【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
本文将解读Rainbond集群的安装和运维的原理,使用户基本了解Rainbond的安装机制和运维重点,便于用户搭建大型Rainbond集群。
1.Rainbond集群节点概述
1.1 节点分类
属性 类型 说明
manage | 管理节点 | 集结平台自身组件,提供应用构建、调度、管理等功能,提供数据中心基础服务与API接口,充当控制集群的角色。
gateway | compute
网关节点 | 计算节点
集群内应用被外网访问的流量入口和负载均衡器,提供HTTP, HTTPs路由, TCP/UDP服务, 负载均衡器, 高级路由(A/B测试, 灰度发布)等功能。 | 提供应用运行的计算资源,N个计算节点组成计算资源池供给管理节点灵活调度。
1.2 节点部署主要服务组件概述
角色 组件 说明 | rbd-dns | 提供本地dns服务,服务于集群内应用的DNS解析。 | | etcd | 管理节点etcd |
|---|
| kube-controller-manager | Kubernetes管理组件之一, Pod编排器 | | rbd-webcli | 提供应用web方式进入容器命令行的服务 | | nfs_server | 远程存储挂载 | | rbd-hub | 基于Docker Registry封装,提供Docker镜像存储服务,服务于数据中心内部 | | kube-scheduler | Kubernetes管理组件之一,Pod调度器 | | docker | 应用容器引擎 | | rbd-mq | 消息队列服务 | | calico | 集群SDN服务,为应用提供网络支持 | | rbd-chaos | 应用构建服务,提供源码,Docker镜像等方式持续构建应用。 | | rbd-worker | 应用运行控制器 | | kube-apiserver | Kubernetes管理组件之一, 提供API服务 | | rbd-eventlog | Rainbond 事件处理与日志汇聚服务 | | rbd-monitor | Rainbond 监控管理服务,基于Prometheus封装 | | rbd-api | Rainbond API服务,数据中心控制层面的入口。 | | rbd-db | Rainbond 数据库服务,支持MySQL,Tidb与CockroachDB | | rbd-app-ui | 应用控制台web服务 | | rbd-repo | 源码构建仓库服务,基于Artifactory OSS封装 | | node | Rainbond 集群和节点控制器服务 | | etcd-proxy | 计算节点etcd-proxy | | | rbd-dns | Rainbond内部dns服务,与管理节点DNS服务共同对当前节点的应用提供DNS解析 | | kubelet | Kubernetes 计算负载节点组件 | | docker | 应用容器引擎 | | calico | 集群SDN服务,为应用提供网络支持 | | node | Rainbond节点控制器,提供服务守护、自动运维、日志收集、服务发现等服务。 | | 网关节点 | docker | 应用容器引擎 | | calico | 集群SDN服务,为应用提供网络支持 |
rbd-dns | rbd-gateway
Rainbond内部dns服务,可作为集群dns服务使用 | |
1.3 节点规划
一个完整的Rainbond集群中必须包含manage、gateway、compute角色的节点和暂不作为Rainbond安装支持的存储节点,当然三种属性可以在同一个节点上组成单节点的Rainbond集群。安装Rainbond之前需要根据企业自身需求合理的规划计算资源,这里主要是指物理机或虚拟机节点。
从上文中列举的主要Rainbond服务组件来综合分析,管理节点的合理规划是关键。
Rainbond的主要数据存储组件是: Etcd
根据Etcd集群组建特性,其必须部署为1,3,5奇数节点。 Mysql
Mysql数据库的部署模式主要有主从、多主等模式, Rbd-monitor(Prometheus)
Prometheus具有单机自治特性,因此每一个Rbd-monitor节点都是独立的数据采集和存储,基本上可以认为多节点数据是一致的。
Rainbond安装脚本对Etcd,Rbd-monitor做了较好的自动安装支持,对于Mysql数据库,我们更建议用户独立安装Mysql数据库并提供给Rainbond安装脚本。管理节点其他的组件基本上可以认为是无状态的,或有状态的组件都自身实现了良好的工作节点选举。对部署节点数无关键要求。因此我们推荐的管理节点数量是3个及以上。
