研究报告》显示,人工智能基础数据服务市场规模2025年将破百亿,行业复合增长率达到23.5%。凭借着较早的布局和投入,百度智能云数据众包实现了市场占有率和营收规模业界第一,2019年业务年度增长率超50%。今年,新基建成为促进经济发展的新方向,人工智能则是新基建的代表性技术,为数据服务行业的发展注入新的动力。
百度智能云数据众包资深产品运营师李明在会上表示,自2011年起,百度智能云数据众包就全面支持百度自动驾驶、小度助手等AI业务。经过十年沉淀和打磨百度智能云已经建立起采标能力业界第一、流程标准化工具智能化、全流程管控确保数据安全的一站式AI数据服务平台,全面涵盖了包括智能驾驶、手机行业、互联网和AI开发者四大领域的全部头部客户,成为国内最大的AI数据服务提供者。
采标能力方面,百度智能云数据众包建立起了业界第一的海量人工智能基础数据采标能力。通过自建山西标注基地,拥有超过2000名专业全职标注人员;构建了遍布全国乃至全球22个国家渠道代理资源池,拥有超过5万名线下采集员;超过2000万名的众包互联网用户,随时响应各类数据采标需求,满足市场95%标注场景需求。
数据质量建设方面,百度智能云数据众包,建立起了一套标准化、工业化的生产流程和过程管理体系。在规范数据生产流程同时,标注生产环节以自动识别算法辅助标注效率和标注质量提升。
安全性和合规性方面,百度智能云数据众包实现了数据安全和数据合规的全流程管控,从数据合规、客户合规、用户合规、隐私合规四个方面,以及数据获取、数据加工、数据流出三个数据流转阶段,对数据隐私和安全进行保障。
正是基于百度智能云数据众包全面、高质高效、安全合规的数据采标服务,各个行业的AI应用得以更好的实现落地。以自动驾驶为例,行业迫切需要数据量充沛多元的专用数据平台,为此百度智能云数据众包与智能驾驶实验室配合完成了对数10万针的高分辨率的图像标注,标注内容涵盖了语义标注、稠密点云、立体图像、立体全景图像,以及复杂的环境、天气和交通状况等等,使得百度ApolloScape拥有全球最复杂的自动驾驶高精度数据集,为全球自动驾驶开发者提供了更丰富和更复杂的数据应用场景去训练学习和评测。
产业智能化,促经济保就业
百度智能云数据众包在促进传统行业转型升级,带动就业方面也扮演了重要作用。山西地区以能源行业为主,而标注基地则承接了传统行业分流过来的部分人员,不仅给他们提供了更多的就业机会,也让更多传统企业开始关注起其所在行业的变化。目前,百度智能云位于山西的标注基地已帮助2300人实现就业,帮助山西从全国各地引入34家国内优秀的数据标注企业,2019年全年实现标注业务产值超亿元。预计未来5年内,百度智能云数据众包和百度(山西)数据标注产业基地将为当地提供超过5万个就业岗位,为后疫情时代的稳就业、保就业提供强有力支持。
在今年疫情期间,通过标注云平台+云端分包+远程办公协同,百度智能云帮助123家数据标注企业3300余人复工投产。2月3日,百度(山西)数据标注产业基地1300多人远程线上复工,复工率超过80%。基地作业人员加班加点,紧急完成了肺炎影像标注、戴口罩的人脸图像标注、武汉方言语音数据采集与标注、智能驾驶数据标注等数据服务。依据这些数据建立的模型应用于AI测温、肺炎筛查及病情预评估、口罩分类、口罩佩戴识别、自动配送等人工智能领域,助力疫情防控。
百度正在牵头制定数据标注的地方标准,进一步标准化省内各项数据服务业务,提高山西在全国范围内的影响力。2020年6月,百度智能云与山西政府达成进一步合作,双方将共同打造山西综改示范区AI数据交易平台,加速推进数据经济的落地,与当地政府共同打造有山西特色的数字经济新高地。
面对AI数据服务行业新的发展契机,百度智能云数据众包未来将继续夯实标注基地的服务能力,实现数据资产化,商业化,并与更多合作伙伴进一步盘活数据资产,带动当地产业智能化转型,产生更大的社会价值。
新基建给人工智能产业相关领域的发展带来了前所未有的机遇,提前布局且有着完善生态建设的百度智能云不仅带动了AI数据服务行业的高质量发展,更积极履行了企业的社会责任,为各行各业智能化转型提供动能,加速智能经济到来。
原文链接地址: https://developer.baidu.com/topic/show/290903
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
作者 | 不瞋 阿里云高级技术专家
每隔几年,IT 界就会出现新突破性的进展。回望整个计算机技术发展史,我们会发现“抽象、解耦、集成”的主题贯穿其中。产业每一次的抽象、解耦、集成,都将创新推向新的高度,也催生出庞大的市场和新的商业模式。
对于大多数应用而言,借助 Serverless 服务,开发者可以将绝大多数精力投入在业务逻辑的开发整合上,大大缩短开发周期,降低运维成本。有人说:Serverless 正在改变未来软件开发的模式和流程,它就是云计算的未来。技术领域真正的变革看似是新技术的高歌猛进,为客户创造价值才是任何技术变革的原点。本文将从客户价值的角度,再一次探讨为什么说 Serverless 是云的未来。
Serverless 对客户的价值
为客户创造价值是任何技术变革的原点,从客户价值倒推,真正需要回答的是:客户的痛点是什么?Serverless 在解决客户痛点上是否有明显优势?甚至为客户创造新的机会?以企业的平台化策略为例,为什么众多 SaaS 企业不能像 Salesforce 一样实施平台策略,打造 PaaS 或者 Serverless 计算平台?甚至做 PaaS,做中台变成了企业生死劫?这其中固然有业务、组织的顶层设计原因,但不可否认,打造平台的难度和成本太高也是其中很重要的原因。一方面要支撑前台业务的高速发展,另一方面又要抽象、重组,对系统进行重构。因此需要有新的方法论和工具来降低平台构建的成本,实现快速迭代演进。
从更宏观的视角来看,企业交付价值的方式,正在被数字技术重塑。根据阿里研究院的报告,在零售、金融等行业,数字化的商业形态正在代替传统商业形态,成为主流和必然。即使在工业制造等领域,企业的商业形态并非通过数字化的形式表现,但充分利用数据科技进行生产运营优化,也正在成为行业共识。在数字化转型的时代 ,企业面临巨大的竞争压力和不确定性,产品 time-to-market 的能力比任何时候都重要。根据微软的估计,未来 5 年会产生 5 亿个应用,比过去 40 年的总和都多,现有的研发模式已无法支撑这样规模的应用开发需求。
Serverless 计算的思想是将同质化的、负担繁重的基于服务器等基础设施的开发和运维等工作从未来云上应用开发中移除,借助云上丰富的托管服务能力,以搭积木的方式构建弹性、可靠、低成本的系统或应用。除此之外,云服务商也通过事件驱动的方式加强产品集成和被集成的能力。
以 Serverless 的核心计算产品函数计算为例,在函数计算出现之前,客户要通过很多胶水代码完成多个云产品间的集成,还要仔细的处理各种错误情况。当函数计算和阿里云对象存储集成后,对象存储中产生的上传 / 删除对象等事件能够自动、可靠地触发函数处理,而且每个环节都是弹性高可用的,客户能够快速实现大规模数据的实时并行处理。同样的,通过消息中间件和函数计算的集成,客户可以快速实现大规模消息的实时处理。在未来,无论是一方云服务,还是三方应用,所有的事件都将被捕获,被函数计算等服务可靠地处理。
对比传统开发模式,Serverless 模式基于大量成熟的云服务能力构建应用,客户的技术决策点更少,实施复杂度更低。随着云产品的完善,产品的集成和被集成能力的加强,软件交付流程自动化能力的提高,我们相信在 Serverless 架构下,企业的敏捷性有 10 倍提升的潜力。
Serverless 对云服务商的价值
Serverless 有助于云服务商建立更宽广的差异化竞争优势。基础设施即服务(IaaS )层的竞争本质是规模。云服务商通过提升供应链的议价能力、资源并池、采用异构硬件、软硬协同优化等手段来最大化性能功耗比(performance per watt)和性能价格比(performance per dollar)。基础设施层竞争的主要形式是价格战。
但云的竞争一定不是单一维度的,正如苹果提供了移动应用编程模型最好的实现,这是硬件、软件、服务三位一体的协同整合能力,以此为基础形成的出色用户体验和粘性让其在移动互联网产业中独树一帜。云服务商也需要思考如何在基础设施、产品体系、生态等方面多维度,立体化地打造竞争力。发展 Serverless 关乎于产品体系差异化竞争力的建设,对云服务商至关重要。
在函数计算出现之前,各个云产品难于支持定制化需求,产品间的交集很少。在函数计算出现后,每个云服务具备了“可编程“的能力。“可编程“让云服务将自己的核心能力延伸出去,让开发者基于此编写相关应用,不但解决了定制化需求支撑的问题,云服务还升级为应用平台,建立开发者生态。因此领先的云服务商的产品体系都在迅速 Serverless 化,不断加强产品间的集成和被集成的能力。
Serverless 有助于云服务商提高资源利用率,加速硬件创新。为了实现精准、实时的实例伸缩和放置,Serverless 计算平台必须把应用负载特征作为资源调度的依据,系统通常要实时追踪请求执行时长,排队等待时长,单位时间请求数,应用初始化时长等指标。以感知应用负载为基础的“白盒“调度,能够实现更出色的伸缩实时性和全局资源利用率。轻量安全容器等新的虚拟化技术实现了更小的资源隔离粒度(典型的 Serverless 计算服务通常支持 0.1 vcpu,128 MB 的实例规格),更快的启动速度,更小的系统开销,数据中心的资源使用变得更加细粒度和动态,能够更充分的利用碎片化资源。在加速硬件创新方面,Serverless 计算屏蔽了底层硬件规格,能够复用多种机型,加速新硬件的大规模应用。
Serverless 有助于云服务商形成良好的用户结构。Serverless 的核心价值是技术普惠。通过平台的整合和集成,用户以更有效率的方式构建弹性、高可用、低成本的云原生应用。赋能用户加速价值交付,实现业务突破,这对中小用户尤为重要。用户在云的环境中茁壮成长,是云最重要的价值体现。
至此,通过对产业发展趋势,以及 Serverless 对用户和云服务商的价值分析,我们可以形成如下结论: API 是构建现代应用的基石,这不只是技术决策,更影响企业业务发展策略。当一个垂直领域足够复杂后,会出现对应的后端服务(BaaS),通过 API 的方式交付价值。绝大多数 API 是 Serverless 形态,需要与之匹配的计算形态,这是 Serverless 计算诞生和发展的基础; 云的产品体系正在全托管化、Serverless 化,这不是对未来的期望,而是正在发生的事实。今天超过 70% 的云服务已经是 Serverless 形态,未来这一比例将会更高; Serverless 不等于 Serverless 计算,不是某一类云产品,而是对应云的整个产品体系,包含计算、存储、中间价、数据分析等各种服务。Serverless 定义了云的编程模型; Serverless 的本质是回答如何利用云的要素帮助用户实现价值交付的颠覆式创新。用户的价值交付涵盖方法论、开发者工具、应用交付体系、云产品体系、服务生态、商业模式设计等多个维度,因此 Serverless 必须是顶层设计的产物。
在 Cloud 1.0 时代,云托管模式简化了计算资源获取和管理的方式;在 Cloud 2.0 时代,Serverless 将成为云的新一代编程模型。编写代码,上传云端,在任何规模下可靠运行,成为新一代开发者感知云的第一界面,这是 Serverless 的初心。
体验有礼:5 分钟极速上手 Serverless
“Serverless” 近年来非常火爆。人人都热衷于探讨它出现的意义,但对于如何上手使用或在生产环境落地,却谈之甚少。我们设计了体验场景,手把手带你 5 分钟上手 Serverless,还送 2000 个阿里云“第一行代码”鎏金限量马克杯!
推荐 PC 端体验 : https://developer.aliyun.com/adc/series/fc/ “ 阿里巴巴云原生 关注微服务、Serverless、容器、Service Mesh 等技术领域、聚焦云原生流行技术趋势、云原生大规模的落地实践,做最懂云原生开发者的公众号。”
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
随着 95 后、 00 后为主的年轻一代逐渐成为中国移动社交下的主力军,社交需求也发生了一些变化。这些年轻用户更倾向于有趣好玩,形式多样化的社交方式。同时也产生了如 “ 扩列 ” 、 “ 养火花 ” 等众多新兴词汇。音频、视频、图文、短视频等丰富的技术能力则进一步拓宽社交场景。
iiMedia Research( 艾媒咨询 ) 数据显示, 2019 年中国移动社交用户规模达 8.62 亿,预计到 2020 年用户规模突破 9 亿。艾媒咨询分析师认为,庞大的移动社交用户规模也意味着更多的市场可能性。
目前头部的陌生人社交平台已拥有丰富的资源和强大的壁垒,但同时也逐渐暴露出好友质量越来越低、信息冗杂等问题。
在头部社交平台遇到创新难的当下,新入局者则瞄准了垂直社交领域快速抢占细分赛道,加入趣味性、潮流化的社交元素,融合更多的泛娱乐内容、玩法,寻求新的流量增长点。
网易云信与超级热门的虚拟社交 - 崽崽 ZEPETO 和国内知名的陌生人社交 -Uki 达成合作,帮助平台搭建【即时通讯】模块,实现多元化的的私密聊天、群聊等功能,通过云信提供的技术能力,两个平台不断迭代创新社交玩法,高效完成了人与人之间高粘性的连接,提升了社交产品的趣味性以及用户体验。
崽崽 ZEPETO- 火爆虚拟社交产品,云信助力玩家互动!
ZEPETO 是一款很流行的捏脸软件,早在 2018 年 11 月上线时就刷屏整个网络,是 2018 年 11 月全球 app store 的霸榜应用,随后在 2019 年 2 月, ZEPETO 发布了本地化的中国版本, “ 崽崽 ZEPETO” 。
崽崽 ZEPETO 以创建属于自己的 3D 卡通人物形象为切入点,用户则将自主创造的 3D 虚拟形象融入现实场景,和小伙伴、陌生人等实现社交互动。新鲜有趣的体验模式迅速吸引大量玩家进入。
崽崽 ZEPETO 魔性之处就在于,它利用摄像头生成和用户本人十分相似的形象,这个卡通人物还能做各种动作。作为一款虚拟社交产品,自然少不了社交功能。用户可为自己设定昵称,添加好友或被人添加,添加成功后,就可以开始聊天了,聊天场景中就连表情包都是用户的 3D 形象所生成的。不仅如此, 3D 形象还有更多玩法,例如当用户做好 3D 形象后,可生成相关照片,单人拍照或和好友合照。当然有更多姿势和道具等着用户解锁,比如单人可以和布偶拍照,双人就可以摆出各种情侣 Pose 等,而这些照片还能进一步扩展到微信群、贴吧、微博等平台实现进一步的社交和互动,形成了延伸到平台外的社交狂欢,由此逐步培养起玩家对虚拟社区的归属感及认同感。
用户虚拟社交的互动需求让崽崽 ZEPETO 不断升级优化,专门辟出了 “ 发现 ” 和 “ 世界 ” 两个版块, “ 穿搭 PK” , “Party Game” , “ 热力榜 ” ,应有尽有满足用户的社交需求。玩家在崽崽世界里畅游,结识更多好友,拥有新的粉丝,和新朋友在崽崽世界里一起玩耍。从恐怖教室到带有各种游乐设施的主题公园和水上乐园,在主题多样的崽崽世界里遇见新朋友。
以上的社交互动场景背后采用了网易云信的 IM 即时通讯能力,点对点单聊和群聊两个能力为崽崽 ZEPETO 打造更专业的社交沟通场景。
通过网易云信提供点对点单聊功能,在崽崽 ZEPETO 上的用户可以在添加好友后,与其进行私聊,支持的消息类型十分丰富包括文字、图片、语音、视频消息等,让沟通毫无障碍。另外,用户在关注好友后,还能发起邀请创建多人群聊,开启趣味游戏,一起互动、讨论,以此增加用户之间沟通的即时性、互动性和有效性,加深虚拟世界的真实趣味性。
据统计,崽崽 ZEPETO 在全球累积注册用户达 1.7 亿 + ,用户日均使用时长达 40min ,用户以女性为主,从小学生到白领都有,年龄分布广泛。在 Appstore 多国家地区榜单第一, 2018 年末曾持续霸榜 Appstore 多次专题、应用推荐,是当代年轻人最喜爱的 APP 之一。
Uki- 深受 95 后群体喜爱的社交产品,云信为其提供多元化沟通渠道!
Uki APP 是一款由上海牛咖信息科技有限公司开发,深受 95 后群体喜爱的社交产品,用户可在 Uki 上记录生活,寻找爱情友情,同时创作音乐、摄影等优质内容。
Uki 产品界面整体设计简洁明了,十分符合年轻一代的喜好。首次注册 Uki 时,用户可以打造个人专属形象,长发 or 短发?大眼睛 or 小眼睛?森系清新 or 性感时髦?都由用户做主!进入产品首页后映入眼帘的便是平台根据双方兴趣爱好匹配推荐的在线 U 友,互相关注后还能解锁语音通话、发图片等能力。除此之外,还有好玩的声控交友,用声音认识新的朋友,喜欢谁的声音用接唱开启对话,越玩越会爱上陌 “ 声 ” 人。
既然是陌生人社交,通过私聊和陌生人搭上话需要技巧,否则容易陷入尬聊。但通过平台中的热门派对,进入多人群聊,还能加入众多家族中,即便是对于不爱好发言的人来讲,也会时不时的爬楼看看别人说了什么。
还有动态广场让每一位用户真实地展示释放自我,让每一次分享都有人回应,每一次自我表达都有人懂。
此外 Uki 官方一直积极履行社会责任。今年 3 月 5 日和 6 日晚, Uki 官方联合 16 名金牌主持人发起两场主题为 " 同心战役,加油武汉! " 公益派对。此次派对所得全部捐献给湖北省慈善总会 " 疫情防控关爱计划 " 项目,用于慰问基层一线从事防控工作的人员。
今年 6 月 8 日至 17 日期间则举行了上海信息消费节之 Uki 消费狂欢季活动。把握拉动消费和履行社会责任两条主线。一是用优惠让利用户。活动期间,用户购买全场虚拟 3D 服装,享受 8 折优惠。二是用正能量影响年轻人。 Uki 邀请了专业心理咨询师,为用户带来 10 场心理咨询派对。针对疫情等社会热点,帮助 95 后培养积极的心态,树立正确的人生观和价值观。
Uki 结合自身在线网络视听平台的优势及特点,通过举办线上活动,不断为社会为用户传播正能量。
为有效连接 Uki 的用户与用户之间的交流,提供有趣好玩的互动渠道, Uki 接入了即时通讯模块,实现 U 友在线私聊,热门派对群聊功能,做到用户体验无缝对接。
【灵活好用的私聊功能】
在 Uki 的用户沟通场景中,云信单聊的使用十分灵活。用户进入首页后映入眼帘的便是平台根据虚拟头像的特征、用户填写的兴趣爱好、交友偏好和层次属性展示了大概率可产生共鸣的 U 友,同时在热门派对和动态广场上,用户如对任何 U 友感兴趣,都可进一步私聊。
同时云信的点对点聊天,支持的消息类型十分丰富,包含文字、图片、语音、地理位置、文件、通知、提示、自定义消息等。另外值得一提的是,当用户遇到心仪的 U 友后,想迅速得到对方的回复时,网易云信运用两个解决方案让沟通更及时:一方面运用在线状态订阅能力,用户之间可互相观察对方在线状态时发送消息,以此双方交流效率得到大大提升;另一方面运用推送功能,双方在平台上发出的消息能够通过推送能力在彼此手机上提醒,保障了 IM 消息的送达率,网易云信 IM SDK 从 3.2.0 起引进第三方消息推送来增加消息送达率,目前已支持的第三方推送有谷歌 FCM 推送、小米推送、华为推送、 OPPO 推送、 VIVO 推送、魅族推送。
左: U 友单聊列表界面,展示在线状态,右:单聊界面
【拒绝尬聊从群聊开始】
网易云信的群聊功能,主要应用于 Uki 的热门派对场景,派对模块有相亲,拍卖,心动(相亲),点唱,游戏陪玩,电台多个环节。平台根据不同话题划分了派对房间,用户根据自身感兴趣的话题参与到派对房间内与志趣相投小伙伴一起燥起来。
对此网易云信提供的是普通群的群聊形式。普通群类似当前 IM 聊天应用内的讨论组或快速多人会话,适用于快速创建多人会话的场景。
热门派对中的多人聊天
以 95 后、 00 后为代表的年轻群体在移动社交领域较为活跃,这部分人群也呈现出更多元的社交需求,热衷探索更具趣味性、和潮流化的社交方式。在新需求不断涌现的社交新时代, Uki 和网易云信也将一起探索更多泛娱乐玩法,满足用户不断更新的社交需求,力求实现功能和玩法创新的社交产品。
崽崽 ZEPETO 和 Uki 这样有趣,玩法多样,符合潮流的社交产品,让每一个玩家都能在自己喜爱的产品中释放自我,结实新朋友。未来,网易云信将继续赋能社交客户,助其用技术打造多元化沟通场景,让社交产品拥有更多有趣的新玩法!
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
很多时候我们都希望首屏速度快,SEO 友好,那么相比于客户端渲染,SSR 渲染将是这方面的优势。Next.js、Nuxt.js 都是 SSR 框架。本篇文章将介绍 Next.js。
通常我们在部署 SSR 的时候,会担心运维等问题,但如果我们把它部署在云开发上就可以不必担心~
试试看看喽~
环境准备 安装 node.js 安装云开发工具 @cloudbase/cli npm i @cloudbase/cli
搭建云环境 首先在打开 云开发 并新建环境 创建完成后会自动进入环境初始化阶段,这个阶段大概持续 2~3 分钟。
初始化项目
当环境初始化完成后我们就可以进行初始化项目啦~ 使用 CLI 工具初始化一个云开发项目 $ tcb init tcb init ? 选择关联环境 xxx - [xxx-xxx] ? 请输入项目名称 nextSSR ? 选择模板语言 Node ? 选择云开发模板 Hello World ✔ 创建项目 cloudbase-next 成功!
初始化结束后的项目目录如下: nextSSR └─. │ .editorconfig │ .gitignorev1 │ a.txt │ cloudbaserc.js │ README.md │ └─functions └─app index.js
然后我们进入到项目中 $ cd nextSSR
在 functions 文件夹下创建 next.js 应用: $ npm init next-app functions/next
等待初始化 next.js 项目...
初始化完成后在 functions 文件夹下会多出一个 next 的文件夹,这个便是我们的 next 应用
配置 next 首先我们进入到 next 项目的根目录 $ cd functions/next 然后安装 severless-http $ npm install --save serverless-http 在 next 应用的根目录下 项目根目录/functions/next应用根目录 新建 index.js ,并将下列代码添加进去 // index.js const next = require('next') const serverless = require('serverless-http') const app = next({ dev: false }) const handle = app.getRequestHandler() exports.main = async function(...args) { await app.prepare() return serverless((req, res) => { handle(req, res) })(...args) }// next.config.js module.exports = { assetPrefix: '/next' }
在 next 应用的根目录 (/function/next/ next.config.js ) 中新建 next.config.js 并将下列代码拷入 // next.config.js module.exports = { assetPrefix: '/next' }
这样我们的项目就配置差不多了。
项目的构建与发布 首先我们进入到 functions/next 目录中
执行 $ npm run build 然后回到项目根目录中,运行 cli 命令将代码上传到云函数 $ tcb functions:deploy next 然后我们创建一个 http 服务 $ cloudbase service:create -f next -p /next -f 表示 HTTP Service 路径绑定的云函数名称 \ -p 表示 Service Path,必须以 / 开头 $ cloudbase service:create -f next -p /next ✔ 云函数 HTTP service 创建成功!
我们上传到了哪里了呢?
我们进入到 云开发管理 页面
我们看到在云函数的函数代码中可以找到我们刚才上传的文件
我们点击预览即可浏览页面啦~
在函数配置可以通过触发云函数来进行浏览我们的页面
对比
我们通过对比查看 通过 SSR 渲染的页面加载速度
非 SSR 的加载速度
可以看到有明显的速度提升啦~
One More Thing
3 秒你能做什么?喝一口水,看一封邮件,还是 —— 部署一个完整的 Serverless 应用? 复制链接至 PC 浏览器访问: https://serverless.cloud.tencent.com/deploy/express
3 秒极速部署,立即体验史上最快的 Serverless HTTP 实战开发! 传送门: GitHub: github.com/serverless 官网: serverless.com
欢迎访问: Serverless 中文网 ,您可以在 最佳实践 里体验更多关于 Serverless 应用的开发! 推荐阅读: 《Serverless 架构:从原理、设计到项目实战》
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
Sentinel 是阿里巴巴开源的,面向分布式服务架构的流量控制组件,主要以流量为切入点,从限流、流量整形、熔断降级、系统自适应保护等多个维度来帮助开发者保障微服务的稳定性。Sentinel 承接了阿里巴巴近 10 年的双十一大促流量的核心场景,例如秒杀、冷启动、消息削峰填谷、集群流量控制、实时熔断下游不可用服务等,是保障微服务高可用的利器,原生支持 Java/Go/C++ 等多种语言,并且提供 Istio/Envoy/SOFA MOSN 全局流控支持来为 Service Mesh 提供高可用防护的能力。
近期, Sentinel Go 0.4.0 正式发布,带来了 热点参数流控特性 ,可以自动识别统计传入参数中的“热点”参数值并分别进行流控,对于防刷、热点商品访问频次控制等场景非常有用,是高可用流量防护中重要的一环。下面我们来了解一下热点参数流控的场景和原理。
热点流量防护介绍
流量是随机的,不可预测的。为了防止被大流量打垮,我们通常会对核心接口配置限流规则,但有的场景下配置普通的流控规则是不够的。我们来看这样一种场景——大促峰值的时候,总是会有不少“热点”商品,这些热点商品的瞬时访问量非常高。一般情况下,我们可以事先预测一波热点商品,并对这些商品信息进行缓存“预热”,以便在出现大量访问时可以快速返回而不会都打到 DB 上。但每次大促都会涌现出一些“黑马”商品,这些“黑马”商品是我们无法事先预测的,没有被预热。当这些“黑马”商品访问量激增时,大量的请求会击穿缓存,直接打到 DB 层,导致 DB 访问缓慢,挤占正常商品请求的资源池,最后可能会导致系统挂掉。这时候,利用 Sentinel 的热点参数流量控制能力,自动识别热点参数并控制每个热点值的访问 QPS 或并发量,可以有效地防止过“热”的参数访问挤占正常的调用资源。
再比如有的场景下我们希望限制每个用户调用某个 API 的频率,将 API 名称+userId 作为埋点资源名显然是不合适的。这时候我们可以在给 API 埋点的时候通过 WithArgs(xxx) 将 userId 作为参数传入到 API 埋点中,然后配置热点规则即可针对每个用户分别限制调用频率;同时,Sentinel 也支持针对某些具体值单独配置限流值,进行精细化流控。
热点参数埋点/规则示例: // 埋点示例 e, b := sentinel.Entry("my-api", sentinel.WithArgs(rand.Uint32()%3000, "sentinel", uuid.New().String())) // 规则示例 _, err = hotspot.LoadRules([]*hotspot.Rule{ { Resource: "my-api", MetricType: hotspot.QPS, // 请求量模式 ControlBehavior: hotspot.Reject, ParamIndex: 0, // 参数索引,0 即为第一个参数 Threshold: 50, // 针对每个热点参数值的阈值 BurstCount: 0, DurationInSec: 1, // 统计窗口时长,这里为 1s SpecificItems: map[hotspot.SpecificValue]int64{ // 支持针对某个具体值单独配置限流值,比如这里针对数值 9 限制请求量=0(不允许通过) {ValKind: hotspot.KindInt, ValStr: "9"}: 0, }, }, })
像其他规则一样,热点流控规则同样支持通过动态数据源进行动态配置。
Sentinel Go 提供的 RPC 框架整合模块(如 Dubbo、gRPC)均会自动将 RPC 调用的参数列表附带在埋点中,用户可以直接针对相应的参数位置配置热点流控规则。目前热点规则仅支持基本类型和字符串类型,后续社区会进一步进行完善,支持更多的类型。
Sentinel Go 的热点流量控制基于缓存淘汰机制+令牌桶机制实现。Sentinel 通过淘汰机制(如 LRU、LFU、ARC 策略等)来识别热点参数,通过令牌桶机制来控制每个热点参数的访问量。目前 0.4.0 版本采用 LRU 策略统计热点参数,在后续的版本中社区会引入更多的缓存淘汰机制来适配不同的场景。
高可用流量防护最佳实践
在服务提供方(Service Provider)的场景下,我们需要保护服务提供方不被流量洪峰打垮。我们通常根据服务提供方的服务能力进行流量控制,或针对特定的服务调用方进行限制。为了保护服务提供方不被激增的流量拖垮影响稳定性,我们可以结合前期的容量评估,通过 Sentinel 配置 QPS 模式的流控规则,当每秒的请求量超过设定的阈值时,会自动拒绝多余的请求。同时可以结合热点参数流控进行细粒度的流量防护。
在服务调用端(Service Consumer)的场景下,我们需要保护服务调用方不被不稳定的依赖服务拖垮。借助 Sentinel 的信号量隔离策略(并发数流控规则),限制某个服务调用的并发量,防止大量慢调用挤占正常请求的资源;同时,借助熔断降级规则,当异常比率或业务慢调用比例超过某个阈值后将调用自动熔断,直到一段时间过后再尝试恢复。熔断期间我们可以提供默认的处理逻辑(fallback),熔断期间的调用都会返回 fallback 的结果,而不会再去尝试本已非常不稳定的服务。需要注意的是,即使服务调用方引入了熔断降级机制,我们还是需要在 HTTP 或 RPC 客户端配置请求超时时间,来做一个兜底的保护。
在一些请求突刺的场景中,比如 MQ 客户端消费消息的场景,我们可能不希望将多余的消息直接拒绝(重投),而是让这些过量的消息排队逐步处理。这就是“削峰填谷”的场景。我们可以利用 Sentinel 流控规则中的“匀速+排队等待”控制效果来处理这种场景,以固定的间隔时间让请求通过,超出预设量的请求排队等待。这种方式适合用于请求以突刺状来到,这个时候我们不希望一下子把所有的请求都通过,这样可能会把系统压垮;同时我们也期待系统以稳定的速度,逐步处理这些请求,以起到“削峰填谷”的效果,而不是直接拒绝所有多余的请求。
同时 Sentinel Go 还提供 全局维度的系统自适应保护能力 ,结合系统的 Load、CPU 使用率以及服务的入口 QPS、响应时间和并发量等几个维度的监控指标,通过自适应的流控策略,让系统的入口流量和系统的负载达到一个平衡,让系统尽可能跑在最大吞吐量的同时保证系统整体的稳定性。系统规则可以作为整个服务的一个兜底防护策略,保障服务不挂。
Let's start hacking!