网关节点处理流量入口,每一个Rainbond节点目前都独立提供了所有访问策略的支持,因此上层可以采用4层负载均衡策略或VIP策略,因此我们推荐的节点数量是2个及以上。
计算节点提供计算负载,节点越多,集群计算容量越大,因此计算节点的规划取决于集群需要运行的应用数量,随时可以增加或下线节点。因此我们推荐的节点数量是2个及以上。
2. 安装原理说明
Rainbond-Ansible 项目是Rainbond子项目之一,提供Rainbond集群便捷的安装支持,采用Ansible自动化部署框架实现。其具有安装简单、工作原理简单、模块化、生态完善等特点。 早期我们采用了 SaltStack 实现,其工作模式复杂,不透明的节点通信机制。Rainbond安装过程受限于SaltStack的稳定性,因此我们从5.0版本后对安装脚本进行了重构。
2.1 安装脚本结构 . ├── callback_plugins # 任务失败时打印帮助消息回调插件 │ └── help.py # 回调插件示例 ├── hack # 部署本地资源文件目录 │ ├── chinaos # 操作系统的安装包源 │ │ ├── CentOS-Base.repo # CentOS的源 │ │ ├── centos-release # CentOS的全局配置 │ │ ├── sources.list # Ubuntu的源 │ │ ├── ubuntu-lsb-release # Ubuntu的版本配置 │ │ └── ubuntu-release # Ubuntu的全局配置 │ ├── docker # Docker部署资源文件目录 │ │ ├── get-docker.sh # 快速部署Docker脚本 │ │ └── rainspray.list # 快速部署Docker的Ubuntu源 │ ├── files # 好雨工具包 │ │ ├── bin # grctl的二进制文件 │ │ ├── health # 健康监测脚本 │ │ ├── ssh # ssh配置脚本 │ │ └── ssl # 好雨加密证书 │ ├── manifests # 应用配置文件 │ │ ├── dashboard # 仪表盘-配置 │ │ ├── efk # efk-配置 │ │ ├── es-cluster # es集群-配置 │ │ ├── heapster # heapster-配置 │ │ ├── ingress # ingress-配置 │ │ ├── jenkins # jenkins-配置 │ │ ├── metrics-server # metrics-配置 │ │ ├── prometheus # prometheus-配置 │ │ └── storage # storage-配置 │ ├── step # Ansible安装步骤剧本 │ │ ├── 00.prepare.yml # 安装前检测 │ │ ├── 01.docker.yml # docker-配置 │ │ ├── 02.image.yml # image-配置 │ │ ├── 10.etcd.yml # etcd-配置 │ │ ├── 11.kube-master.yml # kube-master-配置 │ │ ├── 12.kube-worker.yml # kube-worker-配置 │ │ ├── 13.network.yml # network-配置 │ │ ├── 20.db.yml # database-配置 │ │ ├── 21.storage.yml # storage-配置 │ │ ├── 22.lb.yml # lb-配置 │ │ ├── 23.node.yml # node-配置 │ │ └── 90.setup.yml # setup-配置 │ ├── thirdparty # 第三方服务对接 │ │ ├── addmaster.yml # 增加master-role │ │ ├── addnode.yml # 增加node-role │ │ └── setup.yaml # 配置安装 │ ├── tools # 工具包目录 │ │ ├── get_images.sh # 拉取docker镜像 │ │ ├── update-domain.sh # 更换域名 │ │ └── yc-ssh-key-copy.sh # 批量部署服务器ssh-key │ ├── upgrade # 升级配置目录 │ │ └── upgrade.yml # 升级配置文件 │ ├── vagrant # vagrant服务配置目录 │ │ ├── README.md # 说明文件 │ │ ├── Vagrantfile # ruby获取系统信息 │ │ ├── install.sh # 安装文件 │ │ └── setup.sh # 配置文件 │ └── windows # windows节点配置目录 │ ├── cni # 配置文件目录 │ ├── scripts # 脚本目录 │ │ ├── helper.psm1 # 帮助信息脚本 │ │ ├── hns.psm1 # hns配置脚本 │ │ ├── start-flannel. # 开启flannel脚本 │ │ ├── start-kubelet. # 开始kubelet脚本 │ │ └── start-node.ps1 # 开始node服务脚本 │ ├── README.md # 说明文件 │ ├── daemon.json # 域名配置 │ ├── net-conf.json # 网络配置 │ └── win.yaml # Windows配置 ├── inventory # Ansible剧本执行主机 │ ├── hosts.all # 主机模版 │ └── hosts.master # 主机模版 ├── log # 日志文件目录 ├── offline # 离线安装配置文件目录 │ ├── image # 离线包制作脚本目录 │ │ ├── download.sh # 缓存docker离线镜像脚本 │ │ ├── image.txt # rainbond镜像列表 │ │ ├── load.sh # 加载离线缓存镜像包脚本 │ │ └── offimage.sh # 压缩理想缓存镜像包脚本 │ └── pkgs # 离线包存储目录 │ ├── Dockerfile.centos # 构建离线CentOS镜像 │ ├── Makefile # 构建离线CentOS镜像 │ ├── README.md # 说明文档 │ ├── download.centos # 创建本地CentOS源 │ └── rbd.repo # Centos源 ├── scripts # 部署脚本存放目录 │ ├── installer # 安装脚本目录 │ │ ├── default.sh # 默认网络配置脚本 │ │ ├── functions.sh # 安装的示例库脚本 │ │ └── global.sh.example # 全局变量示例脚本 │ ├── op # 网络配置目录 │ │ ├── README.md # 说明文件 │ │ ├── lb.sh # 配置lb服务脚本 │ │ └── network.sh # 配置网络脚本 │ ├── upgrade # 升级脚本目录 │ │ └── upgrade.sh # 升级脚本文件 │ ├── yaml # 网络配置剧本目录 │ │ ├── init_network.yaml # 初始化网络剧本 │ │ └── reset_network.yaml # 重置网络剧本 │ └── node.sh # 用于管理节点脚本 ├── test # 测试剧本语法脚本目录 │ ├── hosts.ini # 主机配置信息 │ ├── k8s-master.role.1.j2 # k8s-master配置信息 │ ├── k8s-worker.role.1.j2 # k8s-worker配置信息 │ ├── kubelet.sh.1.j2 # kubelet配置信息 │ └── test.sh # 检测Ansible剧本语法脚本 ├── roles # Ansible部署规则配置文件目录 │ ├── bootstrap # bootstrap服务规则配置 │ ├── db # database服务规则配置 │ ├── docker # docker服务规则配置 │ ├── etcd # etcd服务规则配置 │ ├── k8s # k8s服务规则配置 │ ├── lb # lb服务规则配置 │ ├── monitor # monitor服务规则配置 │ ├── network_plugin # network_plugin服务规则配置 │ ├── node # node服务规则配置 │ ├── prepare # prepare服务规则配置 │ ├── rainvar # rainvar服务规则配置 │ ├── storage # storage服务规则配置 │ ├── thirdparty # thirdparty服务规则配置 │ └── upgrade # upgrade服务规则配置 ├── docs # 说明文档文件夹 ├── CHANGELOG.md # 版本迭代说明 ├── Dockerfile # 创建rainbond-ansible的Ubuntu镜像源 ├── LICENSE # 开发协议 ├── Makefile # 语法检测配置 ├── README.md # 说明文件 ├── addmaster.yml # 增加master节点剧本 ├── addnode.yml # 增加node节点剧本 ├── ansible.cfg # Ansible程序配置优化 ├── lb.yml # 增加lb节点剧本 ├── setup.sh # 主安装脚本入口 ├── setup.yml # Ansible本地安装剧本 ├── upgrade.yml # Ansible升级剧本 └── version # 安装包版本