Sentinel Go 版本正在快速演进中,我们非常欢迎感兴趣的开发者参与贡献,一起来主导未来版本的演进。Sentinel Go 版本的演进离不开社区的贡献。若您有意愿参与贡献,欢迎联系我们加入 Sentinel 贡献小组一起成长(Sentinel 开源讨论钉钉群:30150716)。我们会定期给活跃贡献者寄送小礼品,核心贡献者可以提名为 committer,一起主导社区的演进。同时,也欢迎大家通过 AHAS Sentinel 控制台 来快速体验 Sentinel 的能力。Now let's start hacking! “ 阿里巴巴云原生 关注微服务、Serverless、容器、Service Mesh 等技术领域、聚焦云原生流行技术趋势、云原生大规模的落地实践,做最懂云原生开发者的技术圈。”
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
从奇点爆炸之后,宇宙的状态由初始的“一”分裂开来,从而有了不同的存在形式、运动状态等差异,物与物的位置差异度量称之为“空间”,位置的变化则由“时间”度量。
空间承载了人们的生活、工作、生产和经营。过往,空间只是客观存在,与空间中的人不产生任何交互,空间的价值也仅限于物理存在。而如今,整个泛建筑行业都在思考,如何将空间数据和人产生交互,让人们更好的驾驭空间,产生更多的价值。
盈嘉互联(北京)科技有限公司(以下简称:盈嘉互联)便是最早思考并实践如何充分发挥空间数据价值的科技公司。
他们打造了一款 PaaS 云平台,为空间领域的数据汇集、数字化管理等需求搭建行业通用的数据中台,赋能各行业的重资产企业、软件公司、解决方案提供商,快速开发并部署应用于智慧空间全寿期管理的各类应用。
不得不提的是,这款 PaaS 云平台,正在他们眼中稳定、中立且值得信赖的青云QingCloud 公有云上无限生长。
盈嘉BOS,智慧空间的翅膀
作为彼此成就的合作伙伴,盈嘉互联与青云QingCloud 有着非常相似的技术基因和技术追求。
盈嘉互联在最初寻找合作伙伴时,就被青云QingCloud 完全自主研发的核心云技术所吸引。
同样,在青云QingCloud 公有云上承载着的,也是他们团队自主研发的结晶——盈嘉BOS。
以往,任何一个空间的设计,建造到交付使用,中间所有环节在某种程度上是完全割裂的,在这些环节中产生的数据也基本上在工程结束后就失去了价值和意义,这对于空间领域来说是一种优秀经验的浪费。
有很多行业的企业也曾经想过构建一个数字化平台来实现对空间全生命周期数据、场景的数字化管理。然而,这样一个平台对他们来说门槛并不低。
盈嘉BOS 就是在这样的背景下诞生的,专注于解决智慧空间领域的数据管理与复用问题,以空间三维可视化为切入点,以空间为中心汇聚数字化企业的各种相关静态及动态实时数据(如传感器数据、事件数据、人的数据等),成为数据的入口和汇集地。
凭借这些专业细分的数据,能够为空间领域各个环节的工作提供客观依据。
此外,盈嘉BOS 还能够提供全社会快速和低成本共享的智慧空间数据,将现实世界的空间映射到虚拟世界,形成数字孪生,以新一代可视化建筑数据管理平台,解决建筑企业数字化进程中的工具多样化、数据碎片化、管理复杂化的问题,为空间拥有者插上智慧的翅膀。
多场景应用,数据价值最大化
盈嘉互联针对智慧空间的硬科技——BOS-智慧空间操作系统,可以与人工智能结合,将海量空间数据的价值发挥到极致。
目前盈嘉互联已拥有面向八个方向的成熟解决方案,涉及城市、园区、楼宇、资产管理、工地、市政、交付、装配式等领域。
通过三维数据解析、Web 可视化、工程全寿命期数据管理和文档管理等功能,为智慧空间行业提供专业级的工程应用开发工具,快速响应建筑设计、施工等环节复杂的业务场景需求。
智慧园区,是盈嘉互联多场景服务中的重要一环。尤其此次疫情的爆发,让很多园区发现了自身在管理上的短板和缺失,数据可视化的作用体现得尤为明显。
当然,数据可视化必须与数据相结合,帮助园区管理者实现思维模式的转变,而盈嘉互联所做的就是帮助园区更加科学的使用数据并依据算法做出最科学的决策。
基于盈嘉BOS 开发的“数字建筑物平台”,可以对既有建筑信息数据进行全面汇集、存储,形成实体建筑的数字孪生兄弟,对新建建筑提纯数据贯穿数字化交付,使其成为全生命周期都可以使用的数据,以此提高各部门管理资源的共享和利用,打破各部门信息孤岛,推动部门间信息共享与业务协同。
此次疫情期间,通过园区的数据管理,可以辅助园区决策制订关于疾病传播的紧急处理预案。
以数据和科学的算法为基础,查看园区分布信息以及准确及时的病源/病例传播、路径跟踪等信息,辅助决策临时紧急处置预案,第一时间控制病源传播。如此大规模的数据管理和数据分析,对于底层基础资源的需求也极高,得益于青云QingCloud 提供的可靠、灵活的公有云服务,盈嘉互联数字建筑物平台发挥出了巨大的功效,在多个园区同时需要信息共享协同时,依然保证了稳定、高效和安全。
盈嘉互联在智慧空间领域深耕多年,从底层出发,以园区基础设施信息为基础,运用 BIM+GIS+IoT 等技术,实现园区由粗放式管理向数字化、精细化管理的转型。
通过部署在青云QingCloud 公有云上的应用赋予园区自我“感知、认知、预知”的能力,让整个空间更加智慧化,产业布局更科学,从而创造更大的经济与社会价值。
目前大热的智慧城市建设,其实可以看成多个智慧园区管理的升维集合,盈嘉互联在这方面也颇有造诣。前段时间,盈嘉互联凭借着数字城市基础设施大数据平台,帮助佛山禅城从“2018~2019中国新型智慧城市建设与发展综合影响力评估”中脱颖而出,位列榜单前十位。
基于盈嘉互联的“BIM”(BuildingInformationModeling,建筑信息模型)应用技术,禅城建立了覆盖城区主要构筑物的信息模型,同时融合城市 GIS 数据(地理信息系统)、倾斜摄影数据等,让城市构筑物迈入数字世界,最终呈现“数字禅城”。
当然,这只是盈嘉互联多场景服务中比较贴近日常的两个,除此之外,盈嘉互联正利用数据驱动着泛建筑行业方方面面的数字化转型。
依托 BOS 系统,盈嘉互联已经为国家众多重大水电力及智慧城市项目服务,是中交集团、国家电投、首发集团等大型国有企业的合作伙伴。而在盈嘉互联这些大型项目背后,都有青云QingCloud 坚实的身影和不断支撑的力量。
随着 5G 的普及,真正的物联网时代即将到来。盈嘉BOS 作为物联网、人工智能、地理信息、金融保险、市民服务等切入建筑领域入口的功能越发明显,作为以数据驱动核心智慧场景与全新体验的连接器,盈嘉互联将与青云QingCloud 更加深入合作,以前瞻性的技术创新和卓越的产品服务能力,推动整个行业乃至社会向着全面数字化的实现前进。 本文为「数字化转型之案例分享」系列文章,该专题在持续更新中,欢迎大家保持关注👇
青云QingCloud 为天佑儿童医院构建一朵医疗混合云
智能家居巨头 Aqara 借助KubeSphere 打造物联网微服务平台
青云QingCloud联合爱壹得用科技为一线医护人员筑起防护长城
光格网络 SD-WAN,为米域共享办公空间创业者打造高品质网络体验
QingCloud 公有云助攻上海科瓴“医药协同”迎战疫情
SENSORO灵思安全服务智能抗“疫” 青云QingCloud 秒级响应支持 更多内容可以访问 www.qingcloud.com
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>> 本文来自 Serverless 社区用户「逸笙」投稿
由于云函数 SCF 本身是用 bootstrap.php 来调用我们的入口函数,默认为 index.main\_handler ,意思是调用 index.php 文件中的 main\_handler() ,所以很多地方写法要有改变。php 一般提供网页服务,所以我主要讲 API 网关 配合的云函数 SCF。
main_handler($event, $context)函数会传入2个参数,首先这2个参数是object,需要用->来访问子项,如 $event->{'headers'} ,不是很方便,我一般转换成数组: $event = json_decode(json_encode($event), true);
这样就比较方便了,如 $event['headers']['host'] 。
大家可以打印这两个参数看一眼里面有些什么。
我们可以从中获取到很多有用的东西,比如: $_GET = $event['queryString']; $_POST = $event['body']; $_COOKIE = $event['headers']['cookie'];
在云函数 SCF 中运行的 php 程序,因为浏览器是提交给 API 网关,不是提交给 SCF 的,这些超全局变量完全没有获取到东西,所以要这样来获取。
但我们发现, $event['body'] 与 $event['headers']['cookie'] 本身是一个长字符串,里面有好几个值,并且里面 url 编码了,这样不方便使用,所以做些小操作: $postbody = explode("&",$event['body']); foreach ($postbody as $postvalues) { $pos = strpos($postvalues,"="); $_POST[urldecode(substr($postvalues,0,$pos))]=urldecode(substr($postvalues,$pos+1)); } $cookiebody = explode("; ",$event['headers']['cookie']); foreach ($cookiebody as $cookievalues) { $pos = strpos($cookievalues,"="); $_COOKIE[urldecode(substr($cookievalues,0,$pos))]=urldecode(substr($cookievalues,$pos+1)); }
这样就方便使用了。
在云函数 SCF 中,全局变量目前有个坑,就是上次访问获取的全局变量在这次并不会清空,所以本次访问的时候,上次提交的值可能还在全局变量中,这个情况不管是 php 固有的超全局还是自己定义的,都有这个情况,所以使用前注意 unset。
用户提交过来的数据,除了 GET、POST、COOKIE,还有一种比较重要的就是路径了,比如这样一个 url: https://hostname/path/file.jpg?foo=bar,在 API 网关中,/path/file.jpg 会被放到 $event['path'] 中,但注意,如果通过 API 网关默认 url 访问,里面会含有 /functionname ,注意去除(以下代码将路径里起始的 '/' 也去除了): $function_name = $context['function_name']; $host_name = $event['headers']['host']; $serviceId = $event['requestContext']['serviceId']; if ( $serviceId === substr($host_name,0,strlen($serviceId)) ) { // using long url of API gateway // 使用API网关长链接时 $path = substr($event['path'], strlen('/' . $function_name . '/')); } else { // using custom domain // 使用自定义域名时 $path = substr($event['path'], strlen($event['requestContext']['path']=='/'?'/':$event['requestContext']['path'].'/')); }
取得用户提交的信息后,就可以自己处理了,过程不详谈,只是注意: SCF 是只读的,只有 /tmp/ 目录可读写,这个 tmp 目录并发实例间互不相通,实例结束后销毁。
处理完后,就要输出给浏览器了,注意,因为跟浏览器对话的是 API 网关, 在代码中直接 echo 的话,只会显示在运行日志中,浏览器完全看不到,
所以 我们需要在 main\_handler 中把需要显示的东西 return 给 API 网关。
这时,如果要返回一个网页,那 API 网关要勾选「集成响应」,SCF 这边要返回一个特定结构的数组,这样浏览器才会正常显示,不然浏览器就会只看到一堆字符串。 return [ 'isBase64Encoded' => false, 'statusCode' => 200, 'headers' => [ 'Content-Type' => 'text/html' ], 'body' => $html ];
其中 body 就是我们要返回的网页内容,是个字符串;
headers 是给浏览器辨认的,Location 或 Set-Cookie 要放在这里面;
statusCode 是状态码,可以在 Location 时为 302,也可以在某些时候 404;
isBase64Encoded 是 API 网关用的,告诉它,body 里面是否 base64 加密。
这样返回,浏览器就会显示一个 HTML 网页了。
但有些时候,我们想给一个文件给用户下载,这时候,就要用到 isBase64Encoded 了: $image_data = fread(fopen('logo.png', 'r'), filesize('logo.png')); return [ 'isBase64Encoded' => true, 'statusCode' => 200, 'headers' => [ 'Content-Type' => 'image/png' ], 'body' => base64_encode($image_data) ];
这样浏览器会直接得到一个 png 文件,有些浏览器弹出下载,有些自己就打开了。
上面代码已经提交到云函数 SCF 模板库: https://github.com/tencentyun/scf-demo-repo/tree/master/Php7.2-QRcodewithLogo ,不吝赐教!
One More Thing
3 秒你能做什么?喝一口水,看一封邮件,还是 —— 部署一个完整的 Serverless 应用? 复制链接至 PC 浏览器访问: https://serverless.cloud.tencent.com/deploy/express
3 秒极速部署,立即体验史上最快的 Serverless HTTP 实战开发! 传送门: GitHub: github.com/serverless 官网: serverless.com
欢迎访问: Serverless 中文网 ,您可以在 最佳实践 里体验更多关于 Serverless 应用的开发! 推荐阅读: 《Serverless 架构:从原理、设计到项目实战》
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
本文作者:y****n 智慧城市正进入全新的发展阶段,与AI、大数据、云计算等创新技术深度融合是显著的特征。 浙江易视通联信息科技有限公司(以下简称“易视通联”),是一家专业从事信息化建设、软件开发、物联网应用和云数据建设的高新企业。在智慧城市的建设中,依托不断的积累,易视通联在节能环保、新能源、城市基础设施等领域贡献着自己的力量。
特别是加入百度智能云生态体系,双方在智慧城市领域展开紧密合作后,易视通联更是步入发展快车道,业务增长迅速。在谈及与百度智能云的生态合作时,易视通联总经理俞驰表示:“我们的合作始于项目合作,高于项目合作,现在逐渐上升为战略层面的深度交流与配合。未来,这种良好的合作关系还将在新项目和新领域上得到深化。” 共建智慧城市 在具体项目中提升配合度
智慧城市是一个复杂的生态系统,需要借助智能化技术获得更透彻的感知以及更全面的互联互通能力。百度智能云过硬的AI、云计算、大数据能力,与易视通联在智慧城市建设中的丰富经验,都让双方早早开启了智慧城市上的合作。
2014年,易视通联就开始协助百度智能云在某市的各类项目的软件开发、工程实施、售后服务等工作,基于良好的合作基础,双方展开了更多深层次的合作。
在某城管智慧城市项目中,依托百度智能云的人工智能分析技术,双方共同开发了智慧城管管理平台,对社会治理、城管、环保等方面的问题进行自动抓拍、自动识别、自动推送至联动平台,然后自动核查处置结果,该项目提升了城市精细化管理水平。同时,易视通联还承担了后期运维与维保服务的任务。服务中,易视通联热线电话的拨通率90%以上,能做到30分钟内响应,4小时内到达现场,24小时内提出解决方案。
俞驰总结说:“在每一次合作中,我们不仅看到了对方的技术优势,还能更好地找到双方合作的契合点。双方优势的结合,加速了智慧城市中具体项目地落地。” 认清各自优势 打通“最后一公里” 城市现代化治理体系离不开科技的“硬核支撑”。 易视通联十分看好百度智能云的技术和对未来发展趋势的准确把握。百度智能云在搜索、人工智能等技术领域处于全球领先地位,还依靠AI技术优势、数据优势和生态优势,做到持续为新一代智能基础设施提供支撑。
俞驰补充说:“还有一点很重要,百度智能云拥有大量成熟的行业解决方案,足以应对大部分的客户需求。”
当然,在具体领域的落地上,百度智能云也需要依靠合作伙伴的力量。 同时,直接开展项目的落实推进、售后维护等工作,需要巨大的伙伴支撑。而这些点恰好是易视通联这样的本地企业能弥补的。
不难看出,双方优势的融合是关键,在加快推进项目进程的同时,能最大程度降低项目整体运营成本。 迈向智能新时代 前浪后浪一起冲 一个是AI技术领域的领导者,一个是智慧城市落地的最佳实践者,这样的组合必定会双赢。
通过与百度智能云的不断交流与磨合,易视通联自身的发展方向也有了清晰明确的规划。百度智能云也在合作中有所收获,加速了AI等智能化技术在智慧城市领域的落地。
对于加入百度智能云合作体系后的具体变化,俞驰总结说:“随着几个具体项目的落地和收尾,易视通联在业绩上实现了长足增长,公司规模也不断壮大。而且有了百度智能云的技术扶持和专业培训,我们的技术研发能力在增强。更加有前景的是,在百度智能云的技术支撑下,我们落地了不少创新性项目。”
智慧城市建设之路还长。在接下来的合作中,双方将利用人工智能、大数据和云计算等技术持续赋能公共安全、应急管理、智能交通、城市管理、智慧教育等场景,携手加速城市智能化建设步伐!
原文链接地址: https://developer.baidu.com/topic/show/290900
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
本文作者:y****n
边缘计算技术正在越来越多的行业场景中得以应用,视频行业就是其中一个典型。随着视频形态、商业模式日益丰富,边缘计算在视频行业的应用价值正愈发凸显。爱奇艺作为知名视频平台,已将边缘计算技术应用在视频业务上。
爱奇艺拓展多个赛道 ,除广为人知的长视频外,也在短视频随刻、点播、直播,游戏及多元垂直业务持续发力。爱奇艺副总裁余珂在接受采访时表示,“百度智能云边缘计算真正帮我们做到了提效、降本、提升用户体验,从而能更从容的应对视频业务的快速变化。” 新挑战亟待新技术
短视频、点播、直播的爆发拉开了视频行业的新序幕,对技术的升级迭代要求越来越高,由此也给视频服务商带来了巨大的挑战。
用户对视频播放流畅、直播无延迟等观看体验的要求越来越高,这就对视频服务商IT系统的计算、存储、网络能力提出了更大挑战,尤其是计算和网络层面。
爱奇艺从自建IDC转向云端来满足业务需求的过程中,与百度智能云一起尝试一些创新技术的探索应用,边缘计算便是其中之一。
边缘计算带来全方位改善
2019年9月,爱奇艺开始将CDN的调度能力下沉到边缘计算节点,由此也正式开启了和百度智能云在边缘计算领域的新尝试。经过国庆阅兵这一重大直播事件对边缘计算的稳定性、可靠性检验后,爱奇艺将直播、点播等场景的一系列操作都迁移到了离终端用户更近的边缘计算节点上。
这样一个简单的调整带来的改善是明显的,调度效率更高、成本还有显著下降。
据介绍,应用百度智能云边缘计算节点BEC后,视频流的上传、处理分发、加工均有不同程度的改观。据测算,上传速度较之前有30%以上的提升,成功率基本保持在99.99%。而分发到用户侧观看速度提升20%,用户体验层有25%的提升。成本方面,带宽成本节约最为显著,能达到20%-25%。
因为技术选择百度智能云
百度智能云在边缘计算方面不仅技术架构先进、产品功能丰富、资源覆盖广、产品体验好,而且与爱奇艺想发力的方向是一致的,比如百度智能云边缘计算技术充分考虑到了与5G、云原生等技术的融合,这让双方的合作十分顺畅。
未来,爱奇艺将会在边缘计算上进行更多尝试。爱奇艺将联合百度智能云做一些新的边缘计算应用场景开发,比如云游戏、互动视频等,希望能够把数据传输延迟和成本降到最低,把端的硬件要求做到最低,从而让每一个客户在任何设备和环境下都能享受到极致的视频体验。
事实上,不仅是爱奇艺,整个视频行业都在积极拥抱边缘计算。目前,很多视频行业的头部客户都在与百度智能云开展积极合作,并在实际业务中落地应用。
放眼未来,伴随5G技术的全面到来,边缘计算作为云计算的有力补充,重要性已经不言而喻。据Gartner预测,2021年将有40%的大型企业在项目中纳入边缘计算。而到2022年,边缘计算将成为所有数字业务的必要需求。
爱奇艺已经为视频行业开了一个好头,为行业树立了典范。而未来,百度智能云也将不断完善产品,在边缘云IaaS产品之上,孵化出更多PaaS、SaaS能力,更好地支撑企业应用落地边缘计算技术。
原文链接地址: https://developer.baidu.com/topic/show/290899
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
转载本文需注明出处:微信公众号EAWorld,违者必究。
前言:
不同企业,不同系统,不同应用在开发中所使用的技术栈都不尽相同,因此构建所用的编译工具以及应用部署所使用的应用服务器也有所不同。如何扩展支持各种工具与应用服务器部署也成为了DevOps支撑企业持续集成与持续部署落地的关键组成部分。
本文从普元DevOps平台基于Jenkins pipeline构建及部署任务的扩展设计提供一种DevOps构建及部署任务设计的思路及方法。
目录:
1.为什么在设计时要考虑如何扩展?
2.我们做了哪些扩展方面的设计。
3.扩展设计后续。
1.为什么在设计时要考虑如何扩展?
在了解普元DevOps任务扩展设计之前,再重复说明一下普元DevOps平台持续集成及持续部署基于Jenkins pipeline的任务编排模式。
持续部署任务与持续集成任务基本一样,将类似应用服务器的部署(如websphere应用部署)封装成一个独立的任务,只是部署在pipeline stage的groovy脚本中添加了ansible-playbook的调用。在构建任务以及发布流水线中,用户可以根据自己的需求进行任务的编排。平台会将编排的好的任务提交给Jenkins引擎执行。
普元DevOps平台将提供的原子任务分为五类:代码,工具,构建,部署,测试。
代码: 拉取代码,代码库打标签,代码库分支维护,代码库标签,代码库分支合并等。
工具: 脚本执行,数据库检查,数据库脚本执行,介质仓库同步,文件生成等。
构建: Maven构建,Npm构建,Gradle构建,Ant构建,Docker镜像构建等。
部署: 数据组件发布,Tomcat云主机部署,Springboot云主机部署,Weblogic应用部署,Websphere应用部署,EOS应用部署等。
测试: Checkmarx,SonarQube,JMeter,Robotframework,Findbugs等。
平台提供的五类原子任务合计已经超过70个,后续仍然会不断增加。
由此可知,若在设计之初不考虑原子任务的扩展创建,后续添加原子任务将是一件繁复的工作。
2.我们做了哪些扩展方面的设计
设计思路:
原子任 务扩展的关键点无非三点: 原子任务,任务的属性参数,任务的脚本实现。
我们使用sql添加原子任务以及原子任务的属性参数,后端提供原子任务以及任务属性查询接口,然后前端使用动态表单展示原子任务信息以及任务属性。用户编排任务后执行。平台会根据用户编排的任务流程组装配置整个jenkins任务的xml配置文件,然后提交给jenkins引擎生成对应的任务。
相关表设计:
任务模板表
表结构关键字段:
关键字段说明:
STAGE_HANDLER: 定义任务拦截器,可以对任务属性进行处理。
COMMON_STAGE_TPS: 任务公共属性模板,平台将一些任务属性定义为公共的模板供任务直接引用。
如在部署相关任务中都涉及介质信息相关属性,因此将介质信息定义为一个公共属性模板,在部署任务中通过该字段引用,这样就不需要在任务属性表中重复定义介质相关属性,后续对介质信息的相关字段扩展也会直接映射到所有关联了该模板的部署任务。
任 务模板属性表
表结构关键字段:
关键字段说明:
CONTROL_TYPE: 属性的表单类型,有以下几种类型textbox,dict,combobox,checkbox editor,类型不同对应的前端展示的表单控件不同。
VALUE_PROVIDER: 当表单类型为特定类型时,此字段定义数据来源。比如当表单类型为combobox时,此参数可以配置为api接口相关访问信息,将接口返回值作为下拉选项和值。
Maven构建任务属性示例:
MAVEN版本 :CONTROL_TYPE设置为dict,VALUE_PROVIDER值设置为{"type":"dictcombobox","dictTypeId":"DPS_CD_MAVEN_VERSION"},如果需要扩展额外的MAVEN版本支持,只需要在平台管理新增业务字典DPS_CD_MAVEN_VERSION的值即可。
JDK版本 :同MAVEN版本一样,也是采用了业务字典项,方便扩展多版本支持。
settings文件:CONTROL_TYPE设置为editor,VALUE_PROVIDER值设置为{"type":"xml"},这样在编辑器中会根据xml类型做高亮显示。
执行Junit测试:CONTROL_TYPE设置为checkbox。
其他需要用户输入的字符串参数大多使用textbox类型。
此任务中没有使用到的CONTROL_TYPE为combobox的类型在之前提到的公共属性模板介质信息中的介质仓库属性有使用,使用该类型时将VALUE_PROVIDER定义为api访问的相关信息如下:
组件实例运维表
表结构关键字段:
关键字段说明:
COMPONENT_TYPE: 组件类型,使用业务字典项DPS_PDM_COMPONENT_TYPE定义,通常将工程中最小可部署的单位定义成一个组件,如普元DevOps应用采用前后端分离的方式部署,这里定义3个组件,前端nginx-web组件,后端tomcat组件以及数据库mysql组件,在编排发布流水线时可以根据具体的部署任务关联对应的组件(如tomcat云主机部署任务关联DevOps后端的tomcat组件)。
OPERATE_NAME: 运维操作,定义组件实例的运维操作。部分部署任务(如Tomcat云主机部署等)执行成功后会根据组件及主机资源等配置信息生成组件实例,组件实例的运维操作通过该字段定义。
相对于任务及任务属性的动态表单设计,脚本的设计就相对简单了。只需要将实现具体功能的脚本文件根据既定的规则命名及存放到指定的目录即可。
3.扩展设计后续
在线任务扩展
当前这种任务扩展方式仅仅只是给开发人员提供了便利,但是用户仍然很难扩展自己的任务,因此后续会考虑将任务扩展的能力做成平台功能的一部分提供给用户使用。
任务定义 : 创建一个任务,如maven构建任务,对应的任务类型为构建(build)。
属性定义: 设计任务参数,如maven构建任务,构建依赖的jdk版本,构建所使用的pom文件路径等。同时配置参数对应的前端控件(如checkbox,select,password等),若使用select框则需要定义展示数据的来源,可以是api和业务字典等。
脚本编写: 提供在线IDE的能力,用户可以实时维护并编辑自己的脚本,保存后即可完成加载。以供后续测试使用。
任务测试: 可以配置任务的属性参数,选择对应的测试脚本。在执行测试前可以根据预知的正确结果定义校验步骤,如构建任务是不是生成了对应的文件,部署任务是不是启动了对应的端口,HTTP是否可以正常访问等。
任务发布: 可以对测试通过的任务进行发布,也可以对已经发布的任务进行下线维护。
环境隔离
在普元DevOps平台中jenkins作为构建部署引擎提供服务,对用户来说是无感知的,用户不需要知道应用在何处编译,也不需要知道编译工具的路径,用户只需要配置任务执行即可。jenkins引擎会根据用户的配置生成对应的任务。
我们在使用DevOps平台过程中也碰到了一些问题。
1. 应用构建依赖特定的环境编译。 如IOS应用等。因此我们添加了构建及部署任务可以选择指定的jenkins引擎以及绑定到指定节点执行的能力。
2. 扩展工具支持,扩展多版本支持不方便。 因为任务是随机调度的,所有的jenkins节点都得包含编译所需的工具,因此所有的jennkins节点都得安装对应的工具及版本。
3. 安全问题。 因为jenkins引擎是各个项目公用,且包含脚本执行的能力,存在误操作或被恶意破坏的可能(Use Groovy Sandbox配置开启后功能基本无法正常使用)。
针对问题2和3,我们思考了两种解决方案,都是基于容器进行环境隔离。
方案1: 每一个任务对应一个slave节点,slave节点进程运行在容器内部,根据任务自动创建,任务完成自动销毁。
优点: slave节点动态创建,动态销毁,节省资源。
缺点: slave节点使用的容器镜像,仍然需要包含任务所需的所有工具。会存在镜像过大的问题。
方案2: jenkins的管理节点和slave节点仍然运行在主机环境,只将任务具体stage中最终形成的执行命令使用容器运行,任务中执行命令的容器挂载同一个workspace空间。如stage git最终形成了一条命令git pull http://test.project.git。使用包含git工具的容器镜像运行这条命令将代码拉取到挂载的workspace中,stage maven生成的命令maven clean install则使用包含maven构建环境的容器镜像执行即可。
优点: 扩展工具只需要扩展新的镜像即可,非常方便。
缺点: 需要维护镜像与原子任务的关系。
写在最后
企业DevOps平台建设与落地不是一蹴而就的,DevOps平台本身亦是如此。只有在不断使用的过程中不断的优化演进,这样才能让DevOps平台愈发强大,以更好的支撑企业的IT建设。
关于作者 : 谷缜,现任普元高级研发工程师。曾参与神华灾备云平台项目,九江银行持续集成项目等,主要负责项目实施工作。开源技术爱好者,擅长云计算,容器,DevOps等相关领域技术。
关于EAWorld :微服务,DevOps,数据治理,移动架构原创技术分享。 长按二维码关注!
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
作者 | 孤弋 阿里云高级技术专家,负责 EDAS 的开发和用户体验优化工作。
前言
近年来,云原生、Kubernetes、微服务、SpringCloud 这些名词在技术圈内不绝于耳,数据显示,使用 SpringCloud 作为微服务的框架,同时选择 Kubernetes 作为应用与基础设施运维底座的团队越来越多,这二者的搭档基本上成为了业界的主流配搭。
为了顺应这一趋势,EDAS 也紧紧围绕这一典型场景,对它的开发、测试、部署、联调、线上运维等诸多环节中的开发者体验进行深度打磨,发布了全新的 3.0 版本。同时,针对如何在采用了 SpringCloud + Kubernetes 架构的应用上使用 EDAS,我们团队提供各个环节的最佳实践,供开发者参考。
本篇进入我们的第一章节:开发。
初始化项目
阿里巴巴从 2018 年开始开源了以原阿里集团中间件为主要能力、全方位对标 SpringCloud Netflix 的全家桶服务,也就是目前的 Spring Cloud Alibaba 项目( https://github.com/alibaba/spring-cloud-alibaba ),经过两年多的发展,这个项目受到了越来越多开发者的喜爱,目前的 star 数也达到了 14K。
不过对于开发者而言,选择变多的同时,往往也会伴随一些烦恼,比如:我们到底需要使用什么版本?如何选择依赖的服务?如何解决公共组件的冲突问题?为了解决这些问题,阿里云去年上线了一款项目初始化工具( http://start.aliyun.com ) ,如下图:
我们通过这个页面提供了一个生成 Java 应用(不只是 SpringCloud 应用)的白屏化工具,对于一个最简单的 Spring Cloud 应用,只有一项是您必须要选择的依赖,就是 Spring Cloud Alibaba 选项卡下的 Nacos Service Discovery 组件。选中之后,点击按钮组中橙色的 “生成” ,工具会根据所需的依赖自动生成一份可直接打包运行的 pom.xml 文件,同时将所有内容打成一个标准的 Java 项目工程包供您下载。
在本地跑起来
下载完生成的项目工程之后,对于常规 Spring Cloud 应用开发开发流程,下一步是需要去找一个(或本地搭建一个)注册中心(如:Nacos),这个过程往往是需要花费一定时间的。去年年底我们在阿里云的 IDE 插件 Cloud Toolkit 中开发了一个自动拉起/选择注册中心, 并将应用自动适配到所选择的注册中心的功能。界面如下图:
可以按照自身以及团队的需求,选择合适的注册中心,如:可以选择"Use Local Registry"(适合个人开发)、或选择"Join Custom Registry"(适合团队开发)、也选择云上的 Nacos 集群(和云上服务联调);选择好之后,按照正常流程再在 IDE 中启动您的应用程序,此时应用就会自动适配到所选择的注册中心中,无需再去搭建一个,完全免维护。 提前做一个预告,关于开发者联调这一块的能力我们将会有专门的章节来讲解 EDAS 中的端云互联的能力,您也可以去阿里云官方文档中搜索《端云互联简介》进行前期的了解。
结语及其后续
在本篇中,我们站在开发者的视角对于 项目初始化 和 本地启动 两个开发过程中的基本环节,分别推荐了两个工具,它们的功能并不限于文章中提到的部分,还有更多和更强大的能力等待着我们自己去挖掘,EDAS 团队也将会在开发者体验上持续深耕,如果您有什么建议欢迎在文章下边进行留言分享。
另外,此次分享的内容并没有关于 Kubernetes 有关的话题,因为这个分享是一个系列文章,本篇仅介绍上述两个场景,Kubernetes 等相关内容将在后续分享中逐步介绍,下一篇的内容是: 部署到云端 ,敬请期待。
课程推荐
为了更多开发者能够享受到 Serverless 带来的红利,这一次,我们集结了 10+ 位阿里巴巴 Serverless 领域技术专家,打造出最适合开发者入门的 Serverless 公开课,让你即学即用,轻松拥抱云计算的新范式——Serverless。
点击即可免费观看课程: https://developer.aliyun.com/learning/roadmap/serverless “ 阿里巴巴云原生 关注微服务、Serverless、容器、Service Mesh 等技术领域、聚焦云原生流行技术趋势、云原生大规模的落地实践,做最懂云原生开发者的公众号。”
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
本文作者:y****n
一场暴雨可能引发什么?交通堵塞、道路积水、排水系统瘫痪……?实际上,我们生活工作中最基础的能源——电力,受恶劣天气的影响却是巨大的。
遇到暴雨、狂风、冰雹等恶劣天气,电力抢修人员往往需要全员待命,“故障就是命令”,故障影响的是数万户居民的用电,造成巨大的经济损失。而为尽快恢复10千伏白安线供电,抢修人员紧急工作下也需要近8小时的持续奋战。
国网湖南省电力有限公司(以下简称“湖南电力”)担负着保障湖南省电力可靠供应的重大责任,其下辖市州供电公司14家,营业区面积占全省的96.20%,截至2017年末,拥有35千伏及以上变电容量1.18亿千伏安、线路6.62万公里。
为了让辖内居民享受到优质的供电服务,湖南电力积极创新技术变革,在新基建大潮下,湖南电力通过与百度智能云合作,借助百度地图落地关键基础设施。
电力瘫痪时,如何判断是哪些供电设备出了故障?又该如何精准定位?以往,抢修人员需要对一条或多条供电线进行排查,才能确定故障设备,然后紧急制定出电力修复方案。如今,百度地图提供的公共地图服务帮上了大忙。
目前,湖南省基于实时路况信息的地图外网服务已完成部署,实现了停电范围高精准定位,并由停电设备信息关联电网系统数据展示停电设备信息。百度地图成为湖南电力数字新基建的基础服务设施。
通过百度地图,用户信息、线路信息和设备信息三流合一呈现在地图上,形成“电网一张图”。
同时,百度地图还可基于拥堵情况进行路线选择与时间预测,并与客户、供电服务指挥系统数据保持一致,大幅提升抢修响应效率。百度地图还能够全面嵌入微信及任一方APP,实现客户自动保修时定位精准,实现自接单开始至抢修完成后的所有轨迹的展示。
在供电设备预警及极端天气应对方面,百度地图为湖南电力打造了对应场景的出行服务。基于百度地图,湖南全境电力核心设备信息实现可视化,设备信息、状态、重载率等数据都可以通过地图查看,起到设备预警功能;百度地图还能够呈现气象数据综合展示,结合百度地图及遥感数据,湖南电力的抢修人员能够更好做出应急指挥和设备规划。
百度地图具备基础地图服务、卫星影像、地形高程及三维数据、实时路况与导航、GPS轨迹回放服务等多种功能,为湖南电力服务创新提供了多种可能性。
以长沙市为例,基于百度地图,长沙市全境地图可以进行坐标转换、位置检索、桩号定位、等式到达圈、空间查询、路径规划等业务能力。
此外,基于百度地图,湖南电力还可以实现配网图层进行停电区域展示,可实现停电区域影响分析、配变可开放容量概况展示等拓展场景需求。
电力服务是保障经济高质量发展的重要一环。今年年初,湖南电力公布了湖南高质量发展2020年行动计划,将围绕打造坚强智能电网、建设数字新基建等方面发力,助推湖南高质量发展。
百度智能云与湖南电力的合作成为AI改变和提升传统基础设施的一大典型范例。通过地图提供基础设施服务,湖南电力的电力抢修业务提效升级,让千家万户享受到更优质的电力服务。
原文链接地址: https://developer.baidu.com/topic/show/290896
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
Kubernetes集群节点会使用/etc/hostname的机器名称或者DNS,最好在创建集群之前设置妥当域名和机器名。如果在集群设置之后修改节点名称,将会比较麻烦。尤其是如果需要修改第一个节点的名称,会出现创建key和token失败,集群中无法再加入master节点,就需要全部重建集群或者手工修改所有相关的配置文件的参数。
Kubernetes集群更换节点名称目前没有简单的方法,步骤如下: 删除pod 删除节点 清理etcd 创建token 重新加入集群
具体操作如下:
1、删除任务
对节点执行维护操作之前(例如:内核升级,硬件维护等),您可以使用 kubectl drain 安全驱逐节点上面所有的 pod 。安全驱逐的方式将会允许 pod 里面的容器遵循指定的 PodDisruptionBudgets 执行 优雅的中止 。
首先,需要确定希望移除的节点的名称。您可以通过下面命令列出集群里面所有的节点:
kubectl get nodes
接下来,告知 Kubernetes 移除节点:
kubectl drain < node name >
执行完成后,如果没有任何错误返回,您可以关闭节点(如果是在云平台上,可以删除支持该节点的虚拟机)。如果在维护操作期间想要将节点留在集群,那么您需要运行下面命令:
kubectl uncordon < node name >
然后,它将告知 Kubernetes 允许调度新的 pod 到该节点。 参考: 驱逐节点上的任务pod, https://www.cnblogs.com/weifeng1463/p/10359581.html
⚠️注意:如果未使用drain驱逐所有的待删除节点上的pod,即使node被删除,该pod将一直运行到节点服务重启为止。
2、删除节点
删除该节点: kubectl delete node podc01
然后问题仍然存在。经查,被删除节点的etcd服务地址仍然在集群中,而且不可访问,升级无法完成。 根据网上的kubeadm说明,使用kubeadm reset将会自动删除etcd的节点信息。 但是,kubeadm reset后,经查,被删除节点的etcd服务地址仍然在集群中,而且不可访问,升级无法完成。
3、手动删除etcd node
查看并手动删除 etcd node信息: alias etcdv3= "ETCDCTL_API=3 etcdctl --endpoints=https://[10.1.1.202]:2379 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/peer.crt --key=/etc/kubernetes/pki/etcd/peer.key" 因为etcd的命令较长,先用个别名简化一下。 将上面的10.1.1.202改为自己的可用master节点IP地址。 更多etcd使用指南,可参考: Kubernetes的etcd多节点扩容实战技巧 Kubernetes探秘-etcd节点和实例扩容 Kubernetes的etcd数据查看和迁移 Kubernetes探秘—etcd状态数据及其备份
然后,运行: #查看etcd集群的成员: etcdv3 member list #删除etcd集群的不可访问的成员: etcdv3 member remove XXXXXXXXXX #再次查看etcd集群的成员: etcdv3 member list kubernetes高可用集群升级的etcd错误
修改/etc/kubernetes下所有配置文件中的server地址为可用节点地址。
4、创建token
在当前的集群中新增节点: 第一步,重新创建certificate key和token: sudo kubeadm init phase upload-certs --upload-certs ### Got: # [upload-certs] Using certificate key: # 2ffe5bbf7d2e670d5bcfb03dac194e2f21eb9715f2099c5f8574e4ba7679ff78 # Add certificate-key for Multi Master Node. kubeadm token create --print-join-command --certificate-key 2ffe5bbf7d2e670d5bcfb03dac194e2f21eb9715f2099c5f8574e4ba7679ff78
5、重新加入集群 增加Worker节点: kubeadm join 192 .168 .199 .173 :6443 --token rlxvkn .2ine1loolri50tzt --discovery-token-ca-cert-hash sha256 :86e68de8febb844ab8f015f6af4526d78a980d9cdcf7863eebb05b17c24b9383 增加master节点: kubeadm join 192 .168 .199 .173 :6443 --token rlxvkn .2ine1loolri50tzt --discovery-token-ca-cert-hash sha256 :86e68de8febb844ab8f015f6af4526d78a980d9cdcf7863eebb05b17c24b9383 --control-plane --certificate-key 440 a880086e7e9cbbcebbd7924e6a9562d77ee8de7e0ec63511436f2467f7dde
查看新的节点列表: kubectl get node -o wide 如果服务没有起来,测试一下: 查看服务版本,kubectl version 查看集群信息,kubectl cluster-info 查看服务状态,sudo systemctl status kubelet 查看服务日志,journalctl -xefu kubelet
更多参考: Kubernetes 1.18.3高可用集群快速升级及扩容 kubernetes高可用集群升级的etcd错误 kubernetes on arm发展现状 Kubernetes for arm 1.18.0快速安装 基于树莓派(Raspberry Pi)部署Kubernetes集群 Docker for Arm on Linux 上手指南 Docker Desktop构建Multi-Arch的arm容器镜像 k3s-轻量容器集群,快速入门 MicroK8s与K3s的简单对比 MicroK8s-部署到Windows、macOS和Raspberry Pi 设置Kubernetes的Master节点运行应用pod 使用kubeadm部署高可用Kubernetes 1.17.0 Creating Highly Available clusters with kubeadm Kubernetes 1.17.0管理界面Dashboard 2
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>> 安全不是纸上谈兵,其本质在于攻守双方的实战对抗。随着5G、AI等新技术引领而来的新时代下,企业数字业务的安全性面临着前所未有的挑战。
攻防演练是检验企业安全体系建设的有效实践,在攻防实战的过程中,面对全开放的环境、海量的账号、不可控的终端,引发企业思考以下几点: 现有 各自割裂、以边界为中心的单点防御体系 ,难以有效应对大规模、高频、高级定向攻击? 攻防信息不对称 ,攻击方层层突破,无力应对0day攻击,稍有疏忽即可能失陷丢分? 攻击突破边界后,投入大量成本正面抗敌, 缺乏迷惑性的战术布防 ,未能有效诱捕攻击者情报,被动处置响应? 重防护、轻运营 ,难以对现有防御能力、应急处置能力的科学评估?缺少整体安全战术布控?
自适应安全架构
YUNDUN基于Gartner自适应安全架构理念,智能联动事前安全预防、事中事件监测与威胁检测、事后响应处置,将针对攻击事件的"应急响应"扩展至针对攻击事件全生命周期的" 持续动态响应 ",实现面向真实互联网各类安全风险的自适应及响应。
积极预防: 赋予安全系统自学习的能力,针对漏洞、内容、泄露、可用性实施多维监控,赋能威胁情报系统,从而构成威胁处理流程的闭环。
纵深防御: 建立全景防御机制,实现防御纵深,减少业务系统被攻击面,提升攻击门槛,确保安全体系面对威胁的及时响应、有效响应。
持续检测: 建立完善的风险识别及威胁告警机制,降低攻击事件发生时安全体系的"停摆时间",助力企业实现全网安全态势的可知、可见、可控。
调查响应 : 全网威胁情报辅助威胁研判,实现攻击事件发生后的可溯源、可分析,提供企业入侵认证和攻击来源分析,持续赋能攻防对抗策略的研究升级。
HW安全架构
YUNDUN基于近十年安全攻防实战经验,依托自适应安全架构,形成了针对实战演练备战阶段、预演阶段、实战阶段、战后复盘阶段的全场景整体安全攻防实战兵法, 有效应对红方攻击,并构建纵深防御体系提升安全防控能力。
HW工具包
HW工具包(基础平台)是HW安全运营中心的技术基础底座,包含安全专家、联合运营团队所需要的工具、软件、平台。基于YUNDUN自适应安全架构,依托基础平台更高效可行地实现事前安全预防、事中事件监测与威胁检测、事后响应处置。
基于YUNDUN云原生的统一安全运营与管理平台,实现资产自动化盘点、互联网攻击面测绘、云安全配置风险检查、合规风险评估、泄漏监测、日志审计与检索调查、安全编排与自动化响应及安全可视等能力,提供一站式、可视化、自动化的云上安全运营管理。
核心优势
依托YUNDUN十年线上线下实战经验积累,同时基于威胁情报、AI、零信任等新技术,依托盾眼实验室持续研究升级实战对抗策略,整合Web蜜网、业务级Web应用防火墙等HW利器,形成全面有效的HW实战方案,同时不以单产品交付为目标,以服务结果为导向, 构建7*24*365全时安全守候 。
HW利器-Web蜜网
Web蜜网是为数不多的一种能够在HW实战敌明我暗的场景下, 取得攻防主控权,主动与攻击者进行有效对抗的方式 。YUNDUN通过部署高仿真动态蜜网,构建欺骗式防御体系,迷惑并快速判定攻击者,保护真实目标系统。
YUNDUN蜜网系统诱敌深入后,联动智能云WAF有效捕获攻击者攻击路径和攻击手法,结合全网威胁情报、社工学方法进行精准溯源;同时利用攻击者漏洞对红方进行攻击反制,化被动为主动扭转攻防局面。
资产布防: 以攻击者视角,分析攻击路径,在可能成为突破口的区域布置蜜罐,全网蜜罐形成蜜网。
监测研判: 异常行为分析,判断攻击意图,由攻击欺骗诱捕大脑进行研判。
蜜网诱惑: 根据攻击欺骗诱捕大脑研判结果,对异常行为进行诱导,攻击转移,争取防护主动权。
告警处置 : 一旦诱导蜜罐被触碰,及时告警,联动处置,锁定攻击行为,进入蜜网,进行攻击观测和策略自学习。
描绘攻击画像: 收集采集的攻击行为和攻击者身份信息,汇总攻击者信息,描绘攻击者画像,上报裁判组获得更多得分。
定位溯源: 通过反制扫描、反制钓鱼定位攻击者,上报裁判组获得更多得分。
HW利器-W eb应用防火墙
WEB应用防火墙由自动机算法驱动,基于 语义分析引擎、规则引擎和机器学习引擎 三大部分,面向针对Web系统脆弱性造成的入侵行为进行检测和处置。自动机算法驱动引擎可灵活调配三大核心检测引擎对威胁进行检测,三大核心检测引擎极大程度地提升了漏洞检测的准确率和召回率,具有很强的抗干扰性;同时,风险决策模块和风险处置模块可以依据检测结果进行决策和处置,使整个威胁防御过程更灵活,更贴合用户需求。
同时,针对Webshell,该模块提供了专门的完全基于机器学习的检测引擎,以确保精确识别真正的Webshell。这种检测方式无需考虑Webshell源文件进行如何的变形及加密,亦无需考虑请求通信中是否含有特征,只要黑客攻击者尝试访问Webshell时,均可被识别。
HW保障-安全专家团队
网络攻防的本质还是人的对抗,HW实战演练更是如此,为解决企业成立初期安全人员缺乏的情况,YUNDUN集结专业安全专家和业务支撑团队,依托10年一线安服实战经验积累,为企业提供7*24小时的纵深防御、安全态势监察分析、威胁情报值守监控、蜜网攻击牵引、精准溯源等服务,并 确保HW实战演习中突发的安全事件的及时响应、有效响应 。同时依托YUNDUN盾演实验室,实现红蓝实战对抗内部预演,确保HW实战方案的可靠性。
" 始于合规,终于安全;始于信任,终于信赖 ",YUNDUN致力于通过HW实战演练,助力企业预查核心信息系统的安全问题和隐患,构建事前安全预防、事中事件监测与威胁检测、事后响应处置能力,切实提高安全防护意识和安全体系建设,有效应对和防治可能的网络安全事件。
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
随着云计算技术的不断成熟和功能的不断完善,我们会发现有也越来越多的地方开始不在使用笨重的台式机办公,更多的是转而使用小巧的 云终端 来替代主机的。云终端虽然体积小功耗低可直接挂在显示器后面而不占地方,但是总所周知它本身的配置并不是很高的,那么它又是如何可以替代传统PC办公的呢,它的工作原理又是怎样的呢?
首先它是如何工作的,云终端按架构分可分为ARM架构和X86架构两种,而不管是哪种架构和那个厂家生产的云终端,它的工作原理基本都是一样的,那就是通过协议连接服务器使用,即给云终端安装云桌面软件和连接协议,然后通过协议连接服务器上的虚拟机来进行上网办公。
第二如何管理和维护,既然云终端它是通过协议连接服务器使用的,那么有人就会问他的管理和维护是不是会比传统PC更复杂的,其实使用云终端后它的管理和维护比传统PC更简单的。云终端采用嵌入式芯片功耗更低,使用寿命更长,硬件故障后只需直接换下就可以继续使用,同时云终端本地不运行数据和计算,所以桌面数据的管理维护都可通过服务器来完成的。
第三该如何去选择,既然云终端的工作原理和管理维护跟传统PC都不一样,那么我们又该怎么去选择的。当前云终端厂家虽然有很多,但是并不是所有的云终端都是可以通用的,我们在选择的时候最好是可以选择与服务器和云桌面同一个品牌的。因为云终端是需要通过协议连接服务器使用的,如果品牌不一,可能就会导致不兼容等情况发生的。
虽然说云终端配置不高,但是它本身并进行数据的存储和计算,而是通过协议连接服务器一起使用,也正是因为这样所以云终端可以实现和传统PC一样进行上网办公。
来源禹龙云
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
作者 | 右京 阿里云交付专家
**导读:**云原生是什么?相信不同的人有不同的认识和解读。本文结合大家的各种讨论及项目实践经验,从交付的角度,分享阿里交付专家对云原生的理解,阐述如何构建云原生应用,云原生有哪些关键技术,以及关于云原生落地的思考。
前言
Internet 改变了人们生活、工作、学习和娱乐的方式。技术发展日新月异,云计算市场风起“云”涌,从最初的物理机到虚拟机(裸金属) ,再到容器(Container),而互联网架构也从集中式架构到分布式架构 ,再到云原生架构。如今 “云原生” 被企业和开发者奉为一种标准,并被认为是云计算的未来,让我想到一句话:“未来已来,只是分布不均”。
伴随着 “云原生” 技术(架构)越来越火,火得一塌糊涂,每个人对它的理解都各不相同,网上和阿里内部关于 Cloud Native 的相关文章和讨论也非常多。不过,我发现大家对于云原生的定义、理解及实践还处于探索阶段,还没有一个非常明确或者顶层设计的标准化定义。
最近参与了一个上云项目,里面用到很多云原生的技术,借此机会结合大家的各种讨论,以及项目中的实践,聊一下个人对于云原生的一些粗浅思考。
追本溯源
在正式讨论之前,我们不妨先来看看几位网红主播是怎么定义云原生的。
1. Pivotal 的定义
Pivotal 公司是敏捷开发领域的领导者(曾经 Google 也是其客户),出生名门(EMC、VMware等投资),是标准的富二代。它推出了 Pivotal Cloud Foundry(2011 ~ 2013 PAAS 界网红) 和 Spring 生态系列框架,也是云原生的先驱者和探路者(开山鼻祖)。云原生具体定义如下图:
Pivotal 公司的 Matt Stine 于 2013 年首次提出云原生(Cloud Native)的概念。2015 年,云原生推广时,Matt Stine 在《迁移到云原生架构》的小册子中定义了符合云原生架构的几个特征:12 因素应用、微服务架构、自敏捷架构、基于 API 协作、抗脆弱性。到了 2017 年,Matt Stine 改了口风,将云原生架构归纳为:模块化、可观测性、可部署性、可测试性、可处理性、可替换性等 6 大特征。而 Pivotal 最新官网对云原生概括为 4 个要点:DevOps、持续交付、微服务、容器。
2. CNCF 的定义
CNCF(Cloud Native Computing Foundation,云原生基金会)相信大家已经非常熟悉。它是由开源基础设施界的翘楚 Google、RedHat 等公司共同牵头发起的一个基金会组织,其目的非常明确,就是为了对抗当时大红大紫的 Docker 公司在容器圈一家独大的局面,具体情况(有很多故事)不在这边细说了。CNCF 通过 Kubernetes 项目在开源社区编排领域一骑绝尘,之后就扛起了云原生定义和推广的大旗,风光无限。云原生具体定义如下:
2015 年 CNCF 掺和进来,最初把云原生定义为:应用容器化、面向微服务、容器编排。到了 2018 年,CNCF 更新了云原生的定义,加入了声明式 API 和服务网格(2017 年社区新技术,和微服务并列,注意它不是微服务的升级版本),这些技术能够构建容错性好,易于管理和便于观察的松耦合系统。
3. 小结
随着云原生生态和边界不断的扩大,云原生自身的定义一直在变。不同的公司(Pivotal & CNCF)不同的人对它有不同的定义,同一家公司在不同的时间阶段定义也不一样。根据摩尔定律推断,未来对于云原生的定义还会不断变化。
针对两家公司对云原生的定义不一样的情况,不妨跳出技术界面,我尝试用组织和立场的角度来分析下两位网红提出者: Pivotal 定位于 PaaS 层端到端的解决方案及数字化转型,从文化、流程、方法论、蓝图规划、软件开发方式等,都有一套模式,主要用户是传统大中型企业 CIO,整体策略是自顶向下; CNCF 立足于整个云计算生态和技术创新、变革者,偏重于技术、工具链和底层基础设施,主要用户是开源社区的开发者、互联网及新兴企业,影响力可想而知,整体策略是自底向上。
结论:Pivotal 是 Cloud Native 概念和方法论的先行者, CNCF 是 Cloud Native 的最佳实践者。
目前,针对定义唯一让我感到困惑的是 Pivotal 提 “概念” 把容器技术放进来,CNCF 提 “技术” 把微服务概念放进来,难道这两项是目前互联网圈最 “火” 的,为了吸引大众眼球?欢迎大家在下面留言讨论。
我眼中的哈姆莱特(云原生)
1. 思维、概念
互联网从刚开始诞生发展,到现在的互联网思维、互联网+(即 Internet Native ),云计算从诞生到发展至今,需要云原生思维(即 Cloud Native),类比企业发展到一定阶段需要价值观思维(即 Values Native )。它们是一种抽象的思维模式,所以任何技术的变革和推广,一定是思想先行,随后才有具体的产品帮助落地。
上面讲了思维方式,再具象点,结合 Pivotal 和 CNCF 对云原生定义及基于我自己的理解: 云原生根据一套方法论(Pivotal)和技术体系(CNCF),在云上构建一套可运行的应用系统。该应用系统会打破传统的构建方式,充分利用“云”的原生能力,发挥出 “云” 的最大价值,使其具备原生特征,快速为业务赋能。
还是有点抽象,那要怎么理解这一段话,我简单列一下 4 个要点,即灵魂拷问: 充分利用 “云” 的能力,“云” 有什么能力? 云上应用打破传统构建方式,怎么构建? 应用具备云原生特征,有什么关键特征? 云原生技术体系,有什么关键技术?
2. “云”有什么能力?
云计算出现与虚拟化技术的发展与成熟密不可分。它是一种新兴的 IT 基础设施交付方式,通过虚拟化技术,对 IT 硬件资源与软件组件进行了标准化、抽象化和规模化,变成 “产品服务” 和 “账单”(pay as you go),某种意义上颠覆和重构了 IT 业界的供应链。具体提供的服务有 IaaS/PaaS/FaaS/DaaS 几种形态:
1)IaaS(Infrastructure as a Service)
即 “基础设施即服务”,一般指云计算所提供的计算、存储、网络、安全等基本最底层能力。
2)PaaS(Platform as a Service)
即 “平台即服务”,通常指基于云底层能力而构建的面向领域或场景的高层服务,如云数据库、云对象存储、中间件(缓存、消息队列、负载均衡、服务网格、容器平台等)、应用服务等。
3)Serverless
即“无服务器计算架构”,指用户无须购买或关注基础设施,即可运行应用程序,按需付费,弹性扩容,也是 PaaS 演进的一种“极端”形态。目前包含 2 种方式: 面向应用:1. 开发者只需提供函数,通过事件或 HTTP 请求触发实现相应的功能,代表有阿里云(函数计算),AWS(Lambda);2. 开发者只需提供业务应用,无须购买服务器资源,代表有 Google(cloud run),阿里云(Serverless application engine, SAE); 面向资源:载体是容器镜像,屏蔽环境差异,灵活性好,代表有阿里云(Serverless kubernetes),AWS (Fargate)。
4)DaaS(Data as a Service)
“即数据即服务”,拓展到上层应用,AI 与云服务的结合,产生了很多高价值的服务。比如大数据决策系统、语音\面部识别、深度学习、基于场景的语义理解。这也是未来 “云” 的核心竞争力。
随着开源和技术的不断发展,我们可以看到,云厂商提供的产品和能力越来越多,从物理机、虚拟机、容器,到中间件,再到 IT Serverless 架构,每一层都在逐步的被标准化,而且标准化层面越来越高(即附加值也越高),跟业务没有直接关系且相对通用的技术(比如服务网格)也被标准化并且下沉到基础设施。技术每被标准化一层,原本低效繁琐的工作就少一些。另外,应用层面提供 “人工智能” 等新兴技术,帮助企业降低探索成本,加快了新技术的验证和交付,真正赋能业务。
对应用户则可以像宜家一样通过搭积木的方式,选择自己合适的云产品,站在巨人的肩膀上,避免重复造轮,极大提高了软件与服务构建各环节的效率,加速了各类应用和架构的落地,而 “云” 端可以按需启用和随意扩展的弹性资源,能够为企业节省巨大成本。
3. 原生应用“怎么构建”?
上面提到了 “云” 有很强大的能力,云上应用该如何适应,那么相比传统应用,新应用从软件架构的设计,开发,构建,部署,交付,监控及运维等整个应用生命周期各环节都需要被重塑,我从 “问题” 的角度切入讲一下:
1)架构怎么设计
好的架构是演进而来的,不是设计出来的,空谈架构 “如何设计” 是没有意义的,架构演进的目的一定是解决某一类问题。我们不妨从 “问题” 的角度出发,来聊一下云原生架构如何设计,如下图:
为了解决单体架构 “复杂度问题”,使用微服务架构; 为了解决微服务间 “通讯异常问题”,使用治理框架 + 监控; 为了解决微服务架构下大量应用 “部署问题”,使用容器; 为了解决容器的 “编排和调度问题”,使用 Kubernetes; 为了解决微服务框架的 “侵入性问题”,使用 Service Mesh; 为了让 Service Mesh 有 “更好的底层支撑”,将 Service Mesh 运行在 k8s 上。
从单个微服务应用的角度看,自身的复杂度降低了,在 “强大底层系统” 支撑的情况下监控、治理、部署、调度功能齐全,已经符合云原生架构。但站在整个系统的角度看,复杂度并没有减少和消失,要实现 “强大底层系统” 付出的成本是非常昂贵(很强的架构和运维能力)的。另外,企业为了实现这些功能所使用的技术栈及中间件体系是封闭的,私有化严重,很难满足所有的业务需求(包括阿里也存在这种情况)。“为了解决项目整体复杂度,选择上云托管”,将底层系统的复杂度交给云厂商,让云提供保姆式服务,最终演变为无基础架构设计,通过 YAML 或 JSON 声明式代码,编排底层基础设施,中间件等资源,即应用要什么,云给我什么,企业最终会走向开放、标准的 “Cloud” 技术体系。
2)应用怎么交付
为了解决应用 “持续交付问题”,我们引入了 Devops。
Devops 理念大家应该比较熟悉了,我理解它是一系列价值观,原则,方法,实践及工具的集合,目的是实现快速交付价值且具有持续改进能力,其核心是用于打破研发和运维之间的隔阂、加快软件交付流程、提高软件质量。下面贴一张流水线工具平台,如下图:
平台包括:GitHub、Travis、Artifactory、Spinnaker、FIAAS、Kubernetes、Prometheus、Datadog、Sumologic 和 ELK 等组件。
那怎么样才能算真正落地和践行 DevOps ,满足灵魂拷问的几个问题: 方式:开发每次写完代码是否可以部署到测试、生产环境,不需要运维帮助? 工具:是否有成熟运维工具平台和监控体系供开发使用,轻松处理线上各种问题、故障和回滚? 文化:开发直接为线上⽤户的体验负责,不管是代码缺陷还是运维故障,自己变更自己背锅,是否有 owner 精神? 交付度量:在部署频率、变更前置时间、服务恢复时间、变更失败率等对应指标上能否满足业界要求?
DevOps 本质上是为运维服务的,运维通过使用新技术和开发一系列自动化工具,让开发更接近生产环境,负责开发和运维全部过程,保证了自由度和创新性。在监控、故障防控工具,功能开关的配合下,可以在保障用户体验和快速交付价值之间找到平衡点。
猜想:对于技术人来说,或许未来真的只会有业务解决方案和业务代码,更多更迫切的能力需求将会是如何利用好业界已有的丰富的技术产品和云厂商平台,在面对更加丰富多样且复杂的业务领域需求时,能够更加专注于寻求业界解决方案,以更好地将业务和技术连接起来。对于运维来说,云屏蔽了基础设施的复杂度,从而转向工具链开发的运维中台和规模化运维,重点关注成本、效率、稳定性,并为应用保驾护航向上发展。
4. 原生应用有什么 “关键特征”? 弹性伸缩性:根据业务负载自动伸缩,做到秒级扩缩容能力,灵活动态分配或释放资源,结合弹性计费策略,这是降低用户费用重要手段之一,对服务而言需要的关键技术点就是服务本身的 “轻量级容器化” 和以此为基础的 “不可变基础设施” 特征; 容错性:负载均衡,自动限流降级熔断,异常流量自动调度,故障隔离,宕机自动迁移等; 可观测性:丰富且细粒度的监控(实时指标、链路追踪、日志),秒级监控能力,做到自动化报警,可持久化的提供查询; 发布稳定性:为应对频繁变更带来的稳定性风险,需建立无人值守的变更发布系统,具备自动化的灰度、蓝绿等发布策略,同时建立变更前中后的监控基线,具备异常变更的熔断和自动化回滚能力; 易于管理:需要从人工运维到自动运维的转变,具备自动化异常分析诊断能力,无需登录服务器; 极致体验:包括应用分配/创建/资源申请/环境配置/开发测试/发布/监控报警/排障定位等需要做到通畅与简单,一站式体验,避免繁杂的搭积木式操作; 弹性计费:支持按量(如流量,存储量,调用次数,时长等),按天(固定的如年/月/日),预留式,抢占式等多种定价策略,业务可根据实际情况灵活动态切换匹配出一个最优计量模式。
5. 云原生有哪些“关键技术”?
1)容器
容器雏形最早出现在 1979 年叫 Chroot Jail ,定义于 2008 年 即 LXC(Linux Container),将 Cgroups 的资源管理能力和 Namespace 的视图隔离能力组合在一起,实现进程级别的隔离。然而容器最大的创新在于容器镜像(即集装箱,Docker “现象级” 开创),它包含了一个应用运行所需的完整环境(整个操作系统的文件系统),具有一致性、轻量级、可移植、语言无关等特性,实现 “一次发布,随处运行”(开发、测试、生产),使应用的构建、分发和交付完全标准化。它也是 “不可变基础设施” 的核心基础。
2)Kubernetes
Kubernetes 是云计算和云原生时代的 Linux。
Kubernetes 是 Google 基于 Borg 开源的容器编排调度系统,让容器应用进入大规模工业生产。
声明式的 API 与可扩展(CRD + Controller)的编程接口,先进的设计思想使其在容器编排大战中(Kubernetes、Swarm、Mesos)处于王者地位,成为容器编排系统的事实标准。
通过采用 Kubernetes 平台,用户不必操心资源管理问题,使基础设施更加标准化,复杂度降低,资源使用率提升。同时 Kubernetes 也简化了混合云,多云,边缘云等跨数据中心的部署成本。
3)ServiceMesh
ServiceMesh 核心是业务逻辑与非业务逻辑解耦,实现开发只需关注业务逻辑的伟大目标。将一大堆和业务逻辑无关的客户端 SDK(如服务发现,路由,负载均衡,限流降级等)从业务应用中剥离出来,放到单独的 Proxy(Sidecar) 进程中,之后下沉到基础设施中间件 Mesh(类似 TDDL 到 DRDS 的模式)。针对应用减少了系统框架变更带来的风险、瘦身后变的干净和轻量化,加快了应用的启动速度,使得应用往 Serverless 架构迁移变得轻松。针对 Mesh 可以根据自身需求自行迭代和升级功能,更加利于全局服务治理、灰度发布、监控等。同时,Mesh 边界可以扩展到 DB Mesh,Cache Mesh、Msg Mesh等,真正做到服务通信的标准化即服务之间通信的 TCP/IP。
4)基础设施即代码(IaC)
将基础设施及其完整的生命周期(创建、销毁、扩容、替换)以代码的方式进行描述、通过相应的工具(terraform、ROS、CloudFormation等)编排执行和管理。比如应用用到的所有基础资源(如:ECS、VPC、RDS、SLB、Redis 等),无需在控制台不停的切换页面申请购买,只需定义相应代码,一键创建。这样做的受益是基础设施代码版本化,可 Review,可测试,可追溯,可回滚,一致性、防止配置漂移,方便共享、模板化和规模化,提升了运维整体效率和质量,通过代码也可以轻松了解基础设施的全貌。
5)Cloud IDE
云端 IDE 深入研发的整个生命周期,提供了完整的开发、调试、预发、生产环境及CI/CD 发布一体化体验。云端可提供丰富的代码库模板,通过分布式运算提升编译速度,以 “智能” 方式实现代码推荐、代码优化、自动扫描发现 BUG、识别逻辑和系统性风险。可以想像云时代开发模式与本地开发完全不同,拥有更高的研发效率,更快的迭代速度,更完善的质量控制。
云原生落地思考
作为 GTS 交付的一员,身上肩负着企业数字化转型的重任,怎么样能够帮助传统企业转型(通过互联网经验降维打击),更好的拥抱云原生,简单梳理了下云原生的落地路径,如下图:
图中纵坐标为业务敏捷性,云原生业务敏捷性方面的转型大致包含以下几步: 第一步:上云是基石; 第二步:构建 PaaS 平台。ACK PaaS (阿里容器平台)为运维人员屏蔽底层资源和运维的复杂度,提供高性能可伸缩的容器应用管理能力,而为开发人员提供了构建应用程序的环境,旨在加快应用开发的速度,实现平台即服务,使业务敏捷且具有弹性、容错性、可观测性; 第三步:基于 PaaS 实现 DevOps。PaaS 平台是通过提高基础设施的敏捷而加快业务的敏捷,而 DevOps 则是在流程交付上加快业务的敏捷。通过 DevOps(云效)可以实现应用的持续集成、持续交付,加速价值流交付,实现业务的快速迭代; 第四步:实现微服务治理。通过对业务进行微服务化改造,将复杂业务分解为小的独立单元,不同单元之间松耦合、支持独立部署更新,真正从业务层面提升敏捷性。在微服务的实现上,客户可以选择采用阿里 EDAS(支持 SpringCloud、 Dubbo 等),但随着技术的发展,微服务最好治理的治理方向应该是服务网格ServiceMesh(ASM 兼容 Istio); 第五步:实现微服务高级管理。在微服务之上实现 API 管理、微服务的分布式集成以及微服务的流程自动化。通过 API 管理帮助企业打造多渠道(自营、微信、天猫等)生态,最终实现 API 经济。通过微服务的分布式集成和流程自动化,企业可实现统一的业务中台。
图中横坐标是业务健壮性,通常建设步骤为: 第一步:建设单数据中心。大多数企业级客户,如金融、电信和能源客户的业务系统运行在企业数据中心内部的私有云。在数据中心建设初期,通常是单数据中心; 第二步:建设多数据中心。随着业务规模的扩张和重要性的提升,企业通常会建设灾备或者双活数据中心,这样可以保证当一个数据中心出现整体故障时,业务不会受到影响; 第三步:构建混合云。随着公有云的普及,很多企业级客户,开始将一些前端业务系统向公有云迁移,或者使用多家云厂商,这样客户的 IT 基础架构最终成为混合云、多云的模式。
“云原生” 看起来极其美好,可一旦深入进去到落地环节发现实际非常复杂,这个复杂体现在概念新、涉及技术面比较广,也体现在客户的期望价值差异很大,更体现在客户对未来的判断有很多不确定性。在未来的一段时间,我会不断整理自己的所闻所见、所思所想和实践中的思考,拿出来和大家分享,和大家探讨,这是开头的第一篇,希望能不断写下去,为企业数字化转型出一份自己的绵薄之力。
写在最后
“云” 时代必须以全新的思维、概念来看待应用架构和 IT 基础设施,只有从这个角度理解云原生才能得到正确的答案。未来必然是属于云原生的,所以,企业变革的绝不仅仅是工具,而是从思想到方法,再到工具的一整套理念。只有这样,才能更好迎接云时代的到来,发挥云原生的价值。
这是 “开发者” 最好的时代。这是 “云厂商” 最好的时代。这是 “交付人” 最好的时代。
未来已来,只是分布不均。让我们了解云原生,拥抱云原生,交付云原生。
测一测:你的云原生架构几分熟?