2.2 ansible-playbook各角色剧本
角色 剧本 说明 | manage | rainvar | 初始化私有数据中心的一些默认配置(数据库、端口、安装路径、安装版本等) | bootstrap | 对本节点的内核进行优化(tcp_tw_recycle、core.somaxconn、syncookies、file-max等) |
|---|
| prepare | 对本节点安装条件进行检查(系统版本、CPU、内存、磁盘、内核等) | | storage/nfs/client | 以nfs方式挂载本节点的存储卷 | | storage/nas | 以nas方式挂载本节点的存储卷 | | storage/gfs | 以gfs方式挂载本节点的存储卷 | | docker/install | 在本节点上安装Docker服务 | | k8s/manage | 在本节点上安装k8s服务的管理端 | | etcd/manage | 在本节点上安装etcd服务的管理端 | | gateway | 在本节点上安装负载均衡组件 | | monitor | 在本节点上安装监控组件 | | network_plugin/calico | 切换docker网络为calico | | network_plugin/flannel | 切换docker网络为flannel | | node/exm | 安装基础依赖包(python-pip、ansible) | | node/core | 在本节点安装node核心组件 | | gateway | rainvar | 初始化私有数据中心的一些默认配置(数据库、端口、安装路径、安装版本等) | | bootstrap | 对本节点的内核进行优化(tcp_tw_recycle、core.somaxconn、syncookies、file-max等) | | prepare | 对本节点安装条件进行检查(系统版本、CPU、内存、磁盘、内核等) | | storage/nfs/client | 以nfs方式挂载本节点的存储卷 | | storage/nas | 以nas方式挂载本节点的存储卷 | | storage/gfs | 以gfs方式挂载本节点的存储卷 | | docker/install | 在本节点上安装Docker服务 | | network_plugin/calico | 切换docker网络为calico | | network_plugin/flannel | 切换docker网络为flannel | | gateway | 在本节点上安装负载均衡组件 | | node/exlb | 在本节点安装node负载组件 | | compute | rainvar | 初始化私有数据中心的一些默认配置(数据库、端口、安装路径、安装版本等) | | bootstrap | 对本节点的内核进行优化(tcp_tw_recycle、core.somaxconn、syncookies、file-max等) | | prepare | 对本节点安装条件进行检查(系统版本、CPU、内存、磁盘、内核等) | | storage/nfs/client | 以nfs方式挂载本节点的存储卷 | | storage/nas | 以nas方式挂载本节点的存储卷 | | storage/gfs | 以gfs方式挂载本节点的存储卷 | | docker/install | 在本节点上安装Docker服务 | | k8s/compute | 在本节点上安装k8s服务的客户端 | | etcd/compute | 在本节点上安装etcd服务的客户端 | | network_plugin/calico | 切换docker网络为calico | | network_plugin/flannel | 切换docker网络为flannel |
gateway | node/core
在本节点上安装负载均衡组件 | 在本节点安装node核心组件 |
2.3 安装脚本部署流程
2.3.1 集群初始化
集群初始化包括三个重要步骤,安装脚本获取、安装环境构建和第一个节点的安装。 ./grctl init 各种参数 安装脚本获取
grctl init 命令从github仓库获取指定版本的ansible代码,如果离线安装没有此步骤。 安装环境构建