企业该从什么维度制定云原生架构的落地战略?云原生时代的企业该如何落地互联网分布式架构?这些问题都需要企业花费大量时间和成本去探索。鉴于此,越来越多企业希望能够通过云原生架构成熟度模型以指导数字化转型实践,并将之作为衡量转型成果水平的统一标准,提高转型效果。
**因此,我们正式发布《云原生架构成熟度模型》并上线测试。**具体内容可点击链接了解详情: https://jinshuju.net/f/XCU3lN 。 “ 阿里巴巴云原生 关注微服务、Serverless、容器、Service Mesh 等技术领域、聚焦云原生流行技术趋势、云原生大规模的落地实践,做最懂云原生开发者的公众号。”
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
今年两会,金融数字化、金融科技成为风口之下的热门词汇,多位代表委员提出金融数字化议案并表示金融业的数字化转型将提升金融服务的精准性,为解决中小企业融资难题、加大金融支持实体经济带来新机遇。同时,各代表委员们还指出,金融机构需要通过科技实现服务、效率、产品等方面的提升。中国财政科学研究院院长刘尚希认为,传统金融机构与互联网平台或金融科技公司合作,是加快推动金融数字化转型的重要途径之一。
数字化转型面前,对于银行等金融机构而言,技术解决方案水平直接决定着企业的业务能效。面对相关技术需求,网易云信作为集网易20年IM与音视频经验打造的通信与视频云平台,通过稳定、安全、易用的技术与深刻的行业洞察,助力银行等金融机构实现数字化转型,帮助其大大提升线上业务办理效率。
助力金融机构数字化转型 实现线上业务大幅提升
以往,用户办理各项业务通常都需要去银行网点,近年随着数字化技术的强劲发展,一些金融机构通过与技术平台合作,已经将越来越多的业务转为线上化办理,比如通过线上营业厅为用户办理小额贷款、理财业务等。台州银行、南京银行即是选择与网易云信合作,通过数字化转型实现了更多业务的线上化办理。
(业务场景)
当下,伴随消费升级,银行业竞争日趋激烈,而另一方面,互联网用户数的持续攀升让各大金融机构看到新的增量机会,抓住云计算、AI等新兴互联网技术,完成数字化转型,实现线上线下业务的一体化已成为赢得新机遇的关键。台州银行显然意识到了这点,其围绕业务咨询与受理、拓客与营销链条上的关键场景,携手网易云信与飞虎互动共同打造了7*24小时金融移动营业厅模式,将网易云信支持点对点通话、多人通话、互动直播等多种通话方式的音视频功能,应用于客户与坐席之间的点对点呼叫、自助面签、拉流质检等不同业务场景,完成包括认证、视频签约办理、视频理财风评、对公开户法人面签、投顾咨询等业务环节,满足线上业务诉求。
通过虚拟营业厅进行全行调度,台州银行将闲置柜员充分利用,提升了网点产能,提高了银行的服务效率与用户体验感。如今,在新的服务模式下,用户只需通过手机APP,进入线上营业厅频道便可完成咨询、小额贷款及理财业务办理等操作,无需专门跑腿网点。
(7*24小时移动营业厅)
在数字化转型的道路上,南京银行同样走在行业前端,其高度重视金融与科技的融合,并致力于通过创新赋能产业发展。为加快银行数字化转型,南京银行携手网易云信与飞虎互动开展创新模式应用,依托网易云信核心技术架构通信与视频云服务,其将 “金融互动视频服务”创新模式有效应用,成功实现了视频交易、转账、贷款等金融业务的线上场景,用户可以远程线上视频贷款面签、与理财专家视频“面对面”咨询、一键呼叫视频客服等。
据统计,在将技术服务切入核心业务后,利用视频办理业务的用户呼叫量高度增长,业务办理效率大大提升,比如,南京银行和法国巴黎银行合资组建的消费金融机构CFC在使用该款产品后,有效接通率提升了80%,开画延迟小于2秒,两大指标的提升,使得南京银行CFC线上贷款业务成功率提高到95%左右,大大提升了业务办理效率。
合规与安全兼顾 以创新技术满足金融服务高要求
源于线上金融服务同样受到相关法律法规的约束和监管,比如贷款和理财业务办理要求双录音,三亲见等,因此对于服务全过程的音视频通话稳定性、图像传输的画面清晰度等有着极高的要求。同时,金融服务对安全性要求极为严苛,线上业务要求私有化部署,尤其需要确保数据的安全性。针对上述硬性要求,网易云信针对性地进行了技术架构的部署和安全举措的强化。
在技术架构与部署方面,网易云信采用混合云的技术架构,保障金融合规和互联网化。一方面,业务控制、交易等功能的核心业务应用服务仍采用本地化部署,同时将部分视频调度服务通过网易视频云信令服务集群来实现云端的部署。另一方面,网易云信还提供金融专用版视频网关,支持本地化部署,满足银行内外网安全穿越的部署要求。开发者通过简单集成客户端SDK和云端开放API,可快速接入云信的IM和音视频功能。此外,网易云信还打通了多个将触达用户的服务入口,用户无论从何种终端进入,都可直达移动视频营业厅服务平台。
在安全性方面,网易云信通过独家自研算法加密,数据密钥自定义方案从传参到解密全程保障客户的信息安全。首先,银行端生成密钥对,通过网易的API接口传入加密密钥;其次,视频会通过加密密钥对视频文件进行加密;最后,银行拉取双录文件并解密操作,并将解密后的视频文件保存到本地。整个过程无缝应对金融行业对安全的严苛需求,让客户安心无忧办理业务。
(网易云信获公安部信息系统三级等级保护认证)
凭借严苛的技术部署和安全举措,网易云信获得公安部信息系统三级等级保护认证和CSA-STAR云计算最高标准安全认证。从产品上线至今,除南京银行、台州银行外,网易云信携手合作伙伴,已和中国银行多家分行、中国工商银行多家分行、苏宁银行、瑞丰银行、中国人寿保险、和信普惠和永安期货等诸多知名金融企业展开合作,为金融机构提供定制化的解决方案,有效支撑起金融行业发展需求。
疫情加速数字化转型 携手金融机构决胜未来战场
业内专家指出,近年来,越来越多的银行金融机构拥抱数字化,将原本的线下业务挪到线上进行发展。该趋势也得到官方数据的证实,据中国银行业协会统计,2019年银行业金融机构网上银行交易笔数达1637.84亿笔,其中手机银行交易笔数达1214.51亿笔,交易金额达335.63万亿元,同比增长38.88%;全行业离柜率高达89.77%。显然,不少金融机构已在推进数字化转型。
此次新冠疫情的全面爆发,让所有行业面临转型大考,金融行业也不例外。银行的零售业务受到较大冲击,传统金融行业由于业务渠道单一,且受时间和空间限制,网点只能被动等待客户上门,运营成本居高不下。各大银行不得不发力线上服务,尽可能通过互联网银行、手机App等线上渠道扩展相关业务,同时,通过技术赋能调整业务结构,加速数字化转型。在此期间,已经完成数字化转型的机构实现逆势增长,数字化能力弱的机构则业务断崖式下跌。
麦肯锡全球资深董事合伙人曲向军认为,近些年来新的客户行为和市场环境正在从根本上重塑营销这件事,能否借助大数据、高级分析等数字化手段实现大规模获客,是新时期金融机构兴旺和衰败的关键。另外,金融数字化转型亦是落实国家战略部署的必然举措。2019年8月22日,中国人民银行发布了《金融科技(FinTech)发展规划(2019-2021年)》,标志金融科技正式成为国家层面重点统筹发展的领域之一;2020年3月5日,中国人民银行联合各部门印发《统筹监管金融基础设施工作方案》,进一步加强对我国金融基础设施的统筹监管与建设规划,为金融科技的未来发展创造了适宜、规范的制度环境。
多重趋势与政策之下,未来金融业将迎来数字化转型提速的黄金时期。同时,随着云计算、区块链、5G等技术的大力发展,更多新兴科技将被应用于传统金融业务中,成为数字化转型的强力支撑。在此过程中,网易云信将凭借其IM 、音视频解决方案,持续赋能金融数字化创新模式,并结合时代浪潮下的新型技术不断夯实产品技术实力,携手合作伙伴,助力金融机构在未来走得更远。
立即 免费试用 网易云信金融视频平台解决方案 >>>
了解 网易云信 ,来自网易核心架构的通信与视频云服务 >>
网易云信( NeteaseYunXin )是集网易 20 年 IM 以及音视频技术打造的 PaaS 服务产品,来自网易核心技术架构的通信与视频云服务,稳定易用且功能全面,致力于提供全球领先的技术能力和场景化解决方案。开发者通过集成客户端 SDK 和云端 OPEN API ,即可快速实现包含 IM 、音视频通话、直播、点播、互动白板、短信等功能。
「深度学习福利」大神带你进阶工程师,立即查看>>>
业界要闻 CNCF 成立新的工作组 WG-Naming
目前首要任务是消除带有种族歧视的词语,比如 node-role.kubernetes.io/master ,whitelist/blacklist。 KubeCon + CloudNativeCon North America is going online
KubeCon + CloudNativeCon NA 2020 大会改成于 11 月 17 日 - 20 日线上举办,CFP 截止日期也延长到了 7 月 12 日。 11 个新项目入选 CNCF Sandbox ;
包括 CNI-Genie,Keptn,Kudo,Kuma,Crossplane 等 11 个项目在内的项目入选了 sandbox。
上游重要进展 Wait for all informers to sync in /readyz.
kube-apiserver 增加新的接口 /readyz 来判断是不是 ready 来接收 request:对于大集群来说,apiserver 中的 informer 可以会需要 30-50s 来初始化,这时候时候会导致一些请求无法处理,比如 node authorize 等。 Admission webhook warnings
admission webhook 的返回值增加 warning 字段。 The Pod is eligible to preempt when previous nominanted node is UnschedulableAndUnresolvable
修复 pod 抢占过程中,由于 nominated 的节点 Unshedulable 或 Unresolvable 导致的调度失败问题。 KEP-1845: prioritization on volume capacity
优化 PV 在调度过程中的逻辑,让调度器可以根据容量匹配最合适的 PV,避免大量大规格的 PV 被小规格的 PVC 挂载。
开源项目推荐 kubernetes-goat
帮助你更快地了解和学习 Kubernetes 安全相关知识,增强生产集群的安全性。 flagger
最近刚发布了 1.0 版本,使用 Prometheus 的指标,支持多种部署策略(比如自动化金丝雀发布、AB 测试,蓝绿部署)的发布。 open-match
月初刚发布了 1.0 版本,Open Match 使用 OpenCensus 和 Prometheus 来收集 metrics,还提供了高度可扩展性,可自定义的配对逻辑范例,允许基于延迟,等待时间和技能级别,进行简单的游戏玩家配对。 由于 Open Match 在 Kubernetes 上运行,因此可以部署在任何公共云,本地数据中心或工作站中。 kconmon
一个高效的节点链接性测试工具,帮助快速定位不同 AZ、节点的问题。
本周阅读推荐 云原生五大趋势预测,K8s 安卓化位列其一
Kubernetes 本身并不直接产生商业价值,你不会花钱去购买 Kubernetes 。这就跟安卓一样,你不会直接掏钱去买一个安卓系统。Kubernetes 真正产生价值的地方也在于它的上层应用生态。本文预测了云原生的五大趋势,推荐大家阅读。 Monitoring Kubernetes tutorial: using Grafana and Prometheus
一个入门的Kubernetes监控接入教程,可以快速通过Helm Chart搭建Grafana和Prometheus。非常适合初学者上手。 Stupid Simple Kubernetes — Persistent Volumes explained by examples
非常详细的教程介绍了PV,PVC,以及StorageClass在生产环境中的使用。 “ 阿里巴巴云原生 关注微服务、Serverless、容器、Service Mesh 等技术领域、聚焦云原生流行技术趋势、云原生大规模的落地实践,做最懂云原生开发者的公众号。”
「深度学习福利」大神带你进阶工程师,立即查看>>> 因为云平台存储技术故障导致积累两年的业务数据完全丢失?
所有数据 100% 不可恢复?
花两年心血打造的平台就此付诸东流?
这并不是第一起公有云事故,也算不上是最严重的一起。就在今年 3 月份,Facebook 因为数据泄露事件甚至成为整个互联网行业的焦点,500 亿美金市值瞬间蒸发。
随着国内公有云服务的普及,越来越多的企业开始选择公有云服务,但不可否认,云服务并非万能,即便和传统 IT 部署架构相比有极大优势,但云服务也无法保证 100% 永远在线,总有可能因为各种突发意外导致服务故障,比如意外断电,光缆被挖断,自然灾害等。
各家云计算厂商所遇到的数据丢失问题,证明了一个事实:即使有多少个 9 的可靠性,毕竟不是 100%,理论上总有出问题的可能。
墨菲定律:凡是担心发生的事情就一定会发生,凡是可能出错的事就一定会出错。
以此推论,你的业务数据无论存储在什么地方,都可能会存在丢失的风险。千万不要存在侥幸心理。
我们为云计算领域总结出 六条新墨菲定律 :
在数据就是企业生命的时代,对于一家依赖互联网的公司来说,一旦系统不可用或者数据完全丢失,相当于企业进入休克状态。所以公司从上至下都必须对可能发生的数据丢失足够重视,而从管理体系来说,最重要的是要确保系统多层备份机制实时有效。对此我们提供企业数据安全自查机制供参考:
 无论企业高管还是运维团队都要知道,备份的目的是为了更快的恢复,做好定期恢复演练和容灾切换演练,如果条件允许数据和业务从主备模式转变为双活或多活模式,避免备份系统关键时刻“形同虚设”。
企业用户在高可用架构的设计上要根据自己的业务特性精心设计,多重保障。同时利用多种云部署自己的业务,聚合好每种云的优势,进行有效的搭配组合,把他们的价值发挥到最大,避免同类事故的再次发生。
「深度学习福利」大神带你进阶工程师,立即查看>>>
前言
该文章将通过一个小demo将讲述Redis中的string类型命令。demo将以springboot为后台框架快速开发,iview前端框架进行简单的页面设计,为了方便就不使用DB存储数据了,直接采用Redis作为存储。
文中不会讲述springboot用法及项目搭建部分。直接根据功能方面进行讲述,穿插string命令操作说明。
案例
demo功能是记录日志,整个demo的大致页面如下
准备工作
首先定义一个key的前缀,已经存储自增id的key private static final String MY_LOG_REDIS_KEY_PREFIX = "myLog:"; private static final String MY_LOG_REDIS_ID_KEY = "myLogID";
日志相关的key将会以myLog:1、myLog:2、myLog:3的形式存储
redis操作对象 private RedisTemplate redisTemplate; //string 命令操作对象 private ValueOperations valueOperations;
新增
先来看看gif图吧
来看看后台的方法 @RequestMapping(value = "/addMyLog",method = RequestMethod.POST) public boolean addMyLog(@RequestBody JSONObject myLog){ //获取自增id Long myLogId = valueOperations.increment(MY_LOG_REDIS_ID_KEY, 1); String date = LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss")); myLog.put("id",myLogId); myLog.put("createDate", date); myLog.put("updateDate", date); //将数据写到redis中 valueOperations.set(MY_LOG_REDIS_KEY_PREFIX+myLogId, myLog.toString()); return true; }
从上面代码可以看出有两个操作redis的地方 valueOperations.increment(MY_LOG_REDIS_ID_KEY, 1);
valueOperations.set(MY_LOG_REDIS_KEY_PREFIX+myLogId, myLog.toString());
命令介绍
valueOperations.increment其实就相当于Redis中的INCR、INCRBY、INCRBYFLOAT、DECR、DECRBY
INCR INCR key
对存储在指定key的数值执行原子的加1操作。没有对应的key则设置为0,再相加
INCRBY INCRBY key increment
其实和INCR类似,不同的是这个命令可以指定具体加多少
INCRBYFLOAT INCRBYFLOAT key increment
也是类似的,不同的是加的数值是浮点数 incrbyfloat incrByFloatKey 5.11 incrbyfloat incrByFloatKey 5.22
执行结果如下
下面是java代码 @Test public void incrByFloat() { System.out.println(jedis.incrByFloat("incrByFloatKey", 5.11)); System.out.println(redisTemplate.opsForValue().increment("incrByFloatKey", 5.22)); }
与INCR相反的命令有DECR和DECRBY,这里就不做介绍了。
valueOperations.set就是对应Redis的SET命令了,相关联的还有SETEX、SETNX和PSETEX。需要注意的是set在Redis版本2.6.12 提供了 EX 、 PX 、 NX 、 XX 参数用于取代SETEX、SETNX和PSETEX,后续版本可能会移除SETEX、SETNX和PSETEX命令。下面是官网的原话 Since the SET command options can replace SETNX , SETEX , PSETEX , it is possible that in future versions of Redis these three commands will be deprecated and finally removed.
SET SET key value [expiration EX seconds|PX milliseconds] [NX|XX]
设置键key对应value
参数选项 EX seconds – 设置键key的过期时间,单位时秒
PX milliseconds – 设置键key的过期时间,单位时毫秒
NX – 只有键key不存在的时候才会设置key的值
XX – 只有键key存在的时候才会设置key的值
SETRANGE SETRANGE key offset value
替换从指定长度开始的字符 set setRangeKey "Hello World" setrange setRangeKey 6 "Redis" get setRangeKey
执行结果如下
下面是java代码 @Test public void setRange() { jedis.set("setRangeKey", "Hello World"); jedis.setrange("setRangeKey", 6 , "Redis"); System.out.println(jedis.get("setRangeKey")); //spring redisTemplate.opsForValue().set("setRangeKey", "learyRedis", 6); System.out.println(redisTemplate.opsForValue().get("setRangeKey")); }
MSET MSET key value [key value ...]
同时设置多个key、value
MSETNX MSETNX key value [key value ...]
同时设置多个key、value,key存在则忽略
查询
接着写个查询方法,将新增的内容查询出来 @RequestMapping(value = "/getMyLog",method = RequestMethod.GET) public List getMyLog(){ //获取mylog的keys Set myLogKeys = redisTemplate.keys("myLog:*"); return valueOperations.multiGet(myLogKeys); }
方法中的两行都涉及到了Redis操作,先是通过keys命令获取 myLog:* 相关的key集合,然后通过multiGet方法(也就是mget命令)获取记录。
命令介绍
KEYS KEYS pattern
查找所有符合给定模式pattern(正则表达式)的 key
GET GET key
获取key对应的value set getKey getValue get getKey
执行结果如下
GETRANGE GETRANGE key start end
获取start到end之间的字符 set getRangeKey "Hello learyRedis" getrange getRangeKey 6 -1 getrange getRangeKey 0 -12
执行结果如下
GETSET GETSET key value
设置key对应的新value且返回原来key对应的value getset getSetKey newValue set getSetKey value getset getSetKey newValue get getSetKey
执行结果如下
MGET MGET key [key ...]
返回所有指定的key的value mset mGetKey1 mGetValue1 mGetKey2 mGetValue2 mGetKey3 mGetValue3 mget mGetKey1 mGetKey2 mGetKey3 mGetKey4
执行结果如下
更新
来看看代码 @RequestMapping(value = "/updateMyLog",method = RequestMethod.POST) public boolean updateMyLog(@RequestBody JSONObject myLog){ String myLogId = myLog.getString("id"); myLog.put("updateDate", LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"))); valueOperations.set(MY_LOG_REDIS_KEY_PREFIX+myLogId, myLog.toString()); return true; }
这里的set在新增方法里面讲述过,那么来看看APPEND、STRLEN命令吧
命令介绍
APPEND APPEND key value
在value的尾部追加新值
redis客户端执行的命令如下 append appendKey append append appendKey Value get appendKey
执行结果如下
STRLEN STRLEN key
返回value的长度
删除
代码如下 @RequestMapping(value = "/delMyLog/{id}", method = RequestMethod.DELETE) public boolean delMyLog(@PathVariable String id){ return redisTemplate.delete(MY_LOG_REDIS_KEY_PREFIX + id); }
可以看到代码中只用了delete方法,对应着Redis的DEL命令(属于基本命令)
命令介绍
DEL DEL key [key ...]
删除key
BIT相关命令
bit命令有SETBIT、GETBIT、BITCOUNT、BITFIELD、BITOP、BITPOS这些。
命令这里就不做介绍了,直接讲述bit相关的案例。 Pattern: real time metrics using bitmaps
BITOP is a good complement to the pattern documented in the BITCOUNT command documentation. Different bitmaps can be combined in order to obtain a target bitmap where the population counting operation is performed.
See the article called "Fast easy realtime metrics using Redis bitmaps" for a interesting use cases.
案例地址 Fast easy realtime metrics using Redis bitmaps
网上译文也有许多,有需要的百度或者google即可
这里大概讲述下使用位图法统计日登入用户数、周连续登入用户数和月连续登入用户数 位图法就是bitmap的缩写,所谓bitmap,就是用每一位来存放某种状态,适用于大规模数据,但数据状态又不是很多的情况。通常是用来判断某个数据存不存在的。 ------来自百度百科
就好像java中int有4个字节,也就是32位。当32位全为1时,也就是int的最大值。
位只能被设置位0或者1,也就是二进制。
java中可以用BitSet来操作位的相关操作
场景
有一万个用户,id从1到10000,根据当前是否上线,来设置在第id位上是否为1或者0。通过每天的记录来统计用户连续上线的情况。
分析
一号有id为5、3、1的上线了,二号有id为5、4、3的上线了,三号有id为3、2、1的上线了。存储的数据如下 序号:5 4 3 2 1 0 一号:1 0 1 0 1 0 二号:1 1 1 0 0 0 三号:0 0 1 1 1 0
那么我们只有将三天的数据进行与操作就可以知道,三天连续上线的有哪些了,与操作的结果如下 序号:5 4 3 2 1 0 结果:0 0 1 0 0 0
很明显是id为3的用户连续登入3天。
代码
先定义一些常量 //存储的key前缀 private static final String ONLINE_KEY_PREFIX = "online:"; //天数 private static final int DAY_NUM = 30; //用户数量 private static final int PEOPLE_NUM = 10000;
然后模拟一个月的数据 public void createData() { //用来保证线程执行完在进行后面的操作 CountDownLatch countDownLatch = new CountDownLatch(DAY_NUM); int poolSize = Runtime.getRuntime().availableProcessors() * 2; ThreadPoolExecutor executor = new ThreadPoolExecutor(poolSize, poolSize, 60, TimeUnit.SECONDS, new ArrayBlockingQueue(DAY_NUM-poolSize)); //DAY_NUM天 for (int i = 1; i <= DAY_NUM; i++) { int finalI = i; executor.execute(() -> { //假设有PEOPLE_NUM个用户 for (int j = 1; j <= PEOPLE_NUM; j++) { redisTemplate.opsForValue().setBit(ONLINE_KEY_PREFIX + finalI, j, Math.random() > 0.1); } countDownLatch.countDown(); }); } //等待线程全部执行完成 try { countDownLatch.await(); } catch (InterruptedException e) { e.printStackTrace(); } }
最后是统计 public void calActive(int day) { if (day < 0 || day > DAY_NUM){ throw new IllegalArgumentException("传入的天数不能小于0或者大于30天!"); } long calStart = System.currentTimeMillis(); BitSet active = new BitSet(); active.set(0, PEOPLE_NUM); for (int i = 1; i <= day; i++) { BitSet bitSet = BitSet.valueOf(jedis.get((ONLINE_KEY_PREFIX + i).getBytes())); active.and(bitSet); } long calEnd = System.currentTimeMillis(); System.out.println(day + "天的上线用户" + active.cardinality() + ",花费时长:" + (calEnd - calStart)); }
测试方法 @Test public void daliyActive() { /** *模拟数据 */ createData(); /** * 开始统计 */ //1 calActive(1); //7 calActive(7); //15 calActive(15); //30 calActive(30); }
测试结果 1天的上线用户9015,花费时长:0 7天的上线用户4817,花费时长:0 15天的上线用户2115,花费时长:0 30天的上线用户431,花费时长:15
有需要看相关代码的请点击 GITHUB地址
其他
关于其他相关的命令可以查看下方地址
string全命令
Redis基本命令
命令比较多,但是还是建议学习的人最好每个命令都去敲下,加深印象。
下面诗句送给每一个阅读的人。 纸上得来终觉浅,绝知此事要躬行。————出自《冬夜读书示子聿》
作者: 勿妄
原文链接
本文为云栖社区原创内容,未经允许不得转载。
「深度学习福利」大神带你进阶工程师,立即查看>>>
摘要: Istio 1.0 发布,加速Service Mesh概念落地 Istio 1.0 于北京时间8月1日0点正式发布!虽然比原本官网公布的发布时间晚了9个小时,但这并未影响到Istio在社区的热度。
Istio 是 Service Mesh概念的具体实现。 2018年被称为 Service Mesh 元年,誉为新一代的微服务架构, 有了Service Mesh,像Docker和Kubernetes标准化部署操作一样来标准化我们的应用程序运行时的操作便成为可能。 Istio是其中最成熟和被广泛接受的开源项目。它是连接、管理和保护微服务的开放平台。今天发布的1.0 版本是一个重要的里程碑。 这意味着Istio的所有核心功能都已经可以落地部署,不再只是演示版了。 本文来自阿里巴巴中间件事业部硅谷团队 Istio 技术专家 Andy在 Istio上的实践和对1.0版本的解读,Andy长期关注Service Mesh,在Cloud Foundry,Kubernetes,Envoy上有着丰富的实践和开发经验。
Istio 新功能简介
1.0版本中的新功能大致如下:
» 网络 使用 Virtual Service 进行 SNI 路由 流式 gRPC 恢复 旧版本(v1alpha1)的网络 API 被移除 Istio Ingress 被gateway替代
» 策略和遥测 属性更新 缓存策略检查 遥测缓冲 进程外适配器 客户端遥测
» Mixer 适配器 SignalFX Stackdriver
» 安全 RPC 级授权策略 改进的双向 TLS 认证控制 JWT 认证
几个重要的改变
在众多的改变中,下面几点和之前版本相比,有较大的增强和改动,在这里我们展开介绍下:
» IstioGateway 替代 IstioIngress
在 istio 1.0 之前,Istio Ingress 直接使用 Kubernetes Ingress,因此受到 Kubernetes 的 Ingress 本身只有 L7 的网络控制功能的限制,很多功能无法实现。这些功能包括: L4-L6的LB 对外的mTLS 对SNI(服务器名称指示)的支持 以及其它在Pilot已经实现的对内部网络的功能,比如Traffic splitting,fault injection, mirroring, header match等。
为了解决这些问题,Istio 在 1.0 版本提出了 Istio Gateway 的概念,从而摆脱了对 Kubernetes Ingress 的依赖,可以实现更多的功能,例如: L4-L6的LB,对外的mTLS,对SNI(服务器名称指示)的支持等。
如果我们希望给一个 Kubernetes 的 guestbook ui Service 做一个 Istio Ingress 的话,在 0.8 版本以前我们需要如下定义一个 Istio Ingress Resourse:
这里面是我们对 L7 的策略配置。但是可以看到,基于这种 Ingress 并不能支持 mTLS 等高级功能。现在在 Istio 1.0 版本,我们可以使用新的 Istio Gateway 来完成类似的配置。这种配置会分两部分: L4-L6 的配置在 Gateway 这种资源中; L7 的配置在绑定的 Virtual Services 配置资源中。
对于上面同样的例子,Istio Gateway 资源的定义是这样的:
通过 Gateway 这种资源,我们提供了对mTLS的支持。为了完成对 HTTP path 的匹配和对 Virtual Host 的支持,我们需要定一个新的 VirtualService 资源并且将它和 Gateway 资源绑定。Virtual Services 很像以前的 Virtual Host,它可以允许同一个IP对应不同的域名,所以即使同样的路径也不会产生重复。
它的配置和与 Gateway 的绑定如下:
» Mixer 进程外适配器
适配器是让第三方用户来扩展Mixer功能的,比如和自己的 Logging 系统集成。以前的适配器,是与 Mixer 主进程在一起的。这样有些问题,比如如果适配器有用户的认证信息,那么上传的时候所有人都知道了。另外,如何对这些适配器做健康检查(health check)呢? 它们在同一个进程里。 新的版本,适配器在 Mixer 主进程之外,用户不但可以决定是否要把适配器上传,而且运行时也可以进行外部健康检查了。
不过由于适配器 和 Mixer 主进程不在同一个进程,需要进行进程间通讯,因此适配器要和主进程通讯会依赖 RPC。这里 Mixer 选用了比较流行的标准 RPC 框架 gRPC作为实现。
有了这个功能,在 Istio 的 Mixer 中开发外适配器功能只需要如下三个步骤: 编译适配器源代码 生成适配器模版 部署适配器镜像
如果有兴趣更深入的了解适配器的开发和使用,请参考这两个教程
(第一部分)
(第二部分)
支持可以使用身份验证策略配置的 JWT 身份验证
JWT(JSON Web Token)是一种基于token的鉴权机制。JWT很流行的原因主要是它的简单易用,特别是采用JSON格式,是大部分编程语言支持的。所以尽管出现的时间不长,但却是很多编程人员的鉴权首选。因此 Istio 对 JWT 进行了支持。
例如我们创建一个 JWT token payload来庆祝 Istio 1.0 GA :
用户调用时,需要把 JTW token 来编码后,以 Bearer 形式进行传递:
Istio 就用这个Bearer来作最终用户认证。是不是很简单呢?Istio 之前就支持基于 JWT 的Authentication。新的版本开始支持 Authorization。对用户来说,只是在同一个Authentication policy 的资源上扩展一部分而已。
Istio的 Authorization 是基于角色的访问控制,它提供命名空间级别, 服务级别和 method-level 的访问控制。
要实现Authorization,只需要如下几步: 首先要开启允许授权; 开启了特定级别(如:命名空间)的授权; 创建这个级别的访问控制策略。
更详尽的内容,可以参考 Istio 安全文档 :
三、阿里巴巴对 Istio 生态的支持
以上是关于Istio 1.0的简单介绍。如果大家感兴趣的话,可以通过以下的 教程 进行实践。
阿里巴巴中间件技术团队会持续关注和参与Service Mesh的开发和推广活动。并提供一系列关于Service Mesh和 Istio 的解读、实践和教程,详细介绍 Istio新版本中的概念、功能以及未来最新的动态。我们也正计划在Dubbo 2.7的版本中加入对Istio的集成,充分利用Service Mesh的理念,进一步简化微服务的管理。
作者: 中间件小哥
原文链接
本文为云栖社区原创内容,未经允许不得转载。
「深度学习福利」大神带你进阶工程师,立即查看>>>
摘要: 随着IT技术的发展,特别是serverless概念被提出以后,网络上出现了很多唱衰虚拟化以及对未来虚拟化方向的讨论,很多文章都做了vm和容器的对比,任何一种技术存在都有其合理性,我们不妨客观分析两种技术的特点选择适合自己业务的,才是最重要的,开始之前先再简单介绍下两种
阿里云高级解决方案架构师 杨旭
世界最大混合云的总架构师,4年前,开始作为双11阿里云技术负责人,负责搭建全球最大的混合云结构,把 “双11”的电商业务和技术场景在阿里云上实现,并保障这个混合云在双11当天能够满足全球客户的购物需求。
正文:
随着IT技术的发展,特别是serverless概念被提出以后,网络上出现了很多唱衰虚拟化以及对未来虚拟化方向的讨论,很多文章都做了vm和容器的对比,任何一种技术存在都有其合理性,我们不妨客观分析两种技术的特点选择适合自己业务的,才是最重要的,开始之前先再简单介绍下两种。
技术的定义:
所谓虚拟机(VM)就是对操作系统的完全模拟,虚拟机是架构在虚拟化指令之上,需要特定的硬件、软件同时的支持,,每台虚拟机会预分配需要的资源,包括CPU,内存,磁盘等,以及一个完整的用户操作系统
容器就是隔离一个运行环境,每个封装好的隔离环境我们就称为一个容器,容器包含应用以及其运行的依赖包,容器之间大家互相共享内核,所有的容器在宿主机操作系统中以分离的进程运行。
图片来自网络
从图上可以看出容器和虚拟机最大的区别就是容器没有Hypervisor这一层,每个容器和宿主机共享资源,主要为了解决了传统Hypervisor带来的性能开销;反之,虚拟化创造的是更加隔离的环境,每个虚拟机有独立的guest os,大家各自封闭运行,所有应用程序跑在虚拟机内部,不会因为某个虚拟机内部应用程序
的漏洞给宿主机造成危害,虚拟化技术是在硬件资源层面的虚拟,容器技术则是对应操作系统的进程层面,下面从几个方面做进一步对比:
容器技术之所以火的原因笔者总结主要有三个:
1.传统IT诉求的演进
随着资源利用率,设备可维护性等问题的解决,人们对于资源的关注从基础iaas层开始向上发展,特别是微服务等概念的提出,大家都从一个大而全的应用演变成希望一个应用就只完成某个特定的功能,,更希望今天我们的开发是开箱即得,按需索取,并且 "build once,run everywhere,彻底解决应用的部署,分发,可用性,可运维性,监控等问题运维等问题,特别是线上线下的兼容性,我相信很多开发都遇到测试环境调通一到线上就挂的囧境,为什么—环境不一致导致,今天容器又天然就和微服务的理念是match的。
DevOps最佳实践
运维这个职位是个吃力不讨好的高危行业,干对了你是应该了,干错了第一个责任人就是你,运维本身不像研发没有实际产出,不出问题的时候大家不会感觉到你的存在,所以作为运维的职业如何在公司快速发展的业务过程中找到自我价值和定位是很多运维人在探索的方向,google最早对运维进行了重新定义,提出SRE的概念,并且结合devops在实际工作中的落地,取得了很好的效果,阿里在这条路上也进行了探索,并且觉得docker是最佳的落地方式,今天阿里也在做大规模的docker化,今天做docker化是为了解决我们环境不一致问题,提升我们的开发和发布效率,在阿里内部,docker和虚拟化根据各自处理场景的不通相互融合的非常好。
最底层的ECS服务可以是多种介质的异构,传统的kvm,最新的神龙裸金属服务器,GPU,FPA方案,上层可以直接对用户提供VM,也可以是容器,所以的容器服务都基于ECS来构建,最顶层的业务平台根据自身需求可以通过k8来进行容器的定义也可以通过paas平台直接调用api进行虚拟资源的弹性伸缩。
对性能的要求
传统部署在物理机上的高IO业务有服务化需求之后自然想到的就是docker+物理机,例如数据库服务,在未经优化的情况下,在虚拟机化上跑I/O业务性能将受损失。经过可靠的测试虚拟化对于物理硬件的损耗在优化的情况下也要有5%左右。
未来大部分业务系统将会变成虚拟机+Docker形式的组合,操作系统和Docker本身采用虚拟机镜像方式部署,软件、业务依赖组件,业务定义等与业务相关属性采用容器镜像,既实现安全隔离有提升资源的高利用率。
当然我们需要去优化和解决虚拟化以及容器带来的性能损耗,阿里云在裸金属服务器上的探索通过将虚拟化逻辑offload到神龙的MOC卡中,通过专有硬件方案来解决虚拟化的损耗,这样物理机本身的性能就和普通PC无异,完全给到业务使用,基于裸金属的方案可以跑anystack的方案,可以支持xen,kvm,vmware等,在阿里内部,已经开源的pouch通过内部大量场景的优化加上基于神龙的底座方案可以将整个三层的损耗做到<3%,让我们既做到了服务化又不损失性能。
【往期回顾】
1.阿里云王牌架构师一问开发者:我需要一个高并发的架构,我的系统要改造成微服务吗
2.阿里云王牌架构师杨曦:也谈系统缓存设计误区及高阶使用技巧
3.阿里云王牌架构师杨曦:N多环境N多应用个性配置管理如何从混乱到简单?
更多干货内容尽在阿里云总监课,戳链接报名:http://click.aliyun.com/m/1000011882/
阿里云总监系列课重磅上线!聚焦人工智能、弹性计算、数据库等热门领域,首次集齐12位阿里云技术高管,耗时半年精心打磨,从理论到实践倾囊相授,从零开始绘制技术大牛成长路径,限时直播课程免费报名中!
作者: 云攻略小攻
原文链接
本文为云栖社区原创内容,未经允许不得转载。
「深度学习福利」大神带你进阶工程师,立即查看>>>
摘要 : 众多项目研发过程中为了调试观察应用运行时表现,修改常量配置的场景下往往需要频繁地对应用代码及配置项做打包发布进行应用版本更新甚至回滚代码。基于该场景,任何的应用配置项变更都需要将整个应用重新打包发布,整个过程非常繁琐,且容易出错。
阿里云高级解决方案架构师 杨旭
世界最大混合云的总架构师,4年前,开始作为双11阿里云技术负责人,负责搭建全球最大的混合云结构,把 “双11”的电商业务和技术场景在阿里云上实现,并保障这个混合云在双11当天能够满足全球客户的购物需求。
正文:
众多项目研发过程中为了调试观察应用运行时表现,修改常量配置的场景下往往需要频繁地对应用代码及配置项做打包发布进行应用版本更新甚至回滚代码。基于该场景,任何的应用配置项变更都需要将整个应用重新打包发布,整个过程非常繁琐,且容易出错。非常典型且具有代表性的是:Redis连接串配置,应用业务功能切换开关,应用的安全限流配置,数据库访问配置等等一系列。
在此引申一个切实场景:一批早期的数据库实例所在服务器都即将过保进行替换,新数据库实例的端口及用户名密码保持不变并且持续与老库保持数据同步,一个非常棘手的问题来了,若一个应用需要同时访问其中多个db实例,在切换的时候如何能做到快速的切到对应db的新实例上?尽可能缩短因切换全过程时间消耗而引起的业务系统不可用时长。
对于此,业界普遍解决方案是引入独立于应用之外的配置类服务系统,那么这类配置中心服务到底是如何应对这个棘手问题呢,同时具备哪些关键要素呢?
1.运行时动态调整配置项,业务代码感知配置变化并做出响应。
针对上述场景问题,对症下药。通过依托于配置中心服务,动态修改配置项并且业务代码及时感知到变化值,jdbc驱动能根据新的数据库连接串的变化并对新数据源发起连接请求操作,完美地解决数据库切换过程耗时长的问题,同理也能做到数据源的快速回切,比如发现待切换目标主库存在其他问题必须切回。
2.配置集中式管理,避免游离,杜绝配置项无对应owner。
作为应用owner,务必十分清楚自身应用需要哪些配置,分别是做什么用途的,配置的存在形态是什么。将这些原本存在于代码或静态properties配置文件的,梳理出来统一管理,这样做的好处是业务代码与配置项解耦,做到动配置而无需修改代码又避免发生遗漏。
3.配置层面的权限管理,特别是关键配置项不能谁都可以改动。
配置数据的安全性对应用至关重要,倘若是涉及到业务开关或是全局功能的配置,权限策略需要严格把控,比如淘宝大秒杀系统的时间,商品,库存等信息,是万万不可随意改动的。阿里云ACM配置中心服务结合RAM访问控制系统构建权限管理。
4.配置服务自身的容灾切换,高可用性等。
仔细剖析ACM的架构,这是一套分三层自下而上的高可用性和稳定性保障。首先从底层数据库存储主备容灾,再到ACM的主要服务层分布式集群可靠性,最后再是ACM客户端即应用侧的本地配置数据容灾。简单地说就是ACM的DB及应用服务都挂了,也不会立即影响到客户正在运行的应用系统,容灾发挥了重要作用。
Figure 1图片来自阿里云ACM
那么从业务使用需求角度我该如何选型配置服务?
几款主流相似产品简介:
1.ZooKeeper 是一个分布式应用程序协调服务,是 Google Chubby 的开源实现。它是一个为分布式应用提供一致性服务的软件,提供的功能包括配置维护、域名服务、分布式同步、组服务等。在 Hadoop 集群等场景下,ZooKeeper 同时充当应用配置管理的角色。但是由于它是 CP(Consistency,Partition Tolerance) 类应用,因此在可用性和性能上都会受到一定影响。
2.ETCD和 ZooKeeper 类似,ETCD 是一个高可用的键值存储系统,主要用于配置共享和服务发现。ETCD 是由 CoreOS 开发并维护的,灵感来自于 ZooKeeper 和 Doozer。它使用 Go 语言编写,并通过 Raft 一致性算法处理日志复制以保证强一致性。etcd 和 ZooKeeper 类似,同样可以用来做应用管理配置。但是由于它是强一致的管理类应用,因此其可用性和性能在某些场景会受到一定影响。
3.Spring Cloud Config Server和 ACM 类似,Spring Cloud Config Server 为服务端和客户端提供了分布式系统的外部配置支持。配置服务器为各应用的所有环境提供了一个中心化的外部配置。与 ACM 不同的是,Spring Cloud 配置服务器默认采用 Git 来存储配置信息,其配置存储、版本管理、发布 等功能都基于 Git 或其他外围系统来实现。除此之外,在配置功能方面,ACM 和 Spring Cloud Config 也有很大不同。
Figure 2来源阿里云ACM
【往期回顾】
1.阿里云王牌架构师一问开发者:我需要一个高并发的架构,我的系统要改造成微服务吗
2.阿里云王牌架构师二问开发者:容器和虚拟化你会怎么选?
3.阿里云王牌架构师杨曦:也谈系统缓存设计误区及高阶使用技巧
更多干货内容尽在阿里云总监课,戳链接报名:http://click.aliyun.com/m/1000011882/
阿里云总监系列课重磅上线!聚焦人工智能、弹性计算、数据库等热门领域,首次集齐12位阿里云技术高管,耗时半年精心打磨,从理论到实践倾囊相授,从零开始绘制技术大牛成长路径,限时直播课程免费报名中!
作者: 云攻略小攻
原文链接
本文为云栖社区原创内容,未经允许不得转载。
「深度学习福利」大神带你进阶工程师,立即查看>>>
随着传统工业巨头的衰落和新兴“数字原生”企业的崛起,企业的竞争力正在被重新定义。对制造企业来说,硬件产品和实体资产已经不再是企业竞争力的必然保证。制造企业开始重新审视和定义自身的竞争力,寻找新的增长动能。
当下,我国工业转型升级迫在眉睫,工业互联网便是其间不可忽视的新兴信息技术力量。将其与制造业深度融合,可以为传统制造企业提供转型的新基础设施及应用模式。
8月9日,“2018中国制造业智能服务论坛”在长沙举行,会议聚焦传统制造业信息化转型及智能化发展。Rancher Labs大中华区研发总监江鹏在会议上做了题为《基于容器的工业互联网PaaS平台搭建》的演讲,分享了容器技术能如何助力制造业构建工业互联网PaaS平台,完成信息化、智能化转型。
工业互联网是新工业革命的关键支撑和智能制造的重要基石,选择新兴的Docker容器技术作为底层技术栈是极佳的选择。容器技术是极具颠覆性的计算机资源隔离技术,不仅对CPU、存储的额外开销非常小,还可以实现秒级的开启和关闭。以Docker为主的容器技术和Kubernetes为主的容器编排工具的逐渐成熟,越来越多的工具通过容器封装、分发和运行。 容器化,不可谓不是边缘计算、搭建工业互联网PaaS平台的新方向。
Rancher是一个开源的企业级Docker与Kubernetes管理平台,是业界首个且唯一可以管理所有云上、所有发行版、所有Kubernetes集群的平台,创造性地解决了生产环境中企业用户可能面临的基础设施不同的困境。Rancher执行统一的安全策略,且拥有简洁直观的界面风格及操作体验,同时还提供了企业应用服务目录、实时监控和告警、日志以及CI/CD Pipeline等一系列拓展功能,改善了历史遗留已久的Kubernetes原生UI易用性不佳以及学习曲线陡峭的问题,给企业在生产环境中落地Kubernetes提供更加便捷的途径。
Rancher在全球已有9000万次下载和超过20000个生产节点部署,在制造行业也拥有众多的标杆客户案例,助力过丰田、米其林、海尔、Honeywell、东风本田、天合光能、金风科技等众多制造业企业完成Docker与Kubernetes落地、工业互联网PaaS平台搭建、信息化转型。
落地实战分享
「深度学习福利」大神带你进阶工程师,立即查看>>>
为了应对诸如惊人的操作开销、重复的努力、可测试性等微服务通常面临的挑战,以及获得诸如代码解耦,易于横向扩展等微服务带来的好处,ZStack将所有服务包含在单个进程中,称为管理节点,构建一个进程内的微服务架构。
动机
构建一个IaaS软件是很难的,这是一个已经从市场上现存的IaaS软件获得的教训。作为一个集成软件,IaaS软件通常需要去管理复杂的各种各样的子系统(如:虚拟机管理器hypervisor,存储,网络,身份验证等)并且需要组织协调多个子系统间的交互。例如,创建虚拟机操作将涉及到虚拟机管理模块,存储模块,网络模块的合作。由于大多数IaaS软件通常对架构考虑不够全面就急于开始解决一个具体问题,它们的实现通常会演变成:
随着一个软件的不断成长,这个铁板一块的架构(monolithic architecture)将最终变为一团乱麻,以至于没有人可以修改这个系统的代码,除非把整个系统从头构建。这种铁板一块的编程问题是微服务可以介入的完美场合。通过划分整个系统的功能为一个个小的、专一的、独立的服务,并定义服务之间交互的规则,微服务可以帮助转换一个复杂笨重的软件,从紧耦合的、网状拓扑架构,变成一个松耦合的、星状拓扑的架构。
因为服务在微服务中是编译独立的,添加或者删除服务将不会影响整个系统的架构(当然,移除某些服务会导致功能的缺失)。 微服务远比我们已经讨论的内容更多:微服务的确有很多引入注目的优点,尤其是在一个的开发运维 流程(DevOps process)中,当涉及到一个大机构的很多团队时。我们不打算讨论微服务的所有支持和反对意见,我们确定你可以在网上找到大量的相关文章,我们主要介绍一些我们认为对IaaS软件影响深远的特性。
问题
虽然微服务可以解耦合架构,但这是有代价的。阅读Microservices - Not A Free Lunch!和Failing at Microservices会对这句话有更深的理解。在这里,我们重点强调一些我们认为对IaaS软件影响重大的事情。
1. 难以定义服务的边界和重复做功
创建Microservices架构的挑战之一是决定应该把哪一部分的代码定义为服务,一些是非常明显的,比如说,处理主机部分的逻辑代码可以被定义为一个服务。然而,管理数据库交互的代码非常难以决定应不应该被定义为服务。数据库服务可以使得整个架构更加清晰明了,但是这样会导致严重的性能下降。通常,类似于这样的代码可以被定义为库,库可以被各个服务调用。鉴于所有服务一般在互相隔离的目录下开发和维护,创建一个给不同的单一的软件提供接口的虚拟的库,要求开发者必须具有良好的和各个不同组的开发者沟通协调的能力。综上,服务很容易重复造轮子和导致不必要的重复做功。
2. 软件难以部署、升级和维护
服务,尤其是那些分散在不同进程和机器上的,是难以部署和升级的。用户通常必须去花费几天甚至几周去部署一个完整的可运行的系统,并害怕升级一个已经构建好的稳定的系统。尽管一些类似puppet的配置管理软件一定程度上缓解了这个问题,用户依旧需要克服陡峭的学习曲线去掌握这些配置工具,仅仅是为了部署或者升级一个软件。管理一个云是非常困难的,努力不应该被浪费在管理这些原本应该使生活更轻松的软件上。 服务的数量确实很重要:IaaS软件通常有许许多多的服务。拿著名的openstack举个例子,为了完成一个基础的安装你将需要:Nova, Cinder, Neutron, Horizon, Keystone, Glance。除了nova是在每台主机都需要部署的,如果你想要4个实例(instances),并且每个服务运行在不同机器上,你需要去操纵20台服务器。虽然这种人造的案例将不太可能真实地发生,它依旧揭示了管理相互隔离的服务的挑战。
3. 零散的配置
运行在不同服务器上的服务,分别维护着它们散乱在系统各个角落的配置副本。在系统范围更新配置的操作通常由临时特定的脚本完成,这会导致由不一致的配置产生的令人费解的失败。
4. 额外的监控努力
为了跟踪系统的健康状况,用户必须付出额外的努力去监控每一个服务实例。这些监控软件,要么由第三方工具搭建,要么服务自身维护,仍然受到和微服务面临的问题所类似的问题的困扰,因为它们仍然是以分布式的方式工作的软件。
5. 插件杀手
插件这个词在微服务的世界中很少被听到,因为每个服务都是运行在不同进程中一个很小的功能单元(function unit);传统的插件模式(参考The Versatile Plugin System)目标是把不同的功能单元相互挂在一起,这在微服务看来是不可能的,甚至是反设计模式的。然而,对于一些很自然的,要在功能单元间强加紧密依赖的业务逻辑,微服务可能会让事情变得非常糟糕,因为缺乏插件支持,修改业务逻辑可能引发一连串服务的修改。
所有的服务都在一个进程
意识到上述的所有问题,以及这么一个事实,即一个可以正常工作的IaaS软件必须和所有的编排服务一起运行之后,ZStack把所有服务封装在单一进程中,称之为管理节点。除去一些微服务已经带来的如解耦架构的优点外,进程内的微服务还给了我们很多额外的好处:
1. 简洁的依赖
因为所有服务都运行在同一进程内,软件只需要一份支持软件(如:database library, message library)的拷贝;升级或改变支持库跟我们对一个单独的二进制应用程序所做的一样简单。
2. 高可用,负载均衡和监控
服务可以专注于它们的业务逻辑,而不受各种来自于高可用、负载均衡、监控的干扰,这一切只由管理节点关心;更进一步,状态可以从服务中分离以创建无状态服务,详见ZStack's Scalability Secrets Part 2: Stateless Services。
3. 中心化的配置
由于在一个进程中,所有的服务共享一份配置文件——zstack.properties;用户不需要去管理各种各样的分散在不同机器上的配置文件。
4. 易于部署、升级、维护和横向扩展
部署,升级或者维护一个单一的管理节点跟部署升级一个单一的应用程序一样容易。横向扩展服务只需要简单的增加管理节点。
5. 允许插件
因为运行在一个单一的进程中,插件可以很容易地被创建,和给传统的单进程应用程序添加插件一样。 进程内的微服务并不是一个新发明: 早在90年代,微软在COM(Component Object Model)中把server定义为远程、本地和进程内三种。这些进程内的server是一些DLLs,被应用程序在同一进程空间内加载,属于进程内的微服务。Peter Kriens在四年前就声称已经定义了一种总是在同一进程内通信的服务,OSGi µservices。 ##服务样例 在微服务中,一个服务通常是一个可重复的业务活动的逻辑表示,是无关联的、松耦合的、自包含的,而且对服务的消费者而言是一个“黑盒子”。简单来说,一个传统的微服务通常只关心特定的业务逻辑,有自己的API和配置方法,并能像一个独立的应用程序一样运行。尽管ZStack的服务共享同一块进程空间,它们拥有这些特点中的绝大多数。ZStack很大程度上是一个使用强类型语言java编写的项目,但是在各个编排服务之间没有编译依赖性,例如:计算服务(包含VM服务、主机服务、区域服务、集群服务)并不依赖于存储服务(包含磁盘服务、基础存储服务、备份存储服务、磁盘快照服务等),虽然这些服务在业务流程中是紧密耦合的。 在源代码中,一个ZStack的服务并不比一个作为一个独立的jar文件构建的maven模块多任何东西。每一个服务可以定义自己的APIs、错误码、全局配置,全局属性和系统标签。例如KVM的主机服务拥有自己的APIs(如下所示)和各种各样的允许用户自己定义配置的方式。 host org.zstack.kvm.APIAddKVMHostMsg HostApiInterceptor KVMApiInterceptor
##通过全局配置来配置 备注:这里只简单展示一小部分,用户可以使用API去更新/获取全局配置,在这里展示一下全局配置的视图。 kvm vm.migrationQuantity A value that defines how many vm can be migrated in parallel when putting a KVM host into maintenance mode.(当一个KVM主机变成维护模式的时候,这里的值定义了可以被并发迁移的虚拟机的数量) 2 java.lang.Integer kvm reservedMemory The memory capacity reserved on all KVM hosts. ZStack KVM agent is a python web server that needs some memory capacity to run. this value reserves a portion of memory for the agent as well as other host applications. The value can be overridden by system tag on individual host, cluster and zone level(所有的KVM主机预留的内存容量。ZStack中的KVM代理运行时是一个需要一部分内存容量去运行的python的web服务器,这个值为代理和其他主机应用程序预留了一部分内存,在单一主机上的、集群上的、区域上的系统标签可以覆盖这个值) 512M
通过全局属性配置 备注:以下代码对应zstack.properties文件夹中相应的属性 @GlobalPropertyDefinition public class KVMGlobalProperty { @GlobalProperty(name="KvmAgent.agentPackageName", defaultValue = "kvmagent-0.6.tar.gz") public static String AGENT_PACKAGE_NAME; @GlobalProperty(name="KvmAgent.agentUrlRootPath", defaultValue = "") public static String AGENT_URL_ROOT_PATH; @GlobalProperty(name="KvmAgent.agentUrlScheme", defaultValue = "http") public static String AGENT_URL_SCHEME; }
##通过系统标签配置 备注:以下代码对应数据库中相应的系统标签。 @TagDefinition public class KVMSystemTags { public static final String QEMU_IMG_VERSION_TOKEN = "version"; public static PatternedSystemTag QEMU_IMG_VERSION = new PatternedSystemTag(String.format("qemu-img::version::%s", QEMU_IMG_VERSION_TOKEN), HostVO.class); public static final String LIBVIRT_VERSION_TOKEN = "version"; public static PatternedSystemTag LIBVIRT_VERSION = new PatternedSystemTag(String.format("libvirt::version::%s", LIBVIRT_VERSION_TOKEN), HostVO.class); public static final String HVM_CPU_FLAG_TOKEN = "flag"; public static PatternedSystemTag HVM_CPU_FLAG = new PatternedSystemTag(String.format("hvm::%s", HVM_CPU_FLAG_TOKEN), HostVO.class); }
##载入服务 服务在Spring的bean的xml文件中声明自身,例如,kvm的部分声明类似于: 管理节点,作为所有服务的容器,将在启动阶段读取它们的XML配置文件,载入每一个服务。 # 总结 在这篇文章中,我们演示了ZStack的进程内微服务架构。通过使用它,ZStack拥有一个非常干净的,松耦合的代码结构,这是创建一个强壮IaaS软件的基础。
「深度学习福利」大神带你进阶工程师,立即查看>>>
别慌,这只是一张贴图
除了404,最让网友们心塞的可能就是这张图了。
据相关研究表明:当页面加载时间从 1 秒到 3 秒,跳出的机会增加了30%左右。1s到5s的机会增加到90%,如果你的网站需要10s的加载,跳出的机会将会超过120%。(这里的120%不是指来10个人,走12个人,是用户流失增长率的意思)所以,在这个“用户体验为王”的时代,应用性能监控已经成为运维管理的重中之重。
一、查找导致 “慢” 的原因。
网站卡顿、页面加载慢是互联网应用常见的问题之一,这类问题的排查和解决并不容易,会花费运维人员大量的时间和精力。通常原因有以下三个:
» 应用链路太长,无从下手。
从前端页面到后台网关,从Web应用服务器到后台数据库,任何一个环节的问题都有可能导致请求整体卡顿,到底是前端资源加载过慢?还是数据库出了问题?还是新发布的服务端代码有性能问题?出现问题的原因五花八门。
采用“微服务”架构的应用,链路更加复杂。不同组件可能由不同的团队、人员分别维护,加剧了问题排查的难度。
» 日志不全或质量欠佳,现场缺失。
应用日志无疑是排查线上问题的神器,但出现问题的位置往往无法预期,发生了问题通常会发现日志信息不全,因为我们不可能在每一个有可能出现问题的地方打印日志。
“慢”的定义偏主观,“慢”有时候往往也是偶发现象。真正要捕捉到“慢”的那一行代码,我们往往需要记录每一次调用,不放过每一行代码,但这样的做法代价太大。
» 监控不足,出现问题为时已晚。
业务发展快、迭代速度更快,会导致业务系统频繁修改接口、增加依赖、代码质量恶化。如果没有一个完善的监控体系,能够对应用的每一个接口的性能进行全自动的监控,对出现问题的调用进行自动的记录,等用户反馈问题再来解决,本身就已经太迟了。
二、如何 1 分钟定位 “慢” 问题
业务实时监控服务 ARMS(Application Real-Time MonitoringService)是一款阿里云应用性能管理(APM)类的全链路监控产品。ARMS提供了针对Java 应用监控和诊断、车联网实时监控、零售行业实时监控、用户体验监控等场景下全方位的监控功能,包括前端监控、应用监控和自定义监控等功能,快速构建实时的业务监控能力。
第一步:安装Java探针 (如果您的应用托管于EDAS,甚至可以跳过这一步 ) 开通ARMS,并创建应用。 下载Java探针包并解压。 在Java应用启动脚本中增加-javaagent:/{user.workspace}/ArmsAgent/arms-bootstrap-1.7.0-SNAPSHOT.jar-Darms.licenseKey=xxx -Darms.appId=xxx (appId和licenseKey根据页面分配的信息填写) 打开ARMS页面,数据开始上报,验证Java探针安装成功。
第二步:在应用概览中发现“慢”可疑线索
进入ARMS应用拓扑图。在应用概览中我们能够明显地看到今天系统中有“慢SQL”5次。
第三步:浏览并发现“慢接口”
点击接口列表,我们能够一眼看到这个应用提供的所有接口以及这个接口的调用次数和耗时,当然,这些接口都是ARMS的探针自动在程序中发现的,无需做任何配置。
在这些接口中,“慢”接口会被明显标注出来。我们很明显地发现了可疑的慢接口。
选中左侧的调用次数最多的”慢”接口,我们可以从右侧看到这次调用明显是“慢”在数据库的调用上。
第四步:到底“慢在哪一行代码”? 一键定位原因! 光看到接口的耗时还不够,我们需要精准定位“慢”到底出现在哪一行代码。 点击“接口快照”,可以看到这个接口对应的所有接口的快照,快照是对一次调用的全链路调用的完整记录。ARMS探针将用非常小的性能损耗记录每一次调用所经过的代码及耗时,帮助您精准定位“慢”问题。
我们点击某一个调用快照的TraceId,展开即可查看到这次调用具体“慢”在哪一行。从上图中我们可以清晰地看到,在这次耗时705毫秒的调用中,大部分的时间都消耗在了"SELECT * FROMl_employee"这次SQL调用中,这明显是一次全表扫描的操作! 至止,我们已经明确地发现了系统中的一个慢调用的错误根因。并且有充分的依据来指导我们下一步的代码优化工作。我们还可以回到调用接口列表,再逐一打开列表中其他“慢”的调用,逐一解决,相信在ARMS的帮助下,您的网站从此可以远离卡顿的困扰,给用户提供更加流畅的体验。
第五步:防患于未然-- 设置告警
当然,您可以在ARMS的告警设置中对某一个接口或全部接口设置告警,让页面接口出现卡顿时第一时刻通知到您的运维团队。
三、还有哪些网站体验问题?
当然除了网站卡顿、页面加载慢以外,网站还会出现后台报错、页面加载失败、内存泄漏等一系列问题。如何利用ARMS快速解决更多网站疑难杂症,请关注我们的 ARMS 系列文章 - “网站常见问题1分钟定位”。
作者: 中间件小哥
原文链接
本文为云栖社区原创内容,未经允许不得转载。
「深度学习福利」大神带你进阶工程师,立即查看>>>
8月7日,ZStack学堂第二期:探秘ZStack安装部署,与广大ZStack铁粉们见面了,本次课程仍然由ZStack刘松涛老师全程直播和在线答疑,并详细讲解了ZStack在生产环境中实用的安装部署及配置技巧。
讲师介绍
刘松涛,上海交大硕士,前Intel虚拟化高级测试工程师,从事多年虚拟化测试工作,针对KVM、XEN等开源项目测试有丰富经验,对XEN及QEMU社区有突出贡献。目前作为ZStack技术支持负责人,主要负责ZStack云平台的项目落地及技术支持工作。
课程要点
本次课程,松涛老师主要介绍了ZStack最小化安装和常规生产环境的硬件需求,演示了ZStack单节点的安装部署过程,介绍了ZStack在生产环境中的硬盘分区和网络规划的注意事项,最后演示了ZStack云平台的初始化和云主机的创建。
ZStack最低硬件需求——1台PC上云
安装部署ZStack的最低硬件需求是4核CPU+8G内存,这是目前主流的PC机的正常配置,换言之一台PC就可以部署ZStack,在ZStack某客户用例中,就是以一台高配Mac笔记本部署ZStack云平台以支撑业务。
极简部署——六步完成ZStack安装
1. ISO引导——选择安装ZStack
2. 安装模式——选择企业版管理节点模式
3. 分区配置——自动分区或自定义分区
4. 网络主机名配置——配置网卡IP及主机名,由于ZStack与网卡是强相关的,网卡配置错误将导致ZStack安装失败
5. 安装系统——自动安装系统
6. 系统安装完毕——自动安装ZStack
重点干货——生产环境配置技巧
生产环境磁盘配置技巧
生产环境网络配置技巧
平滑升级——5分钟跨版本无缝升级
ZStack推出的产品化云计算的亮点之一是5分钟跨版本无缝升级,用户只需要在官网上自行下载最新版本的ZStack ISO,即可实现在线/离线升级。
更多关于课程的内容请看小编精心准备的超清视频回放: https://v.qq.com/x/page/x0749qgd9ve.html
经典QA
Q1:本地有dhcp分配 想云虚拟机也用本地的dhcp分配实现统一 有好的方案吗?