grctl init 命令根据用户指定的参数和默认值生成ansible global.sh 全局配置文件。 配置文件: /opt/rainbond/rainbond-ansible/scripts/installer/global.sh 主要配置: INSTALL_TYPE # 安装类型(离线/联网) DEPLOY_TYPE # 节点类型 DOMAIN # 域名 VERSION # 版本 STORAGE # 存储类型 STORAGE_ARGS # 挂载参数 NETWORK_TYPE # 网络类型 ROLE # 第一个节点角色(默认manage、gateway、compute)
这里的参数主要是指定Rainbond集群在存储、网络、安装模式等关键参数。 第一个节点安装
单一节点的安装根据传入role角色属性,传递属性给主安装脚本 setup.sh
主安装脚本在进行本地节点系统优化之后调用ansible-playbook使用 setup.yml 剧本进行第一个节点部署
剧本主要根据master主机组的role进行配置装机(系统优化、组件部署)
2.3.2 compute、gateway节点扩容安装 传入需要安装的role角色属性(compute,gateway),传递给主安装脚本 setup.sh 主安装脚本在进行远程节点系统优化之后调用ansible-playbook使用角色对应的剧本进行部署 manage 角色属性调用 addmaster.yml compute 角色属性调用 addnode.yml gateway 角色属性调用 gateway.yml 剧本主要根据主机组所使用的role进行配置装机(系统优化、组件部署)
3. 集群安装流程 graph LR subgraph 初始化过程 id1(grctl)==>id2(setup.sh) id2(setup.sh)==>id3(ansible-playbook) end
3.1 grctl init 初始化过程
grctl init 命令首先获取安装包,然后根据传入的参数以键值对的方式转换为shell脚本变量,以全局变量的方式对后续操作进行参数的传递,后续步骤读取全局变量,达到安装过程中对可变因素的掌控。 在未来的版本中,grctl命令行进一步控制ansible的主机列表,准确的为ansible提供集群主机序列。
3.2 shell 初始化过程
grctl 命令完成参数配置后调用安装脚本 /opt/rainbond/rainbond-ansible/setup.sh 进行第一个节点初始化。
脚本首先会对操作系统进行优化。这里是安装过程使用网络的主要点,在线安装模式下,操作系统的更新和配置,安装包的下载通过网络进行。离线安装模式下使用事先准备的本地安装源对操作系统进行基础环境安装,然后使用事先下载好的安装包。后续的节点安装过程将不再使用网络。
最后会调取ansible-play使用 setup.yml 剧本进行初始化安装。
3.3 ansible-playbook 初始化过程
ansible-playbook使用 setup.yml 进行初始化,首先会找到当前主机所在的主机组,之后根据role的设定到不同的组件文件夹中根据pre_task -> roles -> tasks -> post-tasks 的顺序依次执行文件夹下面的 main.yml 达到组件安装的作用
3.4 其他角色节点扩容安装 grctl node add --host <计算节点主机名> --iip <计算节点内网ip> --root-pass <计算节点root密码> --role gateway,compute 指定新增节点的 主机名、内网地址、连接密码、角色 , grctl命令行首先将节点数据加入集群元数据。通过 grctl node list 命令即可查询节点状态。 使用 grctl node install host-uuid 命令安装节点,grclt从API中读取相应的主机信息传递给 node.sh 脚本进行节点的安装。 node.sh 在 script/node.sh 中,主要获取以下几个参数: node_role # 新增节点的角色 node_hostname # 新增节点的主机名 node_ip # 新增节点的网络地址 login_type # 新增节点的登陆方式 login_key # 新增节点的连接密码 node_uuid # 新增节点的uuid node.sh 脚本首先会判断 node_role 中传递的角色属性,循环角色属性判断 inventory/hosts 中相应的主机组中是否存在对应的主机,没有根据不同的角色属性加入到相应的主机组中进行装机,在维护 inventory/hosts 之后会进行连接检测通过 