建议在创建三层网络时,界面上的关闭HCP服务前面的方框勾选,表示后续使用此网络创建的云主机是默认不使用ZStack提供的DHCP服务。
云主机在开机启动时,如果本地存在独立的DHCP服务器,可以由此DHCP服务器分配IP地址,但此IP地址可能与云主机界面上的IP地址不一致。如果本地不存在DHCP服务器,云主机的IP地址也可自行在云主机内部手动指定,手动指定需避免IP地址冲突。
Q2:想了解 推荐的架构 冗余架构 各角色node分布推荐。网络规划推荐
ZStack目前支持管理节点的高可用:
1. 管理节点以云主机的形式运行在超融合环境或共享存储的环境,进行高可用,任意节点断电关机异常,管理节点会自动快速恢复;
2. 管理节点以两台物理机的形式进行物理机高可用,任一节点出现断电关机异常,另一节点会无缝管理整个云平台。
ZStack目前支持以下存储:
1. 本地存储
2. NFS/NAS/SAN存储
3. Ceph存储
支持以下网络结构:
1. 扁平网络
2. 云路由网络
3. VXLAN网络
4. VPC网络
以上各种存储和各种网络均可任意组合,
本地存储冗余可依赖硬件本身的RAID机制,本地存储不支持云主机的高可用。
共享存储可以依赖存储双控和RAID机制,Ceph存储可以依赖多副本机制。共享存储和Ceph存储支持云主机的高可用。
Q3:管理节点是单独的一台虚拟机吗?
管理节点可以以物理机方式单独运行,也可以使用一台虚拟机单独运行,配置要求最低4核8G内存,最低配置只适用于演示环境;
Q4:. 一台主机光模块接口10G 两块网卡做bond 模式汇聚 对端是 两台做了堆叠的交换机 对端交换机端口模式是 ACCESS 还是TRUNK zstack 有管理网段 业务网段 存储网段
一台主机使用10G双网卡,创建bond,模式为mode4(lacp)链路聚合,需要对端交换机将此次主机两张网卡作为聚合即可(lacp);
如果使用扁平网络novlan场景下,交换端口模式可以设置为access口,如果是有多vlan隔离场景下将对端交换机端口模式设置为Trunk口,配置对应vlan ID通过即可;
ZStack分别有管理网络(管理各个物理机的网络)、业务网络(承载业务VM所使用的网络)、存储网络(在使用分布式存储ceph场景下的万兆存储网络或共享存储的万兆存储网络,存储之间内部数据交换,可以无须上联);当环境有限只有一张网卡时候,可以使用三网合一场景(性能会受到网卡带宽瓶颈);
Q5: zstack 多台计算机节点 多台存储节点 安装完zstack 后初始化设置的 时候 如何设置呀
安装完zstack管理节点后,可以根据提示打开管理UI界面,登录管理页面(默认用户名密码为admin password),根据向导完成平台初始化,多台计算可以添加到同一集群或者创建单独集群使用(服务器CPU型号不一致场景),多台存储可以添加为不同的主存储,挂载集群使用;
「深度学习福利」大神带你进阶工程师,立即查看>>> 阿里妹导读:本文是一个理论过度到实践的典型案例,借助程序员经常遇到的一个问题——网络为什么不通,来具体说明怎么将书本上的死知识真正变成我们解决问题的能力。
大学学到的基本概念
我相信你脑子里关于网络基础知识的概念都在下面这张图中。知识内容有点乱,感觉都认识,又都模模糊糊,更谈不上将内容转化成生产力或是用来解决实际问题了。这是因为知识没有贯通、没有实践、没有组织。
上图中知识点的作用在RFC1180[1]中讲得无比通俗易懂了。看第一遍的时候也许你就看懂了,但是一个月后又忘记了。其实这些东西我们在大学也学过,但还是忘了(能够理解,缺少实操环境和条件),或者碰到问题才发现之前看懂了的东西其实没懂。
所以接下来我们将示范书本知识到实践的贯通过程,希望把网络概念之间的联系通过实践来组织起来。
还是从一个问题入手
最近的环境碰到一个网络ping不通的问题,当时的网络链路是(大概是这样,略有简化):
现象 从容器1 ping 物理机2 不通; 从物理机1上的 容器2 ping物理机2 通; 同时发现即使是通的,有的容器 ping物理机1只需要0.1ms,有的容器需要200ms以上(都在同一个物理机上),不合理; 所有容器 ping 其它外网IP(比如百度)反而是通的。
这个问题扯了一周才解决是因为容器的网络是我们自己配置的,交换机我们没有权限接触,由客户配置。出问题的时候都会觉得自己没问题对方有问题,另外就是对网络基本知识认识不够,所以都觉得自己没问题而不去找证据。
这个问题的答案在大家看完本文的基础知识后会总结出来。
解决这个问题前大家先想想,假如有个面试题是:输入 ping IP 后敲回车,然后发生了什么?
复习一下大学课本中的知识点
要解决一个问题你首先要有基础知识,在知识欠缺的情况下就算逻辑再好、思路再清晰、智商再高,也不一定有效。
route 路由表
假如你在这台机器上ping 172.17.0.2 ,根据上面的route表得出 172.17.0.2这个IP符合下面这条路由:
这条路由规则,那么ping 包会从docker0这张网卡发出去。
但是如果是ping 1.1.4.4 根据路由规则就应该走eth0这张网卡而不是docker0了。接下来就要判断目标IP是否在同一个子网了。
ifconfig
首先来看看这台机器的网卡情况:
这里有三个网卡和三个IP,三个子网掩码(netmask)。根据目标路由走哪张网卡,得到这个网卡的子网掩码,来计算目标IP是否在这个子网内。
arp协议
网络包在物理层传输的时候依赖的mac 地址而不是上面的IP地址,也就是根据mac地址来决定把包发到哪里去。
arp协议就是查询某个IP地址的mac地址是多少,由于这种对应关系一般不太变化,所以每个os都有一份arp缓存(一般15分钟过期),也可以手工清理,下面是arp缓存的内容:
进入正题,回车后发生什么?
有了上面的基础知识打底,我们来思考一下 ping IP 到底发生了什么。
首先 OS 的协议栈需要把ping命令封成一个icmp包,要填上包头(包括src-IP、mac地址),那么OS先根据目标IP和本机的route规则计算使用哪个interface(网卡),确定了路由也就基本上知道发送包的src-ip和src-mac了。每条路由规则基本都包含目标IP范围、网关、MAC地址、网卡这样几个基本元素。
如果目标IP和本机使用的IP在同一子网
如果目标IP和本机IP是同一个子网(根据本机ifconfig上的每个网卡的netmask来判断是否是同一个子网——知识点:子网掩码的作用),并且本机arp缓存没有这条IP对应的mac记录,那么给整个子网的所有机器广播发送一个 arp查询,比如我ping 1.1.3.42,然后tcpdump抓包首先看到的是一个arp请求:
上面就是本机发送广播消息,1.1.3.42的mac地址是多少?很快1.1.3.42回复了自己的mac地址。 收到这个回复后,先缓存起来,下个ping包就不需要再次发arp广播了。 然后将这个mac地址填写到ping包的包头的目标Mac(icmp包),然后发出这个icmp request包,按照mac地址,正确到达目标机器,然后对方正确回复icmp reply(对方回复也要查路由规则,arp查发送方的mac,这样回包才能正确路由回来,略过)。
来看一次完整的ping 1.1.3.43,tcpdump抓包结果:
我换了个IP地址,接着再ping同一个IP地址,arp有缓存了就看不到arp广播查询过程了。
如果目标IP不是同一个子网
arp只是同一子网广播查询,如果目标IP不是同一子网的话就要经过本IP网关进行转发(知识点:网关的作用)。如果本机没有缓存网关mac(一般肯定缓存了),那么先发送一次arp查询网关的mac,然后流程跟上面一样,只是这个icmp包发到网关上去了(mac地址填写的是网关的mac)。
从本机1.1.3.33 ping 11.239.161.60的过程,因为不是同一子网按照路由规则匹配,根据route表应该走1.1.15.254这个网关,如下截图:
首先是目标IP 11.239.161.60 符合最上面红框中的路由规则,又不是同一子网,所以查找路由规则中的网关1.1.15.254的Mac地址,arp cache中有,于是将 0c:da:41:6e:23:00 填入包头,那么这个icmp request包就发到1.1.15.254上了,虽然包头的mac是 0c:da:41:6e:23:00,但是IP还是 11.239.161.60。
看看目标IP 11.239.161.60 真正的mac信息(跟ping包包头的Mac是不同的):
这个包根据Mac地址路由到了网关上。
网关接下来怎么办?
为了简化问题,假设两个网关直连
网关收到这个包后(因为mac地址是它的),打开一看IP地址是 11.239.161.60,不是自己的,于是继续查自己的route和arp缓存,发现11.239.161.60这个IP的网关是11.239.163.247,于是把包的目的mac地址改成11.239.163.247的mac继续发出去。
11.239.163.247这个网关收到包后,一看 11.239.161.60是自己同一子网的IP,于是该arp广播找mac就广播,cache有就拿cache的,然后这个包才最终到达目的11.239.161.60上。
整个过程中目标mac地址每一跳都在变,IP地址不变,每经过一次MAC变化可以简单理解成一跳。
实际上可能要经过多个网关多次跳跃才能真正到达目标机器。
目标机器收到这个icmp包后的回复过程一样,略过。
arp广播风暴和arp欺骗
广播风暴:如果一个子网非常大,机器非常多,每次arp查询都是广播的话,也容易因为N*N的问题导致广播风暴。
arp欺骗:同样如果一个子网中的某台机器冒充网关或者其他机器,当收到arp广播查询的时候总是把自己的mac冒充目标机器的mac发给你,然后你的包先走到他,再转发给真正的网关或者目标机器,所以在里面动点什么手脚,看看你发送的内容都还是很容易的。
讲完基础知识再来看开篇问题的答案
读完上面的基础知识相信现在我们已经能够回答 ping IP 后发生了什么。这些已经足够解决99%的程序员日常网络中网络为什么不通的问题了。但是前面的问题比这个要稍微复杂一点,还是依靠这些基础知识就能解决——这是基础知识的威力。
现场网络同学所做的一些其它测试:
怀疑不通的IP所使用的mac地址冲突,在交换机上清理了交换机的arp缓存,没有帮助,还是不通;
新拿出一台物理机配置上不通的容器的IP,这是通的,所以负责网络的同学坚持是容器网络的配置导致了问题。
对于1能通,我认为这个测试不严格,新物理机所用的mac不一样,并且所接的交换机口也不一样,影响了测试结果。
祭出万能手段——抓包
抓包在网络问题中是万能的,但是第一次容易被tcpdump抓包命令的众多参数吓晕,不去操作你永远上不了手,差距也就拉开了,你看差距有时候只是你对一条命令的执行。
在物理机2上抓包:
这个抓包能看到核心证据,ping包有到达物理机2,同时物理机2也正确回复了(mac、ip都对)。
同时在物理机1上抓包(抓包截图略掉)只能看到ping包出去,回包没有到物理机1(所以回包肯定不会回到容器里了)。
到这里问题的核心在交换机没有正确地把物理机2的回包送到物理机1上面,同时观察到的不正常延时都在网关那一跳:
最终的原因
最后在交换机上分析包没正确发到物理机1上的原因跟客户交换机使用了HSRP(热备份路由器协议,就是多个交换机HA高可用,也就是同一子网可以有多个网关的IP),停掉HSRP后所有IP容器都能通了,并且前面的某些容器延时也恢复正常了。
通俗点说就是HSRP把回包拐跑了,有些回包拐跑了又送回来了(延时200ms那些)
至于HSRP为什么会这么做,要厂家出来解释了。这里关键在于能让客户认同问题出现在交换机上还是前面的抓包证据充分,无可辩驳。实际中我们都习惯不给证据就说:我的程序没问题,就是你的问题。这样表述没有一点意义,我们是要拿着证据这么说,对方也好就着证据来反驳,这叫优雅地甩锅。
网络到底通不通是个复杂的问题吗?
讲这个过程的核心目的是除了真正的网络不通,有些是服务不可用了也怪网络。很多现场的同学根本讲不清自己的服务(比如80端口上的tomcat服务)还在不在,网络通不通,是网络不通呢还是服务出了问题。一看到SocketTimeoutException 就想把网络同学抓过来羞辱两句:网络不通了,网络抖动导致我的程序异常了(网络抖动是个万能的扛包侠)。
实际这里涉及到四个节点(以两个网关直连为例),srcIP -> src网关 -> dest网关 -> destIP。如果ping不通(也有特殊的防火墙限制ping包不让过的),那么在这四段中分段ping(二分查找程序员应该最熟悉了)。 比如前面的例子就是网关没有把包转发回来。
抓包看ping包有没有出去,对方抓包看有没有收到,收到后有没有回复。
ping自己网关能不能通,ping对方网关能不能通。
接下来说点跟程序员日常相关的
如果网络能ping通,服务无法访问
那么尝试telnet IP port 看看你的服务是否还在监听端口,在的话再看看服务进程是否能正常响应新的请求。有时候是进程死掉了,端口也没人监听了;有时候是进程还在但是假死了,所以端口也不响应新的请求了,还有的是TCP连接队列满了不能响应新的连接。
如果端口还在也是正常的话,telnet应该是好的:
假如我故意换成一个不存在的端口,目标机器上的OS直接就拒绝了这个
连接(抓包的话一般是看到reset标识):
一个SocketTimeoutException,程序员首先怀疑网络丢包的Case
当时的反馈应用代码抛SocketTimeoutException,怀疑网络问题: 业务应用连接Server 偶尔会出现超时异常; 业务很多这样的异常日志:[Server SocketTimeoutException]
检查一下当时的网络状态非常好,出问题时间段的网卡的量信息也非常正常:
上图是通过sar监控到的9号 v24d9e0f23d40 这个网卡的流量,看起来也是正常,流量没有出现明显的波动。
为了监控网络到底有没有问题,接着在出问题的两个容器上各启动一个http server,然后在对方每1秒钟互相发一次发http get请求访问这个http server,基本认识告诉我们如果网络丢包、卡顿严重,那么我这个http server的监控日志时间戳也会跳跃,如果应用是因为网络出现异常那么我启动的http服务也会出现异常——宁愿写个工具都不背锅(主要是背了锅也不一定能解决掉问题)。
从实际监控来看,应用出现异常的时候我的http服务是正常的(写了脚本判断日志的连续性):
这也强有力地证明了网络没问题,所以写业务代码的同学一门心思集中火力查看应用的问题。后来的实际调查发现是应用假死掉了(内部线程太多,卡死了),服务端口不响应请求了。
如果基础知识缺乏一点那么甩过来的这个锅网络是扛不动的,同时也阻碍了问题的真正发现。
TCP协议通讯过程跟前面ping一样,只是把ping的icmp协议换成TCP协议,也是要先根据route,然后arp。
总结
网络丢包、卡顿、抖动很容易做扛包侠,只有找到真正的原因解决问题才会更快,否则在错误的方向上怎么发力都不对。准确的方向要靠好的基础知识和正确的逻辑以及证据来支撑,而不是猜测。 基础知识是决定你能否干到退休的关键因素; 有了基础知识不代表你能真正转化成生产力; 越是基础,越是几十年不变的基础越是重要; 知识到灵活运用要靠实践,同时才能把知识之间的联系建立起来; 简而言之缺的是融会贯通和运用; 做一个有礼有节的甩包侠; 在别人不给证据愚昧甩包的情况下你的机会就来了。
留几个小问题: server回复client的时候是如何确定回复包中的src-ip和dest-mac的?一定是请求包中的dest-ip当成src-ip吗? 上面问题中如果是TCP或者UDP协议,他们回复包中的src-ip和dest-mac获取会不一样吗? 既然局域网中都是依赖Mac地址来定位,那么IP的作用又是什么呢?
本文作者:蛰剑
原文链接
本文为云栖社区原创内容,未经允许不得转载。
「深度学习福利」大神带你进阶工程师,立即查看>>>
摘要: Eric Evans的《领域驱动设计》问世已经14年之久,到今天几乎所有业务团队都或多或少有涉及DDD。然而较真起来会发现,认真遵循DDD设计原则的团队仅是少数,多数团队的现状依然是: **数据库关系=模型。** # 贫血模型 DDD崇尚充血模型,对以关系型数据库为中心的贫血模型则甚至可以用鄙夷形容。Martin Fowler在《企业应用架构模式》书中有系统谈过贫血模型, > 他定义“
Eric Evans的《领域驱动设计》问世已经14年之久,到今天几乎所有业务团队都或多或少有涉及DDD。然而较真起来会发现,认真遵循DDD设计原则的团队仅是少数,多数团队的现状依然是:
数据库关系=模型。
贫血模型
DDD崇尚充血模型,对以关系型数据库为中心的贫血模型则甚至可以用鄙夷形容。Martin Fowler在《企业应用架构模式》书中有系统谈过贫血模型, 他定义“贫血模型”是反模式,简单系统使用它开发没问题,而对于复杂业务,业务逻辑、各种状态散布在大量的函数中,维护扩展的成本会变得很高。
假设有业务场景--向购物车添加商品,使用贫血模型代码如下: public class CartLine{ @Getter @Setter private String skuCode; @Getter @Setter private int buyNo;//数量 } public class CartServiceImpl implements CartService{ public void addLine(String skuCode, int buyNo, ......){ CartLine line= getLine(skuCode, .....) if(line!= null){ line.setBuyNo(buyNo); update(line); }else{ new CartLine insert } } }
绝大多数人都应该会有类似代码的编写经历,最常见在经典三分层架构中的Service层,它本质上就是一个类存储过程,对其执行过程做翻译,就是一个三条SQL组成的业务逻辑: CartLine line= select * from cart_line where sku_code= #{skuCode} if(line!= null){ update cart_line set buy_no= #{buyNo} where sku_code= #{skuCode} }else{ insert cart_line values(xxxx) }
业务处理像是在有序执行一条条sql,老外给它取了一个好听的名字叫事务脚本。事务脚本是非常典型的过程式表述,它近似是串联sql完成一段完整的业务,可以用个数学公式来定义即 事务脚本=∑fi ,fi代指一条sql。
充血模型
假设内存无限大且永不宕机,即已经没有持久化必要,换句话说完全可以不使用数据库,此时应该如何编写代码? 是使用与现实世界的活动实体做连接、特征和行为封装在一起,职责明确、逻辑合理分布的有状态对象,再按场景将合适类联系起来? 还是使用仅映射活动实体特征的pojo,按场景忠实反应发生过程依次get/set操作pojo属性?
Jdk以及各类优秀中间件都是以内存操作为主,可以参考它们的选择:即便是主推pojo规范的ejb都没有选择贫血模型,反而是极度充血-- 暴露一组行为给外部,由外力驱动对象变化。
数据持久化应只被当成是程序的暂停而非结束,对暂停而言,下一次再执行时需要忠实还原对象的上次执行后状态,而对结束则下一次是一个新的开始。即 load; do; 和 new; setter/getter; persist 的区别。如果从这个角度出发,对象就变得近似是常驻在内存。
在Vaughn Vernon的《实现领域驱动设计》中关于“六边形架构”如何在领域实践应用中已经阐述很清楚:
数据库仅仅只是Domain Model的右向适配(被驱动者)。
数据库只是持久化手段,是一种基础设施,不该作为指导程序运行的模型。写代码时要时刻保持一种警惕,如果把关系型数据库替换成json、普通文本或者无schema的nosql数据库,要如何保证逻辑层的无感?
正确的方法是以对象和对象联系而非数据库表关系作为指导程序运行的基础。一次完整的业务操作由各实体对象行为协同完成,结果最终会反映在内存中各对象实例的内在属性上。这样无论怎么修改持久化方案,都只需要改变与特定持久化方案的适配策略。 某逆向交替系统,其逆向状态是记录在正向交易上的,
| order_id | order_status |pay_fee|item_id|refund_amount |refund_status|attributes|...... | refund_amount和refund_status分别代表逆向退款金额以及退款状态。很显然,这样的表设计会导致两个问题:1) 无法多次逆向,前一次状态在下一次发起后被覆盖,即逆向无法追溯;2)逆向需要更新交易订单属性,方式是调用交易接口更新,因此某些情况下可能会有乐观锁问题-- 逆向更新了锁版本导致交易再去更新失败。
在小规模试跑阶段,业务上会严格限制一笔订单一次逆向,同时对于乐观锁问题采用多次重试机制,因此问题并不明显。逐渐的业务开始起来,首先业务量大之后重试导致的性能问题凸显-- 在加事务的情况下,数据库连接是一直持有直到提交或回滚,多次重试相当于增加了几倍持有连接时间,因此会明显明显降低数据库吞吐;其次,对于不能多次逆向合作伙伴也开始有反弹。因此交易和逆向的表拆分变得势在必行。
因为逆向在设计时使用了充血模型+六边形架构,实际上迁移并没有很大工作量,只是重新建了表,然后对数据库适配进行修改,将输出表由A指向B。
而如果使用贫血模型,在对表结构做了较大变更后,则一定会要修改逻辑代码。可以使用事务脚本的公式做个逆向推导:
表变化=sql变化=事务脚本(逻辑执行)变化。
小结
贫血模型的本质是反oo的,是数据库关系对代码的入侵,是先假定关系已经存在再想办法把执行逻辑映射到关系上,最终收口就落在了数据库,而非程序本身,各service最终都会变成一根冗长枯燥难读的“面条”。这是”修改一处,全量回归“的悲剧源头,也是代码写久后枯燥、无聊、觉得都是重复劳动的源头,过程式代码是不需要设计更不需要模式的。
作者: 鹰波
原文链接
本文为云栖社区原创内容,未经允许不得转载。
「深度学习福利」大神带你进阶工程师,立即查看>>>
摘要: AIOps英文全称是Algorithmic IT Operations,是基于算法的IT运维。AIOps是运维领域上的热点,然而在满足业务SLA的前提下,如何提升平台效率和稳定性及降低资源成本成为AIOps面临的问题和挑战。
背景
随着搜索业务的快速发展,搜索系统都在走向平台化,运维方式在经历人肉运维,脚本自动化运维后最终演变成DevOps。但随着大数据及人工智能的快速发展,传统的运维方式及解决方案已不能满足需求。
基于如何提升平台效率和稳定性及降低资源,我们实现了在线服务优化大师hawkeye及容量规划平台torch。经过几年的沉淀后,我们在配置合理性、资源合理性设置、性能瓶颈、部署合理性等4个方面做了比较好的实践。下面具体介绍下hawkeye和torch系统架构及实现。
AIOps实践及实现
hawkeye——智能诊断及优化
系统简介
hawkeye是一个智能诊断及优化系统,平台大体分为三部分:
1.分析层,包括两部分:
1) 底层分析工程hawkeye-blink:基于Blink完成数据处理的工作,重点是访问日志分析、全量数据分析等,该工程侧重底层的数据分析,借助Blink强大的数据处理能力,每天对于搜索平台所有Ha3应用的访问日志以及全量数据进行分析。
2) 一键诊断工程hawkeye-experience:基于hawkeye-blink的分析结果进行更加贴近用户的分析,比如字段信息监测,包括字段类型合理性,字段值单调性监测等,除此之外还包括但不限于kmon无效报警、冒烟case录入情况、引擎降级配置、内存相关配置、推荐行列数配置以及切换时最小服务行比例等检测。
hawkeye-experience工程的定位是做一个引擎诊断规则中台,将平时运维人员优化维护引擎的宝贵经验沉淀到系统中来,让每一个新接入的应用可以快速享受这样的宝贵经验,而不是通过一次次的踩坑之后获得,让每位用户拥有一个类似智能诊断专家的角色来优化自己的引擎是我们的目标,也是我们持续奋斗的动力,其中hawkeye-experience的数据处理流程图如下所示:
2.web层:提供hawkeye分析结果的各种api以及可视化的监控图表输出。
3.service层:提供hawkeye分析与优化api的输出。
基于上述架构我们落地的诊断及优化功能有: 资源优化:引擎Lock内存优化(无效字段分析)、实时内存优化等; 性能优化:TopN慢query优化、buildservice资源设置优化等; 智能诊断:日常化巡检、智能问答等。
引擎Lock内存优化
对于Ha3引擎,引擎字段是分为倒排(index)索引、正排(attribute)索引和摘要(summary)索引的。引擎的Lock策略可以针对这三类索引进行Lock或者不Lock内存的设置,Lock内存好处不言而喻,加速访问,降低rt,但是试想100个字段中,如果两个月只有50个访问到了,其他字段在索引中压根没访问,这样会带来宝贵内存的较大浪费,为此hawkeye进行了如下分析与优化,针对头部应用进行了针对性的索引瘦身。下图为Lock内存优化的过程,累计节省约数百万元。
慢query分析
慢query数据来自应用的访问日志,query数量和应用的访问量有关,通常在千万甚至亿级别。从海量日志中获取TopN慢query属于大数据分析范畴。我们借助Blink的大数据分析能力,采用分治+hash+小顶堆的方式进行获取,即先将query格式进行解析,获取其查询时间,将解析后的k-v数据取md5值,然后根据md5值做分片,在每一个分片中计算TopN慢query,最后在所有的TopN中求出最终的TopN。对于分析出的TopN慢query提供个性化的优化建议给用户,从而帮助用户提升引擎查询性能,间接提高引擎容量。
一键诊断
我们通过健康分衡量引擎健康状态,用户通过健康分可以明确知道自己的服务健康情况,诊断报告给出诊断时间,配置不合理的简要描述以及详情,优化的收益,诊断逻辑及一键诊断之后有问题的结果页面如下图所示,其中诊断详情页面因篇幅问题暂未列出。
智能问答
随着应用的增多,平台遇到的答疑问题也在不断攀升,但在答疑的过程中不难发现很多重复性的问题,类似增量停止、常见资源报警的咨询,对于这些有固定处理方式的问题实际上是可以提供chatOps的能力,借助答疑机器人处理。目前hawkeye结合kmon的指标和可定制的告警消息模板,通过在报警正文中添加诊断的方式进行这类问题的智能问答,用户在答疑群粘贴诊断正文,at机器人即可获取此次报警的原因。
torch-容量治理优化
hawkeye主要从智能诊断和优化的视角来提升效率增强稳定性,torch专注从容量治理的视角来降低成本,随着搜索平台应用的增多面临诸如以下问题,极易造成资源使用率低下,机器资源的严重浪费。
1)业务方申请容器资源随意,造成资源成本浪费严重,需要基于容器成本耗费最小化明确指导业务方应该合理申请多少资源(包括cpu,内存及磁盘)或者资源管理对用户屏蔽。
2)业务变更不断,线上真实容量(到底能扛多少qps)大家都不得而知,当业务需要增大流量(譬如各种大促)时是否需要扩容?如果扩容是扩行还是增大单个容器cpu规格?当业务需要增大数据量时是拆列合适还是扩大单个容器的内存大小合适? 如此多的问号随便一个都会让业务方蒙圈。
解决方案
如下图所示,做容量评估拥有的现有资源,是kmon数据,线上系统的状态汇报到kmon,那直接拿kmon数据来分析进行容量评估可不可以呢?
实际实验发现是不够的,因为线上有很多应用水位都比较低,拟合出来高水位情况下的容量也是不够客观的,所以需要个压测服务来真实摸底性能容量,有了压测接下来需要解决的问题是压哪?压线上风险比较大,压预发预发的资源有限机器配置差没法真实摸底线上,所以需要克隆仿真,真实克隆线上的一个单例然后进行压测,这样既能精准又安全。有了压测数据,接下来就是要通过算法分析找到最低成本下的资源配置,有了上面的几个核心支撑,通过任务管理模块将每个任务管理起来进行自动化的容量评估。
以上是我们的解决方案,接下来会优先介绍下整体架构,然后再介绍各核心模块的具体实现。
系统架构
如图,从下往上看,首先是接入层。平台要接入只需要提供平台下各应用的应用信息及机群信息(目前接入的有tisplus下的ha3和sp),应用管理模块会对应用信息进行整合,接下来任务管理模块会对每个应用抽象成一个个的容量评估任务。
一次完整的容量评估任务的大概流程是:首先克隆一个单例,然后对克隆单例进行自动化压测压到极限容量,压测数据和日常数据经过数据工厂加工将格式化后的数据交由决策中心,决策中心会先用压测数据和日常数据通过算法服务进行容量评估,然后判断收益,如果收益高会结合算法容量优化建议进行克隆压测验证,验证通过将结果持久化保存,验证失败会进行简单的容量评估(结合压测出的极限性能简单评估容量),容量评估完成以及失败决策中心都会将克隆及压测申请的临时资源清理不至于造成资源浪费。
最上面是应用层,考虑到torch容量治理不仅仅是为tisplus定制的,应用层提供容量大盘,容量评估,容量报表及收益大盘,以便其它平台接入嵌用,另外还提供容量API供其它系统调用。
容量评估也依赖了搜索很多其它系统,maat, kmon, hawkeye,drogo,成本系统等整个形成了一道闭环。
架构实现
克隆仿真
克隆仿真简单地理解就是克隆线上应用的一个单例,ha3应用就是克隆完整一行,sp就是克隆出一个独立服务。随着搜索hippo这大利器的诞生,资源都以容器的方式使用,再加上suez ops及sophon这些DevOps的发展,使得快速克隆一个应用成为可能,下面给出克隆管控模块的具体实现:
克隆目前分为浅克隆和深度克隆,浅克隆主要针对ha3应用通过影子表的方式直接拉取主应用的索引,省掉build环节加快克隆速度,深度克隆就是克隆出来的应用需要进行离线build。
克隆的优势明显: 服务隔离,通过压测克隆环境可以间接摸底线上的真实容量。 资源优化建议可以直接在克隆环境上进行压测验证。 克隆环境使用完,直接自动释放,不会对线上资源造成浪费。
压测服务
考虑到日常的kmon数据大部分应用缺少高水位的metrics指标,并且引擎的真实容量也只有通过实际压测才能获得,因此需要压测服务,前期调研了公司的亚马逊压测平台及阿里妈妈压测平台,发现不能满足自动压测的需求,于是基于hippo我们开发了自适应增加施压woker的分布式压测服务。
算法服务
容量评估的目标就最小化资源成本提高资源利用率,所以有个先决条件,资源得可被成本量化,成本也是搜索走向平台化衡量平台价值的一个重要维度,于是我们搜索这边跟财务制定了价格公式,也就拥有了这个先决条件,和算法同学经过大量的实验分析发现这个问题可以转换成带约束条件的规划问题,优化的目标函数就是价格公式(里面有内存 cpu磁盘几个变量)约束条件就是提供的容器规格和容器数一定要满足最低的qps 内存和磁盘的需要。
AIOps展望
通过hawkeye诊断优化和torch容量治理在tisplus搜索平台上的落地大大降低了成本提高了效率和稳定性,为将AIOps应用到其它在线系统树立了信心,因此下一步目标就是将hawkeye和torch整合进行AIOps平台化建设,让其它在线服务也都能享受到AIOps带来的福利。因此,开放性,易用性是平台设计首要考虑的两个问题。
为此,接下来会重点进行四大基础库的建设:
运维指标库:将在线系统的日志,监控指标,event和应用信息进行规范整合,让策略实现过程中方便获取各种运维指标。
运维知识库:通过ES沉淀日常答疑积累的问题集及经验,提供检索及计算功能,便于对线上类似问题进行自动诊断及自愈。
运维组件库:将克隆仿真 压测 及算法模型组件化,便于用户灵活选择算法进行策略实现,并轻松使用克隆仿真及压测对优化建议进行有效验证。
运维策略库:通过画布让用户拖拽及写UDP来快速实现自己系统的运维策略,运维指标库,运维知识库及运维组 件库提供了丰富多样的数据及组件,使得运维策略的实现变得足够简单。
基于上述基础设施的建设结合策略便可产出各种运维场景下的数据,全面进行故障处理,智能问答,容量管理及性能优化各种场景的应用。
本文是阿里搜索中台技术系列AIOps实践的分享,搜索中台从0到1建设已经走过了3年,但它离我们心目中让天下没有难用的搜索的远大愿景还离的非常远。在这个前行的道路上一定会充满挑战,无论是业务视角的SaaS化能力、搜索算法产品化、云端DevOps&AIOps,还是业务建站等都将遇到世界级的难题等着我们去挑战。
本文作者:云镭
原文链接
本文为云栖社区原创内容,未经允许不得转载。
「深度学习福利」大神带你进阶工程师,立即查看>>>
摘要 : 本文由阿里视频云高级技术专家空见撰写,主要介绍HTTP2.0的历史、特性、如何使用和使用之后的性能对比验证。
背景介绍
要了解HTTP2.0,先了解一下HTTP超文本传输协议的历史(HyperText Transfer Protocol),这是为了实现互联网上内容传输提出的协议,其历史伴随着互联网的发展。整个HTTP协议发展历程如下:
一句话介绍:
HTTP 0.9:基于GET请求的文本传输协议
HTTPS:安全的HTTP传输协议
HTTP 1.0:增加HTTP头、扩展PUT、POST等方法
HTTP 1.1:长连接、流水线支持,最广泛使用的HTTP传输协议
SPDY:针对HTTP的增强,工作在SSL层之上、HTTP层之下
HTTP 2.0:安全高效的下一代HTTP传输协议
根据W3Techs统计,到现在为止,互联网上前1000万的网站,已经有27.9%支持了HTTP2.0。
HTTP2.0的特性
内容安全(Security),因为HTTP2.0是基于HTTPS的,天然具有安全特性,通过HTTP2.0的特性可以避免单纯使用HTTPS的性能下降。
二进制格式(Binary Support),HTTP1.x的解析是基于文本。HTTP 2.0将所有的传输信息分割为更小的消息和帧,并对它们采用二进制格式编码,基于二进制可以让协议有更多的扩展性,比如引入了帧来传输数据和指令。
多路复用(MultiPlexing),这个功能相当于是长连接的增强,每个request可以随机的混杂在一起,接收方可以根据request的id将request再归属到各自不同的服务端请求里面。另外多路复用中,也支持了流的优先级(Stream dependencies),允许客户端告诉server哪些内容是更优先级的资源,可以优先传输。
Header压缩(Header compression),HTTP请求中header带有大量信息,而且每次都要重复发送,HTTP2.0使用编解码来header的传输,通讯双方各自cache一份header fields表,减少header的开销。
服务端推送(Server push),同SPDY一样,HTTP2.0也具有server push功能。目前,有大多数网站已经启用HTTP2.0,如淘宝 利用chrome控制台可以查看是否启用HTTP2.0:chrome://net-internals/#http2 可以看到当前页面使用HTTP2.0的情况:
如何使用HTTP2.0
目前阿里云CDN已经全面支持HTTP2.0,大部分主流浏览器也已经支持该功能,但是需要服务端改造后才能使用,不过如果你使用了阿里云CDN,源站即便不支持也能够享受HTTP2.0的特性,目前在官网可以自助开启:
1、 开启HTTPS证书 因为HTTP2.0是依赖于HTTPS的,在控制台开启HTTP2.0需要提前开启HTTPS,目前阿里云CDN已经支持免费证书功能,提前打开该功能即可:
2、 开启HTTP2.0功能:
性能对比验证
目前我们提供了一个对比测试工具,可以比较直观的看出来HTTP1.1和HTTP2.0的加载页面的差异,针对180个小图片,HTTP2.0显示了强大的优势,而且越是弱网环境,其加速效果就更明显:
小伙伴也可以通过下面页面,自己体验本地使用HTTP2.0和HTTP1.1的对比效果:
https://http2.cdnpe.com/index.html
HTTP2.0和SPDY的关系
SPDY是Google提出的用来解决老的HTTP协议不足的一些新的方案,可以说是综合了HTTPS和HTTP两者优点并加以改进的传输协议。实践证明SPDY解决了HTTP的一些顽疾,在性能上提升显著,最终IETF(Internet Enginerring Task Force)正式考虑制定HTTP2.0的计划,最后决定以SPDY为基础起草HTTP2.0,SPDY的部分设计人员也被邀请参与了HTTP2.0的设计。
Google的测试表明,页面加载时间相比于HTTP1.x减少了64%:
作者: 樰篱
原文链接
本文为云栖社区原创内容,未经允许不得转载。
「深度学习福利」大神带你进阶工程师,立即查看>>>
数据库对于企业来说至关重要,因此数据库体系结构迁移到容器平台显得尤为必要。本文将介绍如何用Rancher创建产品质量数据库设置,并分析在Rancher高可用和Kubernetes中可供使用的各种选项,给大家设计产品质量数据库提供参考。
**目标:**在本文中,我们将介绍如何运行一个分布式产品质量数据库设置,它由Rancher进行管理,并且保证持久性。为了部署有状态的分布式Cassandra数据库,我们将使用Stateful Sets (有状态集)以及Rancher中的Kubernetes集群。
**先决条件:**假设您已经有一个由云服务商提供的Kubernetes集群。如果您想在Amazon EC2中使用Rancher 2.0创建K8s集群,可以查看Rancher的资源:
https://rancher.com/docs/rancher/v2.x/en/cluster-provisioning/rke-clusters/node-pools/ec2/。
数据库对业务至关重要,无论是数据丢失还是泄露,都会为企业带来严重的风险。操作错误或体系结构故障都可能导致重大事件和资源的损失,这就需要故障转移系统/过程来减少数据丢失的可能。在将数据库体系结构迁移到Kubernetes之前,必须完成在容器体系结构以及裸机上运行数据库集群的成本效益分析对比,这包括评估恢复时间目标(Recovery Time Objective,RTO)以及恢复数据目标(Recovery Point Objective,RPO)的灾难恢复要求。这些分析在面对数据敏感的应用程序是非常重要,尤其当程序需要真正高可用、针对大规模和冗余需要地理分离、以及应用程序恢复要低延迟时。
在下文的步骤中,我们将分析在Rancher高可用和Kubernetes中可供使用的各种选项,给大家设计产品质量数据库提供参考。
A.有状态系统容器架构的缺点
部署在类似Kubernetes的集群中的容器自然是无状态而且短暂的,这意味着它们不会保持固定的身份,并且当发生错误或重新启动时会发生数据丢失和遗忘。在设计分布式数据库环境时,需要提供高可用性以及容错,这对Kubernetes的无状态体系结构提出了挑战,因为无论是复制还是扩展都需要维护下面的状态:
(1)存储;(2)身份;(3)会话;(4)集群角色。
考虑到我们的容器化应用程序,我们马上就可以看出无状态架构面临的挑战,我们的应用程序需要满足一系列的要求:
我们的数据库需要将数据(Data)和事务(Transactions)存储在文件中,这些文件对每个数据库容器来说都是持久且独有的;
数据库应用程序中的每个容器都需要维护一个固定的身份作为数据库节点,以便我们可以通过名称、地址或者索引将流量路由给它;
需要数据库客户端会话来维护状态,为保证一致性,需确保在状态更改之前,读写事务已经终止,而且出现持久性故障时状态转换不受影响。
个数据库节点都需要在其数据库集群中有持久化的角色,比如主机、副本或者分片,除非它们被特定的应用程序的事件更改,或者由于模式更改了而必须更改。
针对这些挑战,目前的解决方案可能是将PersistentVolume附加到我们Kubernetes pods上,它的生命周期独立于使用它的任何一个pod。但是,PersistentVolume不会向集群节点(即父节点、子节点或种子节点)提供一致的角色分配。集群不能保证在整个应用程序的生命周期中维护数据库状态,说的具体一点就是,新的容器会由非确定的随机名称创建,并且pods可以设置在任何时间按照任何的顺序启动、终止或者缩放。所以我们的挑战依然存在。
B.K8s部署分布式数据库的优点
有这么多在Kubernetes集群中部署分布式数据库的挑战,我们是否还值得付出努力呢?Kubernetes开辟了许多优势和可能性,包括管理大量的数据库服务以及常见的自动化操作,从可恢复性、可靠性和可扩展性来支持其生命周期健康。即使在虚拟化环境中,部署数据库集群的所需的时间和成本也远低于部署裸机集群。
Stateful Sets提供了前一节中所述挑战的前进方向。在1.5版本引入了Stateful Sets之后,Kubernetes现在为存储和身份实现了有状态质量,保证了下面的内容:
每个pod都附有一个持久卷,从pod链接到存储,这解决了A中的存储状态问题;
每个pod都以相同的顺序开始并以相反的顺序终止,这解决了A的会话状态问题;
每个pod都有一个唯一且可确定的名称、地址和序号索引,用于解决A中的身份和集群角色问题。
C.部署带有Headless服务的有状态集
注意:这部分我们会使用到kubectl服务。关于如何使用Rancher来部署kubectl服务可以参考这里:
https://rancher.com/docs/rancher/v2.x/en/k8s-in-rancher/kubectl/。
Stateful Set Pods需要headless服务来管理Pods的网络身份。实际上,headless服务具有未定义的集群IP地址,这意味着在服务上没有定义集群IP。相反的,该服务定义具有选择器,当服务被访问的时候,DNS被配置成返回多个地址记录或者地址。此时,服务fqdn将使用相同的选择器映射到服务后面的所有pod IP的所有IP。
现在我们按照这个模板来为Cassandra创建一个Headless服务:
使用get svc命令列出cassandra服务的属性:
用describe svc可以将cassandra服务的属性按照verbose格式输出:
D.为持久卷创建存储类别
在Rancher中,通过本机的Kubernetes API资源、PersistentVolume和PersistentVolumeClaim,我们可以使用各种选项来管理持久存储。Kubernetes中的存储类别告诉了我们哪些存储类别是我们的集群所支持的。我们可以为持久存储设置动态配置来自动创建卷,并将其附加到pod。例如,下面的存储类将AWS作为它的存储提供者,使用类型是gp2,可用区是us-west-2a。
如果需要,还可以创建一个新的存储类,例如:
在创建有状态集时,将根据它的存储类为有状态集pod启动PersistentVolumeClaim。使用动态供应,可以根据PersistentVolumeClaim中请求的存储类为pod动态供应PersistentVolume。
您可也以通过静态供应手动创建持久卷。可以在这里阅读关于静态供应的更多信息:
https://rancher.com/docs/rancher/v2.x/en/k8s-in-rancher/volumes-and-storage/。
注意:对于静态供应,要求它具有与Cassandra服务器中的Cassandra节点数量相同的持久卷数量。
E.创建有状态集
现在我们可以创建有状态集,它将提供我们想要的属性:有序的部署和终止、唯一的网络名称和有状态的处理。我们调用下面命令,启动一个Cassandra服务器:
F.验证有状态集
接着,我们调用下面命令验证是否在Cassandra服务器中部署了有状态集:
在创建了有状态集之后,DESIRED和CURRENT应该是相等的,调用get pods命令来查看经有状态集创建的pods的顺序列表。
在节点创建期间,你可以执行nodetool state来查看Cassandra节点是否启动。
G.有状态集的扩缩容
将F步骤中的设置复制x次,调用缩放命令就可以增加或者减少有状态集的大小。在下面的示例中,我们按照x=3进行操作。
调用get statefulsets可以验证是否有状态集已经部署到了Cassandra服务器上。
再次调用get pods来查看有状态集创建的pods顺序。需要注意的是,在部署Cassandra pods时,它们是按照顺序创建的。
我们可以在5分钟后执行nodetool 状态检查,验证Cassandra节点是否已经加入并且形成了一个Cassandra集群。
一旦nodetool中节点的状态变更为Up/Normal,我们就可以通过调用CQL来执行大量的数据库操作。
H.调用CQL进行数据库访问和操作
当我们看到状态是U/N,我们就可以调用cqlsh来访问Cassandra容器。
I.使用Cassandra作为高可用无状态数据库服务的持久层
在前面的练习中,我们在K8s集群中部署了一个Cassandra服务,并通过PersistentVolume提供持久存储。然后,我们使用有状态集为Cassandra集群提供有状态处理的属性,并将集群扩展到其他节点。我们现在可以在Cassandra集群中使用CQL模式进行数据库访问和操作。CQL模式的优点是,我们可以轻松地使用自然类型和流畅的api实现无缝数据建模,特别是在设计扩展和时间序列数据模型(如欺诈检测)的解决方案中。此外,CQL利用分区和集群keys来提高数据建模场景中的操作速度。
总 结
在本系列文章的下一篇中,我们将探索如何在“数据库即微服务”或无状态数据库中使用Cassandra作为持久层,利用Cassandra独特的体系结构属性并使用Rancher工具集作为起点。然后,我们将分析cassandra驱动的无状态数据库应用程序的操作性能和延迟,并评估其在设计中,边缘和云之间具有低延迟的高可用性服务的使用价值。
通过结合Cassandra和微服务架构,我们可以探索有状态集数据库的替代方案,改善内存SQL数据库(如SAP HANA)容易出现/ifor read/write事务的延迟的问题,以及HTAP工作负载和NoSQL数据库在执行需要多个表查询或复杂过滤器的高级分析时速度较慢的问题。同时,无状态体系结构可以改善数据库因为内存异常而出现的问题。这些问题都可归因于SQL数据库中内存索引和多模型NoSQL数据库中的高内存使用。有了这两个方面的改进,将可以给大规模查询和时间序列建模提供更好的操作性能。
「深度学习福利」大神带你进阶工程师,立即查看>>>
背景说明
公司的整个电商系统搭建在华为云上,根据老总的估计,上线3个月之后日订单量会达到百万级别,保守估计3个月之后总订单个数预计会有5千万。MySQL单表达到千万级别,就会出现明显的性能问题。根据如此规模的数据,当时考虑了2套解决方案:
方案一: 在业务上根据用户ID做拆分,将数据打散放在5台32U128G的华为云RDS上边
方案二: 直接使用华为云的分布式数据库中间件DDM
方案一的好处是,分片算法全部在业务上实现,整个方案都在自己的控制下。后续问题定位,方案修改都会好很多;坏处是,整个方案需要业务代码支撑,访问到做了拆分的数据都需要做特殊处理,代价还是比较大的,而且对开发人员的能力要求很高。后续运维的工作也比较大。
方案二的好处是,直接使用云服务后续不需要担心运维的事情,另外DDM从中间件层屏蔽了分库分表的具体实现,业务可以当做单库来操作,易用性以及对代码的要求、对开发人员的要求都会低了很多。缺点就是,使用了DDM之后,对华为云的粘性会大很多。
综合考虑了两个方案的优缺点,最终选择了方案二,主要是基于对华为云技术能力和后续蓬勃发展的信心。
对DDM做了一定的调研,的确是一个非常不错的分库分表服务。支持超大规模数据,10备于单机数据库的超强性能,百万并发,读写分离,支持平滑扩容等等。。。优点数不胜数~
搭建到华为云之后,一直平稳运行,但是前阵子出了个奇怪的问题,在DDM技术专家的协助下,很快定位了出来,结果是MySQL-JDBC的一个bug导致。作为一个具有打破砂锅问到底、不破楼兰誓不还的程序员,决定对MySQL的相关参数做个详细的分析,免得从一个坑里边爬出来又进了另外一个。
Loadbalance模式说明
为了提供高性能,百万并发,DDM自身是以无状态的集群形式对外提供的。内部怎么做的我们不清楚,能看到的是,每个DDM提供了多个访问地址,每个库的访问url类似于:jdbc:mysql:loadbalance://192.168.0.35:5066,192.168.0.192:5066,192.168.0.175:5066,192.168.0.139:5066/orderdb?loadBalanceAutoCommitStatementThreshold=5
从访问的url看,内部应该是多台DDM节点的,实际上从我们测试的情况看,访问任何一台的效果都是一样的。猜测,内部的交互应该是类似如下图的:
跟DDM的技术专家求证,的确是如此的,心里有点小得意~~
我们的代码全部是java的代码,连接池用的是druid,根据DDM的指导,将url配置好就能正常访问了。感觉关健的就在loadbalance这个,应该是告诉了驱动,通过负载均衡方式访问DDM。在网上查了下,这种方式是直接在驱动层面做的负载均衡,相比通过负载均衡器的方式,少了一次网络转发,怪不得效率会这么高。不过,APP到底是访问哪个DDM,内部机制是什么样子的?这些在网上查了下,都是语焉不详,没办法只好从MySQL JDBC的源码入手了。
驱动的源码是托管在github上,我们当前用的是DDM推荐的5.1.44版本的:https://github.com/mysql/mysql-connector-j/tree/5.1.44
核心的就是几个Loadbalance开头的类:
代码比较多,其他的就不多说了,最关键的就是下边这块代码:
LoadBalancedConnectionProxy.java类的pickNewConnection()函数
这个函数在创建连接对象、一个事务提交或者回滚都会调用,作用就是轮换下一个DDM节点。这块代码的逻辑就是,根据一定的负载均衡策略挑选一个节点的连接,做个基本的连接有效性探测,然后将当前连接的状态同步到新连接(见 Table 2 MultiHostConnectionProxy.syncSessionState())。同步完毕,就把当前使用的连接设置为新挑选的连接。如果所有的连接都不可用,就把当前状态设置为了Closed状态。看着快代码,感觉MySQL的有些代码也不严谨,比如如果在获取新连接的时候,如果抛了SQLException出来,这个异常就直接被吃掉了,不会抛出去,也不会有任何信息记录下来,这个对后续的问题定位还是很不方便的,不知道是出于什么考虑的。 Table 1 LoadBalancedConnectionProxy.pickNewConnection() synchronized void pickNewConnection() throws SQLException { if (this.isClosed && this.closedExplicitly) { return; } if (this.currentConnection == null) { // startup this.currentConnection = this.balancer.pickConnection(this, Collections.unmodifiableList(this.hostList), Collections.unmodifiableMap(this.liveConnections), this.responseTimes.clone(), this.retriesAllDown); return; } if (this.currentConnection.isClosed()) { invalidateCurrentConnection(); } int pingTimeout = this.currentConnection.getLoadBalancePingTimeout(); boolean pingBeforeReturn = this.currentConnection.getLoadBalanceValidateConnectionOnSwapServer(); for (int hostsTried = 0, hostsToTry = this.hostList.size(); hostsTried < hostsToTry; hostsTried++) { ConnectionImpl newConn = null; try { newConn = this.balancer.pickConnection(this, Collections.unmodifiableList(this.hostList), Collections.unmodifiableMap(this.liveConnections), this.responseTimes.clone(), this.retriesAllDown); if (this.currentConnection != null) { if (pingBeforeReturn) { if (pingTimeout == 0) { newConn.ping(); } else { newConn.pingInternal(true, pingTimeout); } } syncSessionState(this.currentConnection, newConn); } this.currentConnection = newConn; return; } catch (SQLException e) { if (shouldExceptionTriggerConnectionSwitch(e) && newConn != null) { // connection error, close up shop on current connection invalidateConnection(newConn); } } } // no hosts available to swap connection to, close up. this.isClosed = true; this.closedReason = "Connection closed after inability to pick valid new connection during load-balance."; } Table 2 MultiHostConnectionProxy.syncSessionState() static void syncSessionState(Connection source, Connection target, boolean readOnly) throws SQLException { if (target != null) { target.setReadOnly(readOnly); } if (source == null || target == null) { return; } target.setAutoCommit(source.getAutoCommit()); target.setCatalog(source.getCatalog()); target.setTransactionIsolation(source.getTransactionIsolation()); target.setSessionMaxRows(source.getSessionMaxRows()); }
MySQL-JDBC Loadbalance参数说明
明白了MySQL-JDBC的Loadbalance的相关机制,最重要的还是要对相关的参数有个详细的了解,并且设置有效的值,Loadbalance相关一共有十几个参数,几个比较关键的如下表所示:
其他还有几个参数,一般用不到,也就不罗列出来了。大家感兴趣的话可以关注公众号:中间件小哥(zhongjianjianxiaoge)了解更多哟~
「深度学习福利」大神带你进阶工程师,立即查看>>>
摘要 : 经常碰到内部同学或者外部客户问ossutil关于并发上传性能的问题。本文简单描述下ossutil并发上传原理并举例说明。 用户可从这里获取ossutil。 官网:https://help.aliyun.com/document_detail/50452.html代码:https://github.com/aliyun/ossutil 参数 --recursive 上传文件到oss时,如果file_url为目录,则必须指定--recursive选项,否则无需指定--recursive选项。
经常碰到内部同学或者外部客户问ossutil关于并发上传性能的问题。本文简单描述下ossutil并发上传原理并举例说明。
用户可从这里获取ossutil。
参数
--recursive 上传文件到oss时,如果file_url为目录,则必须指定--recursive选项,否则无需指定--recursive选项。 从oss下载或在oss间拷贝文件时 如果未指定--recursive选项,则认为拷贝单个object,此时请确保src_url精确指定待拷贝的object,如果object不存在,则报错。 如果指定了--recursive选项,ossutil会对src_url进行prefix匹配查找,对这些objects批量拷贝,如果拷贝失败,已经执行的拷贝不会回退。
在进行批量文件上传(或下载、拷贝)时,如果其中某个文件操作失败,ossutil不会退出,而是继续进行其他文件的上传(或下载、拷贝)动作,并将出错文件的错误信息记录到report文件中。成功上传(或下载、拷贝)的文件信息将不会被记录到report文件中。
批量操作出错时终止运行的情况 如果未进入批量文件迭代过程,错误已经发生,则不会产生report文件,ossutil会终止运行。如,用户输入cp命令出错时,不会产生report文件,而是屏幕输出错误并退出。 如果批量操作过程某文件发生的错误为:Bucket不存在、accessKeyID/accessKeySecret错误造成的权限验证非法等错误,ossutil会屏幕输出错误并退出。
report文件名为:ossutil_report_日期_时间.report。report文件是ossutil输出文件的一种,被放置在ossutil的输出目录下,该目录的路径可以用配置文件中的outputDir选项或命令行--output-dir选项指定,如果未指定,会使用默认的输出目录:当前目录下的ossutil_output目录。
ossutil不做report文件的维护工作,请自行查看及清理用户的report文件,避免产生过多的report文件。
并发控制参数 --jobs选项控制多个文件上传/下载/拷贝时,文件间启动的并发数 --parallel控制上传/下载/拷贝大文件时,分片间的并发数。
默认情况下,ossutil会根据文件大小来计算parallel个数(该选项对于小文件不起作用,进行分片上传/下载/拷贝的大文件文件阈值可由--bigfile-threshold选项来控制),当进行批量大文件的上传/下载/拷贝时,实际的并发数为jobs个数乘以parallel个数。该两个选项可由用户调整,当ossutil自行设置的默认并发达不到用户的性能需求时,用户可以自行调整该两个选项来升降性能。
--bigfile-threshold参考详情,请参考 ossutil大文件断点续传
--part-size选项
该选项设置大文件分片上传/下载/拷贝时,每个分片的大小。
默认情况下,不需要设置该值,ossutil会根据文件大小自行决定分片大小和分片并发,当用户上传/下载/拷贝性能达不到需求时,或有其他特殊需求时,可以设置这些选项。
如果设置了该选项(分片大小),分片个数为:向上取整(文件大小/分片大小),注意如果--parallel选项值大于分片个数,则多余的parallel不起作用,实际的并发数为分片个数。
如果将part size值设置得过小,可能会影响ossutil文件上传/下载/拷贝的性能,设置得过大,会影响实际起作用的分片并发数,所以请合理设置part size选项值。
性能调优
如果并发数调得太大,由于线程间资源切换及抢夺等,ossutil上传/下载/拷贝性能可能会下降,所以请根据实际的机器情况调整这两个选项的数值,如果要进行压测,可以一开始将两个数值调低,慢慢调大寻找最优值。
如果--jobs选项和--parallel选项值太大,在机器资源有限的情况下,可能会因为网络传输太慢,产生EOF错误,这个时候请适当降低--jobs选项和--parallel选项值。
如果文件数太多大小有不太平均,直接同时使用--jobs=3 --parallel=4进行设定(文件间并发为3,单文件内的并发为4),同时观察MEM, CPU,网络情况,若并未打满网络、占满CPU,则可以继续上调--jobs和--parallel。
真实案例
根据当时客户场景,下载速度大概在265M/s。
案例解析
在默认情况下,因为是多文件下载,所以会同时下载5个文件(version<=1.4.0,文件间的并发数为5)。
因为平均每个文件大小在1.1G,默认会为每个下载的文件开12个线程(单个文件内的并发数为12,在没有设置parallel参数和partsize参数时会根据文件大小计算出)。
那么在客户的环境里ossutil在运行期间至少有5*12= 60 个线程在跑。这么多并发应该会直接打满网卡,CPU应该也很拥挤。建议在并发下载时观察环境CPU,网络,进程/线程情况。
根据客户的截图,建议对每个文件分片100M~200M进行并发,比如设为100M每个分片,这样每个文件下载的并发数就是filesize/partsize。
ossutil cp oss://xxx xxx -r --part-size=102400000
如果文件数太多大小有不太平均,直接同时使用--jobs=3 --parallel=4进行设定(文件间并发为3,单文件内的并发为4)
总的建议就是:jobs * parallel 与CPU核数为1:1,2:1,但不要太大。
进一步解释
不是oss需要多少资源,是每个并发(读取文件,分片,上传等操作)所需的CPU,mem,网络等。 --jobs是多文件间的并发度,默认是5(version <= 1.4.0,之后是3) --parallel是大文件内部分片并发度,在没有设置parallel参数和partsize参数时会根据文件大小计算出,最大不会超过15(version <= 1.4.0,之后是12) 如果文件数太多大小又不太平均,可以同时使用--jobs=3 --parallel=4进行设定(文件间并发为3,单文件内的并发为4,具体数字根据机器情况调整)
小结 cp默认并发执行,cp大文件用分片并发下载,小文件用put;默认开启CRC校验。 在oss间拷贝文件,目前只支持拷贝object,不支持拷贝未complete的Multipart。 总的建议 jobs * parallel 与CPU核数为1:1,2:1,但不要太大 并发数太多会直接打满网卡,CPU也会拥挤。建议在并发时观察环境CPU,网络,进程/线程情况
Reference ossutil大文件断点续传
作者: zuozhao
原文链接
本文为云栖社区原创内容,未经允许不得转载。
「深度学习福利」大神带你进阶工程师,立即查看>>>
背景介绍
TableStore(简称OTS)是阿里云的一款分布式表格系统,为用户提供schema-free的分布式表格服务。随着越来越多用户对OLAP有强烈的需求,我们提供在表格存储上接入Data Lake Analytics(简称DLA)服务的方式,提供一种快速的OLAP解决方案。DLA是阿里云上的一款的通用SQL查询引擎,通过在OTS连通DLA服务,使用通用的SQL语言(兼容mysql5.7绝大部分查询语法),在表格存储上做灵活的数据分析任务。
架构视图
如上图所示,整体OLAP查询架构涉及3款阿里云产品:DLA,OTS,OSS。其中DLA负责分布式SQL查询计算,在实际运行过程中,会将用户sql查询请求进行任务拆解,产生若干可并行化的子任务,提升数据计算和查询能力。OTS为数据存储层,用于接收DLA的各类子查询任务。如果用户已经有存量的数据在OTS上,可以直接在DLA上建立映射视图,实现快速体验SQL计算带来的便捷。OSS为分布式对象存储系统,主要用于用户查询结果数据的保存。
因此用户要想快速体验SQL on OTS,必须在开通OTS的前提下,完成DLA和OSS服务的开通。通过上述3个云产品的配合,用户就能在OTS上快速执行SQL计算。目前开通OSS服务的主要原因是DLA默认回查询结果集数据写回到OSS存储,因此需要引入一个额外的存储依赖,但仅依赖用户开通OSS服务,不需要用户预先创建OSS存储实例。
目前开服公测的区域是上海区,对应的实例是该region内所有的容量型实例。在开通DLA服务时,需要先填写公测申请,通过之后按照“接入方式”小节的步骤,能快速完成接入体验。