login_type、login_key、node_uuid、node_ip、node_hostname 参数进行主机连接检测、通过之后会调用 ansible-playbook -i inventory/hosts -e $node_role role.yml 进行不同角色的装机: -i 指定装机主机 -e 将 grctl 传递给 setup.sh 的 node_role 参数传递给 ansible-playbook 生成对应的 node组件角色配置文件 role.yml 不同角色对应不同的yml配置文件 addmaster.yml # master role addnode.yml # compute role gateway.yml # gateway role 在5.1.6版本中hosts文件的维护将移交到grctl命令行工具中,根据集群节点状态实时生成。
4. 节点服务运维
Rainbond集群安装的所有组件有两种运行方式: node组件和docker组件是直接二进制运行,其他组件全部采用容器化运行。两种运行方式都是直接采用systemd守护进程进行守护。因此能够安装Rainbond的操作系统必须具有systemd。
在集群自动化运维的需求下,我们需要对节点(特别是计算节点)进行实时全面的健康检查,以确认节点是否可用。这个工作由node服务进行,它会根据 /opt/rainbond/conf 目录下配置对当前节点的配置检查项进行监控,如果出现故障汇报到集群管理端,如果是计算节点则会由集群管理端决策是否暂时禁止调度或下线该节点。 graph LR subgraph 服务运维流程 id1(systemd)==>id2(node.service) id2(node.service)==>id3(健康检测) id2(node.service)==>id4(守护进程) end
4.1 systemd的配置文件生成(node.service) 在集群初始化完成之后ansible会在 /etc/systemd/system/node.service 目录下生成 node.service 的配置文件, node 服务在 systemd 中以守护进程方式启动运行。 node服务启动后将读取 /opt/rainbond/conf 目录下的配置生成每一个需要启动服务的systemd配置文件并调用systemctl工具启动服务。
配置文件分为需求启动服务和只是健康检查项目,比如以下配置: - name: rbd-mq endpoints: - name: MQ_ENDPOINTS protocol: http port: 6301 health: name: rbd-mq model: http address: 127.0.0.1:6301/health max_errors_num: 3 time_interval: 5 after: - docker type: simple pre_start: docker rm rbd-mq start: >- docker run --name rbd-mq --network host -i goodrain.me/rbd-mq:V5.1-dev --log-level=debug --etcd-endpoints=${ETCD_ENDPOINTS} --hostIP=192.168.195.1 stop: docker stop rbd-mq restart_policy: always restart_sec: 10
该文件配置了rbd-mq服务的启动方式、健康检查方式和服务注册信息。
4.2 node组件的健康检测机制
每一个安装服务的健康检查配置见文档: 详细配置
若某项检查项目标识为不健康状态,当前节点将被标识为不健康状态。 对于不健康的节点Rainbond提供两级自动处理机制: 检测到异常的服务一段时间依然未恢复(取决于配置的时间段)将自动重启服务。 若计算节点被标注为不健康,节点控制器将会自动将其禁止应用调度直到节点恢复健康。 配置文件: /opt/rainbond/conf/health.yaml name # 需要检测的服务名称 model # 以什么方式检测(tcp/http/cmd) address # 被检测服务的地址 max_errors_num # 最大错误次数 time_interval # 每次检测次数 目前检测方式有3种 cmd # 使用脚本或者命令行 tcp # 使用ip:port模式 http # 使用http协议检测
4.3 集群故障查询和处理
根据整个集群节点的健康检查机制,用户在管理节点通过 grctl cluster 命令即可查询整个集群的故障点,或使用监控报警系统及时发现集群故障。当集群某个节点出现问题时首先定位故障的服务,并查看其运行日志处理故障。如果有未完善的健康检测项目,用户可以通过上诉节点健康检测配置方式自定义检测项目。