接入方式
整个主要包含OTS、OSS、DLA的服务接入。需要注意的一点是,完成接入之后,就会按照实际查询产生相应的费用。如在这个过程中,用户账号是欠费的,将会发生查询失败。
OTS服务开通
如果用户已经开通的OTS服务,并且上面已经包含存量的实例,表格数据,则忽略该步骤。
对于首次使用OTS的用户,可按照下述方式开通OTS: 登录 https://www.aliyun.com ; 进入“产品”->"云计算基础"->"数据库"->“表格存储 TableStore”; 按照上面的文档说明,快速建立实例和表格,进行体验; 1)使用控制台,快速创建测试表格:
2)使用控制台,快速插入测试数据:
OSS服务开通 登录 https://www.aliyun.com ; 进入“产品”->"云计算基础"->"存储服务"->“对象存储 OSS”; 直接点击服务开通即可。
OSS服务开通后,不需要创景对象实例,DLA接入时,会自动为用户在OSS服务中,创建用于存储查询结果数据的对象存储实例,用户不需要关心。
DLA服务开通 登录 https://www.aliyun.com ; 进入“产品”->"大数据"->"大数据计算"->“Data Lake Analytics”; 直接点击服务开通;
注意:处于公测阶段时,开通服务需要做公测申请,填写好相关信息即可。
DLA on OTS接入
按照下列步骤,在DLA上建立OTS的映射: 开通DLA服务之后,可以选择不同region,选择开通对应region的DLA服务实例(如现在华东2的上海区域)。不同的region,对应不同的账号,不同region的DLA账号,不能混用,如下图所示: 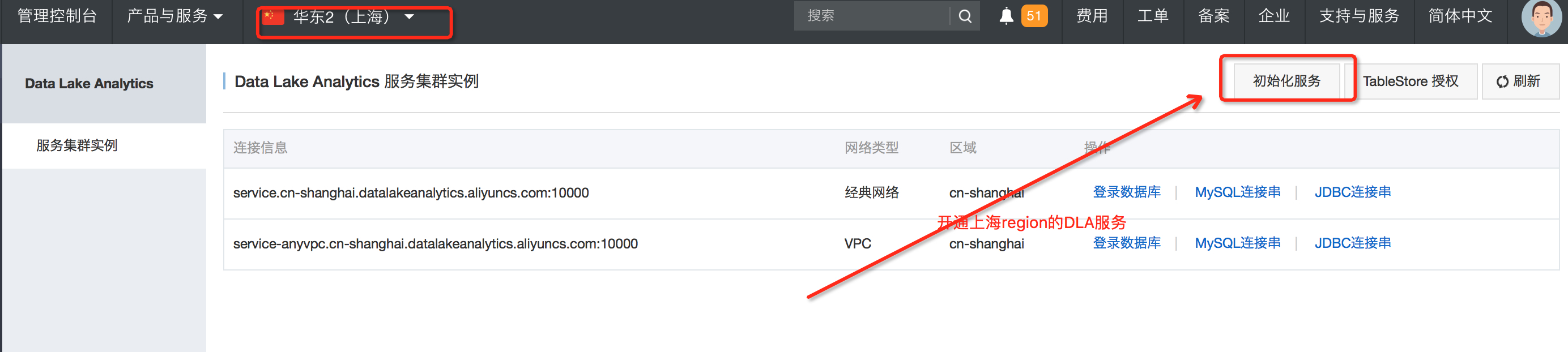 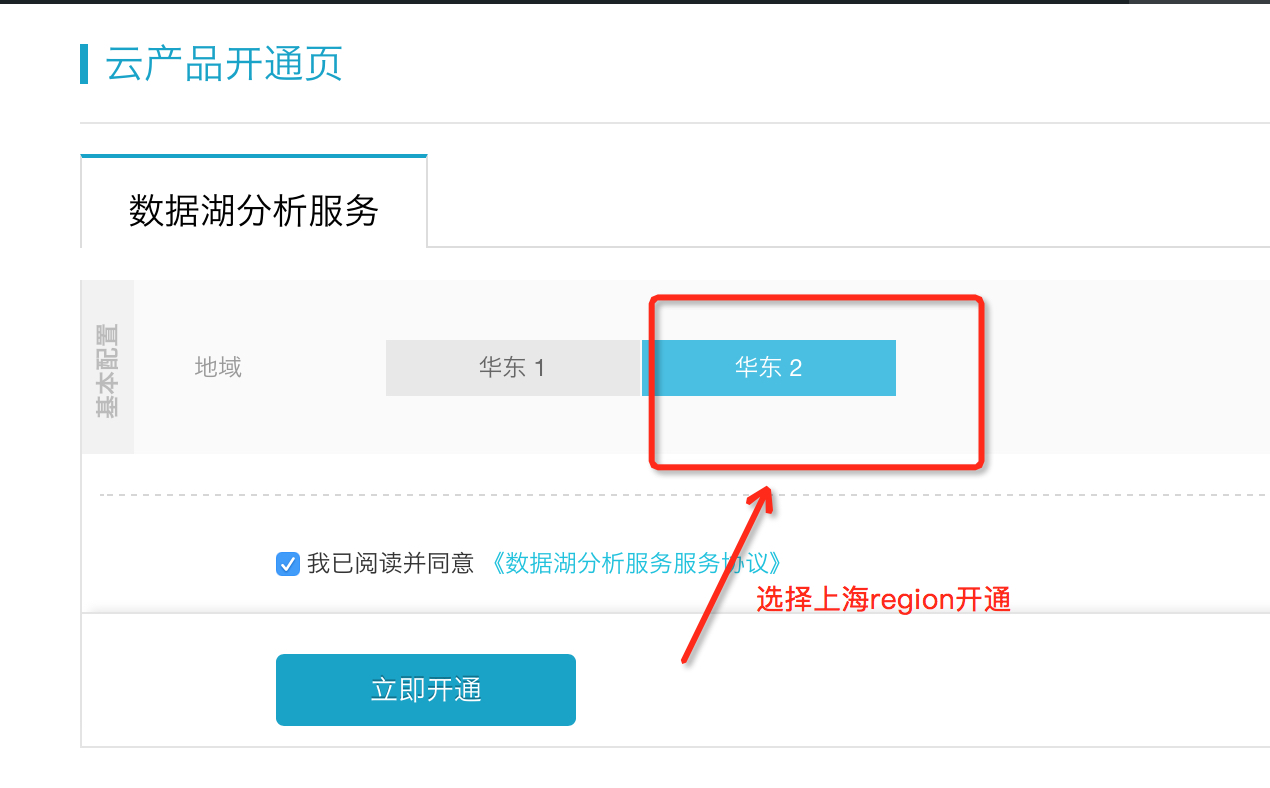 注意:账号创建完成之后,会收到相关邮件(邮箱为阿里云的注册邮箱),内含该region的DLA账号和密码,注意查收。 选择region,授权DLA访问OTS上的用户实例数据,如下图所示:
服务开通之后,有3中SQL访问方式:控制台、mysql client,JDBC。
控制台访问
点击数据库连接,使用邮件中的该region的用户名和密码,连接进入控制台。
进入控制台后,需要为OTS上的实例表格数据建立映射信息。场景举例:假设用户在上海region已经有一个名为sh_tpch的实例,该实例包含表格test001,里面包含2行测试数据。对该实例建立映射的步骤包括:
1)将ots的实例映射成DLA的一个DataBase实例:
在建立DLA的Database映射前,首先需要在OTS上创建一个表格存储的实例instance,如: 创建一个实例,名为sh-tpch,对应的endpoint为https://sh-tpch.cn-shanghai.ots.aliyuncs.com。
完成测试实例创建后,执行下列语句建立Database映射: CREATE SCHEMA sh_tpch001 with DBPROPERTIES(LOCATION ='https://sh-tpch.cn-shanghai.ots.aliyuncs.com', catalog='ots', instance ='sh-tpch'); 注意:使用mysql client时,可以使用create database或create schema语句进行创建db映射;但是在控制台,目前只支持create schema语句创建db映射。
上述语句,将在DLA上创建一个名为sh_tpch001的database,对应的实例是ots的sh-tpch.cn-shanghai.ots.aliyuncs.com集群下名为sh-tpch的实例。通过上面的语句,就能产生一个ots的实例映射。
2)在tp_tpch001的DB下,建立表格的映射:
在建立DLA的表格映射前,首先需要在OTS创建测试表,流程参考"OTS服务开通"小节。
测试表格创建完成后,执行下列语句建立表格映射: CREATE TABLE test001 (pk0 int , primary key(pk0)); 注意:主要建立DLA映射表时,指定的Primary Key必须跟OTS表格定义Primary Key列表一致。因为Primary Key必须能是唯一的定位一行,一旦映射表的Primary Key列表与OTS表格的PK不一致,则可能会导致SQL查询结果出现非预期的错误。
例如:用户的OTS实例sh_tpch上包含test001表格,其中只有一列pk0。上面的命令就完成了在DLA的实例sh_tpch001上,创建映射表test001。使用show命令能查看该表创建成功:
3)使用select语句执行sql查询: 1. 查出所有数据: select * from test001;
2. 执行count统计: select count(*) from test001;
3. 执行sum统计: select sum(pk0) from test001;
4)更为丰富执行语句,请查看如下的帮助说明文档: create schema语句:https://help.aliyun.com/document_detail/72005.html create table语句:https://help.aliyun.com/document_detail/72006.html select语句:https://help.aliyun.com/document_detail/71044.html show语句:https://help.aliyun.com/document_detail/72011.html drop table语句:https://help.aliyun.com/document_detail/72008.html drop schema语句:https://help.aliyun.com/document_detail/72007.html
5)在做SQL执行时,可以选择同步执行结果,返回满足条件的前10000条记录;如果要获大结果集数据,需要选择异步执行,并使用show query_id的方式异步获取结果: show query_task where id = '59a05af7_1531893489231';
mysql访问
使用标准的mysql client也能快速连通DLA的数据实例。其中连接语句为: mysql -h service.cn-shanghai.datalakeanalytics.aliyuncs.com -P 10000 -u
-p -c -A
其他操作语句跟“控制台访问”小节介绍一致。
JDBC访问
也可以使用标准的java api实现访问,连接串为: jdbc:mysql://service.cn-shanghai.datalakeanalytics.aliyuncs.com:10000/
其他操作语句跟“控制台访问”小节介绍一致。
总结
通过DLA+OTS,我们能让用户快速在表格存储上体验极致的分布式SQL计算。
作者: 阿杰.pt
原文链接
本文为云栖社区原创内容,未经允许不得转载。 「深度学习福利」大神带你进阶工程师,立即查看>>>
前言
TableStore是阿里云自研的一款分布式NoSQL数据库,提到NoSQL数据库,现在对很多应用研发来说都已经不再陌生。当前很多应用系统底层不会再仅仅依赖于关系型数据库,而是会根据不同的业务场景,来选型使用不同类型的数据库,例如缓存型KeyValue数据会存储在Redis,文档型数据会存储在MongoDB,图数据会存储在Neo4J等。
回顾下NoSQL的发展历程,NoSQL诞生于Web 2.0时代,互联网高速发展的一个时代,也带来了一次互联网数据的爆发。传统的关系型数据库很难承载如此海量的数据,需要一种具备高扩展能力的分布式数据库。但基于传统的关系数据模型,去实现高可用和可扩展的分布式数据库是非常有挑战的一件事。互联网上大部分数据的数据模型很简单,没必要一概用关系模型来建模。如果能打破关系模型以一种更简单的数据模型来对数据建模、弱化事务和约束、以高可用和可扩展为目标,以此为目标设计的数据库能更好的满足业务需求,正是基于此种理念推动了NoSQL的发展。
总结下,NoSQL的发展是基于互联网时代对业务的新挑战以及数据库的新需求而推动的,基于此发展起来的NoSQL,有其显著的特征: 多数据模型:为满足不同数据的需求,诞生出了很多不同的数据模型,例如KeyValue、Document、Wide Column、Graph以及Time Series等。这是NoSQL数据库发展的一个最显著特征,打破了关系模型的约束,选择一个多元的发展方向。数据模型的选择是更加场景化的,更贴近业务的实际需求,能够做更深层次的优化。 高并发、低延迟:NoSQL数据库的发展更多由在线业务的需求推动,其设计目标更多的是面向在线业务提供高并发、低延迟的访问。 高可扩展:为应对爆发的数据量增长,可扩展是最核心的设计目标之一,所以底层架构往往在设计之初即考虑分布式架构。
从DBEngines的发展趋势统计上也可以看到,各类NoSQL数据库在近几年都是处于一个蓬勃发展的状态。阿里云TableStore作为一款分布式NoSQL数据库,在数据模型上选择了多模型的架构,同时支持WideColumn和Timeline。
WideColumn模型是由Bigtable提出,后被其他同类型系统广泛应用的一种经典模型,目前世界上的绝大部分半结构化、结构化数据都是存储在该模型系统中。除了WideColumn模型外,我们推出了另一种全新的数据模型:Timeline,Timeline模型是一种用于消息数据的新一代模型,适用于IM、Feeds和物联网设备消息下推等消息系统中消息的存储和同步,目前已经开始被广泛使用。接下来,我们详细了解下这两种模型。
Wide Column模型
上图是Wide Column模型的一个模型图,为更好的理解这个模型,我们拿关系模型来做一个对比。关系模型可以简单的理解为一个二维的模型,由行列组成,每一行的列固定Schema。所以关系模型的特征是:二维以及固定Schema,这是一个最简单的理解,抛开事务和约束来看的话。Wide Column模型是一个三维的模型,在行与列二维的基础上,增加了一个时间维度。时间维度体现在属性列上,属性列可以拥有多个值,每个值对应一个Timestamp作为版本。并且每一行是Schema Free的,没有强Schema定义。所以Wide Column模型对比关系模型,简单总结就是:三维、Schema Free、简化事务和约束。
再详细看下这个模型的组成,有几个主要部分: 主键(Primary Key):每一行都会有主键,主键会由多列(1-4列)构成,主键的定义是固定Schema,主键的作用主要是唯一区分一行数据。 分区键(Partition Key):主键的第一列称为分区键,分区键用于对表进行范围分区,每个分区会分布式的调度到不同的机器上进行服务。在同一个分区键内,我们提供跨行事务。 属性列(Attribute Column):一行中除开主键列外,其余都是属性列。属性列会对应多个值,不同值对应不同的版本,一行可存储不限个数个属性列。 版本(Version):每一个值对应不同的版本,版本的值是一个时间戳,用于定义数据的生命周期。 数据类型(Data Type):TableStore支持多种数据类型,包含String、Binary、Double、Integer和Boolean。 生命周期(Time To Live):每个表可定义数据生命周期,例如生命周期配置为一个月,则该表数据中在一个月之前写入的数据就会被自动清理。数据的写入时间由版本来决定,版本一般由服务端在数据写入时根据服务器时间来定,也可由应用自己指定。 最大版本数(MaxVersion):每个表可定义每一列最多保存的版本数,用于控制一列的版本的个数,老版本的超过个数上限的数据会被自动清理。
Wide Column模型的特色,总结来说就是:三维结构(行、列和时间)、宽行、多版本数据以及生命周期管理。同时Wide Column模型在数据操作层面,提供两类数据访问API,Data API和Stream API。
Data API
关于Data API的详细文档请参考 这里 ,Data API是标准的数据API,提供数据的在线读写,包括: PutRow:新插入一行,如果存在相同行,则覆盖。 UpdateRow:更新一行,可增加、删除一行中的属性列,或者更新已经存在的属性列的值。如果该行不存在,则新插入一行。 DeleteRow:删除一行。 BatchWriteRow:批量更新多张表的多行数据,可组合PutRow、UpdateRow和DeleteRow。 GetRow:读取一行数据。 GetRange:范围扫描数据,可正序扫描或者逆序扫描。 BatchGetRow:批量查询多张表的多行数据。
Stream API
在关系模型数据库中是没有对数据库内增量数据定义标准API的,但是在传统关系数据库的很多应用场景中,增量数据(binlog)的用途是不可忽视的。这个在阿里内部场景中,有很广泛的应用,并且提供了DRC这类中间件将这部分数据的能力完全挖掘了出来。将增量数据的能力挖掘出来后,我们可以在技术架构上做很多事: 异构数据源复制:MySQL数据增量同步到NoSQL,做一个冷数据存储。 对接流计算:可实时对MySQL内数据做统计,做一些大屏类应用。 对接搜索系统:可将搜索系统扩展为MySQL的二级索引,增强MySQL内数据的检索能力。
但即使关系数据库的增量数据如此有用,业界也没有规范的API定义来获取这部分增量数据。TableStore是早早发觉了这部分数据存在的价值,提供了标准化的API来将这部分数据的能力开放出来,这就是我们的Stream API( 文档 )。
Stream API大致包括: ListStream:获取表的Stream,范围Stream的ID。 DescribeStream:获取Stream的详细信息,拉取Stream内Shard列表,以及Shard结构树。 GetShardIterator:获取Shard当前增量数据的Iterator。 GetStreamRecord:根据Shard Iterator获取Shard内的增量数据。
TableStore Stream的实现会比MySQL Binlog复杂很多,因为TableStore本身是一个分布式的架构,Stream也是一个分布式的增量数据消费框架。Stream的数据消费必须保序获取,Stream的Shard与TableStore内部的表的分区一一对应,表的分区会存在分裂和合并,为保证在分区分裂和合并后老Shard和新增Shard的数据消费仍然能保序,我们设计了一套比较精密的机制。对于TableStore Stream的设计,不在这里赘述,我们之后会发布更详细的设计文档。
当前由于Stream内部架构的复杂,将这部分复杂度也引入到了Stream数据消费侧,在用户使用Stream API时并不是那么简单。在今年我们也规划了一个全新的数据消费通道服务,来简化Stream数据的消费,提供更简单易用的API,尽情期待。
Timeline模型
Timeline模型是我们针对消息数据场景所新创的一个数据模型,它的特色在于能够满足消息数据场景对消息保序、海量消息存储、实时同步的特殊需求。
如上图是Timeline的模型图,将一张大表内的数据抽象为多个Timeline,一个大表能够承载的Timeline个数无上限。
Timeline的构成主要包括: Timeline ID:唯一标识Timeline的ID。 Timeline Meta:Timeline的元数据,元数据内可包含任意键值对属性。 Message Sequence:消息队列,承载该Timeline下的所有消息。消息在队列里有序保存,并且根据写入顺序分配自增的ID。一个消息队列可承载的消息个数无上限,在消息队列内部可根据消息ID随机定位某条消息,并提供正序或者反序扫描。 Message Entry:消息体,包含消息的具体内容,可以包含任意键值对。
Timeline的模型逻辑上与消息队列有一些相似之处,Timeline类似于消息队列中的Topic。不同之处在于,TableStore Timeline更侧重Topic的规模。在即时通讯场景,每个用户的收件箱和寄件箱都是一个Topic,在物联网消息场景,每个设备对应一个Topic,Topic的量级会达到千万甚至亿级别。TableStore Timeline基于底层的分布式引擎,单表能支持理论无上限的Timeline(Topic),简化队列的Pub/Sub模型,支持消息保序、随机定位以及正反序扫描,更贴近即时通讯(IM)、Feeds流以及物联网消息系统等海量消息数据场景的需求。
关于Timeline模型的起源,可以看下这篇文章 - 《 现代IM系统中消息推送和存储架构的实现 》,具体的应用可以参考下这篇文章 - 《 Table Store Timeline:轻松构建千万级IM和Feed流系统 》。
Timeline是在去年新推出的一个数据模型,我们还在不断的打磨。基于这个模型,我们已经帮助钉钉、菜鸟智能客服、淘票票小聚场、智能设备管理等业务构建即时通讯、Feeds流、物联网等领域的消息系统,欢迎使用。
作者: 木洛
原文链接
本文为云栖社区原创内容,未经允许不得转载。
「深度学习福利」大神带你进阶工程师,立即查看>>>
序言
传统web浏览器应用采用客户端主动请求方式,只有在收到浏览器请求时服务端才返回消息,这种模式已经不能满足日益多样化的web应用需求,例如:
在线聊天系统:需要实时获取聊天消息。
实时监控系统:需要实时获取监控对象状态。如仪表读数、告警信息等。
随着html技术演进,发展出了多种服务器推送技术,用于服务器向浏览器客户端推送消息。
Ajax轮询
采用Ajax定时向服务端发送请求检查有无消息更新。网页定时向服务器发送请求,若服务器有消息推送,则返回消息,否则返回空消息,如下图所示:
这种轮询方式需要发送大量无效请求,大大消耗了服务器资源,且推送消息的实时性较低。
Ajax长轮询
Ajax长轮询对前面的Ajax轮询方式做了改进,服务端收到请求后,不再立即返回,而是等待有消息推送时返回。网页收到服务端返回的消息后,立即发起一个新的请求,等待下一个推送消息。
采用这种方式的服务端实现比前者复杂,需要维护一个客户端建立的连接列表,当产生对某个客户端的推送消息后找到对应的连接并发送。优势是减少了轮询消耗,发送事件的实时性得到增强。
Server-Send Event
Server-Send Event是html5标准新增的技术,它延用了Ajax长轮询的思路,并对其进行了一些规范。Server-Send Event让服务端可以向客户端流式发送文本消息,并在发送完一个消息后保持请求不结束,连接始终保持。如下图所示:
网页调用EventSource接口向服务器发送请求:
var source = new EventSource('http://localhost:8080');
source.addEventListener('message', function(e) { console.log(e.data); }, false);
服务器返回的Content-Type头必须为text/event-stream,且返回完一个消息后不关闭请求,后续消息仍然使用同一个请求返回。浏览器会自动以换行符识别每个消息。
响应头
Content-Type: text/event-stream
X-Accel-Buffering: no
响应体
event: userlogin
data: {"username": "John123"}
event: message
data: 123
如果服务端返回的消息通过nginx等代理服务器返回给客户端时,可能受到nginx缓存机制的影响。某些情况下,nginx会将服务端返回体缓存起来,等待所有返回接受完毕后再统一返回给客户端,在server-send event情况下将导致客户端无法及时接收到消息。需要在返回头中添加X-Accel-Buffering: no,以防止nginx做缓存。
使用华为API gateway 提供
Server-Send Event类型的
API服务 建立后端服务
登录华为云https://console.huaweicloud.com/,创建弹性云服务器
输入apt install nodejs安装nodejs,使用nodejs创建服务器,并输入下列示例代码。
var http = require("http");
http.createServer(function (req, res) {
if (req.url === "/stream") {
res.writeHead(200, {
"Content-Type":"text/event-stream",
"X-Accel-Buffering":"no",
});
res.write("data: " + (new Date()) + "\n\n");
interval = setInterval(function () {
res.write("data: " + (new Date()) + "\n\n"); 12 }, 1000);
req.connection.addListener("close", function () {
clearInterval(interval);
}, false);
}
}).listen(8080);
上面代码是服务器每秒向客户端发送时间的示例。将上面的代码保存为server.js,然后执行nodejs server.js &
就启动了监听在8080端口的服务器。
添加安全组
将8080端口添加到安全组规则,使得外部可以访问云服务器的8080端口。
创建API
API网关提供从内网访问云服务器的能力,不需要申请公网弹性IP,就可以通过VPC通道开放API。
登录华为云https://console.huaweicloud.com/apig/ ,首先创建VPC通道,端口为8080
将弹性云服务器添加到VPC通道:
创建API,认证类型选择APP
“请求Path”填“/stream”,“开启跨域”选项选择开启
创建API完成后,发布API到RELEASE环境。
创建APP并绑定API
在应用管理界面创建一个APP,并绑定刚刚创建的API。
创建OPTIONS方法的API
OPTIONS方法的API是提供给浏览器发送跨域请求的预请求使用,同样选择开启跨域(CORS),并将后端配置为Mock。
点完成创建API后,发布API到RELEASE环境。
创建网页,访问API
1.要访问APP认证方式的API,需要通过APP的key和secret生成签名,才能校验通过。生成签名使用下面链接下载的javascript SDK
https://console.huaweicloud.com/apig/?agencyId=c65a0db86e514fe298cdc57c6273411a®ion=cn-south-1&locale=zh-cn#/apig/manager/useapi/sdk
2.由于IE浏览器不支持Server Sent Event,需要从https://github.com/Yaffle/EventSource/下载浏览器兼容的Server Sent Event实现。
搜索并删除下面四行代码:
if (url.slice(0, 5) !== "data:" &&
url.slice(0, 5) !== "blob:") {
requestURL = url + (url.indexOf("?", 0) === -1 ? "?" : "&") + "lastEventId="+ encodeURIComponent(lastEventId);
}
3.创建index.html,内容如下:
SSE APP test SSE APP test
09
将刚刚创建的APP的AppKey和AppSecret填入上面指定位置。在本地用浏览器打开此页面,可以看到页面上显示的时间每秒刷新一次。
以上就是对如何实现在线聊天系统中的实时消息获取的详解,想要了解更多, 点击这里 立即体验一番吧~
「深度学习福利」大神带你进阶工程师,立即查看>>>
SAMIR BEHARA
本文将解释Service Mesh相关概念,为什么云原生应用需要它,以及这项技术被社区热烈拥抱、积极采用的原因。
毫不夸张地说,微服务已经席卷了整个软件行业。从Monolith过渡到微服务架构,可以让我们频繁、独立而可靠地部署应用。
然而,在微服务架构中,一切都不是绿色的,它必须处理在设计分布式系统时遇到的相同问题。
然而,微服务架构不是万能的,在设计分布式系统时会遇到很多有待解决的问题。说到这里,我们不妨首先回顾一下关于分布式计算的8大谬误—— 网络是可靠的(The Network is Reliable) 延迟为零(Latency is Zero) 带宽是无限的(Bandwidth is Infinite) 网络是安全的(The Network is Secure) 拓扑不会改变(Topology does not Change) 有一名管理员(There is one Administrator) 传输成本为零(Transport Cost is Zero) 网络是同质的(The Network is Homogenous)
在微服务体系结构中,对于网络的依赖带来了可靠性问题。随着服务数量的增加,我们必须处理它们之间的交互,监视整个系统的健康状况,处理容错、日志记录,处理多个故障点等等。每个微服务都需要有这些共同的功能,以便服务通信是平滑和可靠的。但是,如果你要处理几十上百个微服务,操作难度光是听起来就有些吓人。
什么是服务网格?
Service Mesh可以定义为在微服务体系结构中处理服务间通信的基础结构层,它减少了与微服务体系结构相关的复杂性,并提供了许多治理功能,如 - 负载均衡(Load Balancing) 服务发现(Service Discovery) 健康检查(Health Check) 身份验证(Authentication) 流量管理和路由(Traffic Management & Routing) 断路和故障转移(Circuit Breaking and Failover Policy) 安全(Security) 监控(Metrics & Telemetry) 故障注入(Fault Injection)
为什么需要Service Mesh?
在微服务架构中,处理服务到服务的通信是企业IT的一大挑战。大多数时候,我们需要依赖第三方库或者组件来提供服务发现、负载均衡、断路器、监控等功能。像Netflix这样的公司,他们开发了自己的库,比如Hystrix for Circuit Breaker、Eureka for Service Discovery、Ribbon for Load balanced等,在其组织中得到了广泛的使用。
然而,这些组件需要在应用代码中进行配置,而且语言不同,实现方式策略也会有所不同。在升级这些外部组件时,我们需要更新应用、验证并部署所有改动。如此便产生了一个问题,我们的应用代码编程了业务和这些附加配置混合体。这种紧密耦合增加了整个应用的复杂性——开发人员现在还需要了解这些组件是如何配置的,以便在遇到任何问题时能够排除故障。 Service Mesh适时出现,将复杂性从应用中分离了出来,并将其放入服务代理(service proxy)代为处理。这些服务代理提供了如流量控制、断路、服务发现、身份验证、监控、安全性等等功能特性。那么对于应用来说,只需要关心业务功能的实现即可。
假设在我们的微服务体系结构中,您有5个服务相互通信。与其在每个微服务中构建配置、路由、遥测、日志记录、断路等常见的必要功能,不如将其抽象为一个单独的组件——这里称为“服务代理”(service proxy)。
随着Service Mesh的引入,责任的划分变得清晰,开发人员的生活也更加轻松——如果存在问题,开发人员可以根据应用程序或网络相关的原因,轻松地确定根源。
Service Mesh是如何实现的?
要实现Service Mesh,可以将代理与服务一起部署,该模式被称为sidecar。
Sidecars抽象了应用程序的复杂性,处理了诸如服务发现、流量管理、负载平衡、线路中断等功能。
Lyft的 Envoy 是目前非常流行的云原生应用开源代理。特使在每个服务旁运行,并以平台无关的方式提供必要的特性。所有到我们的服务的流量都通过特使代理。
而Istio是一个连接、管理和保护微服务的开放平台。它在Kubernetes社区非常流行,并被广泛采用。 在这一点上,Istio是服务网格的最佳实现之一,它使我们能够在不深入了解底层基础设施的情况下部署微服务。
开源PaaS Rainbond在v3.6.0版本中加入了Service Mesh开箱即用的特性,主要特点包括业务代码无入侵、跨语言&跨协议、支持主流微服务架构、通过插件式扩展来实现治理功能等。 开源PaaS Rainbond v3.6.0正式发布,Service Mesh开箱即用 解读Rainbond ServiceMesh微服务架构 Rainbond插件体系设计简介
关于Rainbond Rainbond 是一款以应用为中心的开源PaaS,由好雨基于Docker、Kubernetes等容器技术自主研发,可作为公有云或私有云环境下的应用交付平台、DevOps平台、自动化运维平台和行业云平台,或作为企业级的混合云多云管理工具、Kubernetes容器管理工具或Service Mesh微服务架构治理工具。 Rainbond项目网站 试用Rainbond公有云 注册或使用Demo账号/密码登录:rainbond-demo/rainbond-demo Github 码云 文档 微信群: 添加微信“zqg5258423”并接受邀请入群
「深度学习福利」大神带你进阶工程师,立即查看>>>
Deploy != Release(第一部分):部署与发布的区别,以及为什么这很重要
Apr 19, 2018 翻译自: Deploy != Release (Part 1): The difference between deploy and release and why it matters.
问:「最新版本部署了吗?」
答:「我在生产环境里部署了 gif 动图支持。」
问:「就是说 gif 动图支持已经发布啦?」
答:「Gif 动图的发布版本已经部署了。」
问:「……」
我曾在很多公司工作过,在这些公司中「部署(deploy,动词)」、「部署物(deployment,名词)」、「上线(ship)」和「发布(release)」都是随意地使用,甚至可以互换使用。作为一个行业,我们在规范使用这些术语方面做得还不够,尽管我们在过去的十多年里已经从根本上改进了运维实践和工具。在 Turbine Labs 中,我们使用了「上线」、「部署」、「发布」和「回滚(rollback)」的精确定义,并花了大量的时间来思考当你把「发布」作为上线过程的一个独立阶段时,世界是什么样子的。在这篇文章的第一部分,我会分享这些术语的定义,描述一些常见的「部署 == 发布」的实践,并且解释为什么这样做的抗风险性很差。在第二部分,我会描述当「部署」和「发布」被视为软件上线周期的不同阶段时的一些非常强大的风险缓释技术。
上线
上线 指你的团队从源码管理库中获取服务代码某个 版本 的快照,并用它处理线上流量的过程。我认为整个上线过程由四个不同的专门的小流程组成:构建(build)、测试、部署和发布。得益于云基础架构、容器、编配框架的技术进步以及流程改进,如 twelve-factor 、 持续集成 和 持续交付 ,执行前三个流程(构建,测试和部署)从未如此简单。
部署
部署 指你的团队在生产环境的基础设置中安装新版本服务代码的过程。当我们说新版软件被 部署 时,我们的意思是它正在生产环境的基础设施的某个地方运行。基础设置可以是 AWS 上的一个新启动的 EC2 实例,也可以是在数据中心的 Kubernetes 集群中的某个容器中运行的一个 Docker 容器。你软件已成功启动,通过了健康检查,并且已准备好(像你希望的那样!)来处理线上流量,但实际上可能没有收到任何流量。这是一个重要的观点,所以我会用 Medium 超棒的大引用格式来重复一遍: 部署不需要向用户提供新版本的服务。
根据这个定义, 部署可以是几乎零风险的活动 。诚然,在部署过程中可能会出现很多问题,但是如果一个容器静默应对崩溃,并且没有用户获得 500 状态响应,那问题是否真的算是 发生 了?
部署了新的版本(紫色),但未发布。已知良好的版本(绿色)仍对线上请求做出响应。
发布
当我们说服务版本 发布 时,我们的意思是它负责服务线上流量。在动词形式中, 发布 是将线上流量转移到新版本的过程。鉴于这个定义,与上线新的二进制文件有关的所有风险 —— 服务中断、愤怒的用户、 The Register 中的刻薄内容 —— 与新软件的发布而不是部署有关。在一些公司,我听说这个上线阶段被称为 首次发布(rollout) 。这篇文章中我们将依旧使用 发布 来表述。
新版本发布,响应线上请求。
回滚
迟早,很可能不久之后,你的团队就会上线一些功能有问题的服务。回滚(和它危险的、不可预测的、压力山大的兄弟 —— 前滚 roll-forward)指将线上服务退回到某个已知状态的过程,通常是重新发布最近的版本。将回滚视为另一个部署和发布流程有助于理解,唯一的区别是: 你正在上线的版本的特征在生产环境中已知 你正在时间压力下执行部署和发布过程 你可能正向一个不同的环境中发布 —— 在上次失败的发布之后某些东西可能改变了(或被改变了)
一个发布后回滚的例子。
现在我们已经就上线、部署、发布和回滚的定义达成了共识,让我们来看看一些常见的部署和发布实践。
原地发布(即部署 == 发布)
当你的团队的上线流程涉及将新版本的软件推送到运行旧版本的服务器上并重启服务的流程时,你就是在原地发布。根据我们上面的定义,部署和发布是同时发生的:一旦新软件开始运行(部署),它就会负载旧版本的所有线上流量(发布)。此时,成功的部署就是成功的发布,失败的部署则会带来部分或整体的服务中断,一群愤怒的用户,可能还有一个气急败坏的经理。
在我们所讨论的部署/发布过程中,原地发布是唯一的将 部署风险 暴露给用户的方式。如果你刚刚部署的新版本无法启动 —— 可能是因为无法找到新增的环境变量而抛出异常,也可能是有一个库依赖不满足,或者只是你今天出门时没看黄历 —— 此时并没有老版本的服务实例来负载用户请求。你的服务此时至少是部分不可用的。
此外,如果有用户相关的问题或更微妙的运维问题 —— 我把它叫做 发布风险 —— 原地发布会将线上请求暴露给你已发布的所有实例。
在集群环境中,您可能会首先原地发布一个实例。这种做法通常称为 金丝雀 发布,它可以减轻一些风险 —— 面临部署风险和发布风险的流量的百分比为:新服务实例的个数除以集群中的实例总数。
一个金丝雀发布:集群中的一个主机运行新版本
最后,回滚错误的原地部署可能会有问题。即使你回滚(重新发布)到旧版本,也无法保证可以恢复到以前的系统状态。与当前错误的部署一样,你的回滚部署在启动时也可能会失败。
尽管其风险管理相对较差 —— 即便使用金丝雀,一些用户请求也会面临部署风险 —— 原地部署仍旧是业务中常见的方式。我认为这类的经验会导致不幸地混用「部署」和「发布」这两个术语。
别绝望
我们可以做得更好!在 这篇文章的第二部分 ,我们会讨论分离部署和发布的策略,以及可以在复杂的发布系统上构建的一些强大工作流。
我是 Turbine Labs 的一名工程师,我们正在构建 Houston ,这个服务可以轻松构建和监控复杂的实时发布工作流程。如果你想轻松地上线更多服务,你绝对应该 联系我们 。我们很乐意与你交谈。
感谢 Glen Sanford、Mark McBride、Emily Pinkerton、Brook Shelley、Sara 和 Jenn Gillespie 阅读此文的草稿。
感谢 Glen D Sanford 。

.png) 大数据引擎
大数据引擎.png) 大数据应用
大数据应用.png) 大数据底层技术
大数据底层技术.png) ForeSpider软件
ForeSpider软件
.png) 采集服务
采集服务.png) 软件学习
软件学习.png) 智能分析
智能分析.png) 特征提取
特征提取.png) 智能计算
智能计算.png) 数据可视化
数据可视化.png) 数据分析应用
数据分析应用.png) 系统集成服务
系统集成服务.png) 代码工具
代码工具.png) 金融方案
金融方案.png) 制造业&物流
制造业&物流.png) 企业数字化
企业数字化.png) 医疗方案
医疗方案.png) 政务方案
政务方案.png) 实时监测
实时监测.png) 智能分析
智能分析.png) 数据智能挖掘
数据智能挖掘.png) 全网自动采集
全网自动采集.png) 场景智慧采集
场景智慧采集.png) 主题识别采集
主题识别采集







 022-2345 2937
022-2345 2937 185 2247 0110
185 2247 0110 business@forenose.com
business@forenose.com














 022-2345 2937
022-2345 2937 185 2247 0110
185 2247 0110 business@forenose.com
business@forenose.com 前嗅大数据
前嗅大数据