5. 常见安装问题解决思路 端口被占用无法安装 Rainbond是一个完整的PaaS平台解决方案,所以强烈建议使用干净的物理机或虚拟机安装Rainbond。 Rainbond网关节点直接承接应用访问流量,因此其默认占用80\443等关键端口。另外Rainbond安装Ansible默认使用的SSH端口是22,严格运维时需要设置。 数据库安装初始化失败 Rainbond 5.1.5及之前版本默认安装的mysql数据库版本是mariadb 10,其所需的内存资源是较大的。如果你的机器资源有限很大可能导致安装失败。后续的版本中我们将默认安装的数据库版本升级到Mysql 5.7系列。 高可用安装怎么做 本文主要描述了整个安装原理,因此你阅读本文应该可以总结出Rainbond高可用安装的关键,我们近期也会再次更新高可用安装操作指南。 Rainbond能否安装在Mac或Windows系统 Rainbond计算节点可以支持Windows操作系统来运行Windows应用,目前Windows的支持是企业版功能之一,因此开源安装脚本暂不支持Windows 节点的快速安装。Mac操作系统不适合安装Rainbond。开发者可以将部分组件运行在Mac下运行开发。 遇到其他安装问题怎么办? 移步 https://github.com/goodrain/rainbond-ansible/issues 查找或提交你的问题。
Rainbond项目官网 【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
2019年8月12日,Rainbond发布5.1.6版本,本次版本更新带来了更简化的Rainbond高可用安装方案,解决了社区用户反馈的BUG问题。 Rainbond:支撑企业应用开发、架构、交付和运维的全流程,通过“无侵入”架构无缝衔接各类企业应用,底层资源可以对接和管理IaaS、虚拟机、物理服务器。 发布版本:5.1.6 版本更新:推荐 更新范围:高可用安装
高可用安装
在本次版本更新中,为了是用户高可用安装Rainbond更加简单,我们对Rainbond安装脚本项目进行了如下调整: Ansible主机列表配置从脚本维护更改为安装工具从集群获取节点数据进行维护,使主机列表信息准确表达。 调整节点角色安装策略,支持灵活的角色组合安装和增量角色安装。 调整部分服务的部署配置参数,降低在资源有限环境下的部署失败率。 更改API证书签发逻辑,默认使用外网IP地址作为证书签发目标。 更改外部数据库的支持策略以支持阿里云RDS数据库。
基于安装脚本的调整,我们提供了两篇高可用安装文档供用户参考:
1. 基于阿里云高可用安装Rainbond平台
2. 私有云环境下高可用安装Rainbond平台
BUG修复 修复在批量多个服务构建时代码缓存目录冲突导致部分服务构建失败的问题 修复环境变量值存储最大限制256导致部分环境变量无法设置的问题,更改为最大限制1024 goodrain/rainbond#338 修复镜像创建服务时私有用户名密码长度限制过低导致无法设置账号密码问题 goodrain/rainbond#352 修复共享存储、本地存储无法修改挂载路径的问题 goodrain/rainbond#347 修复性能分析插件、入口网络治理插件同时开启时无法进行性能分析的问题 goodrain/rainbond#318 修复Pod状态错误时导致平台统计租户使用资源错误的问题 goodrain/rainbond#328 修复node日志收集模块获取容器元数据失败导致node奔溃的问题 goodrain/rainbond#331 修复镜像创建服务时识别限制内存值不为2的n次方,导致无法水平升级问题。 goodrain/rainbond-console#186 修复版本管理中构建失败的版本依然提供升级选项的问题 goodrain/rainbond-console#207 修复网关访问策略编辑时丢失https配置的问题 goodrain/rainbond-ui#174 Java类服务构建源设置,更改OracleJDK设置为自定义JDK设置,便于用户发散性使用此功能。 goodrain/rainbond-ui#169 修复应用管理页面的便捷添加组件中的从应用市场安装搜索问题和无法安装的问题 goodrain/rainbond-ui#166 修复依赖服务连接信息显示不全的问题 goodrain/rainbond-ui#171
版本升级
升级要求和注意事项 V5.1.6版本支持从V5.1.2 - V5.1.6版本升级,如果你还未升级到V5.1.2版本,参考 V5.1.x版本升级文档 ,先升级至V5.1.2版本:
grctl version , 例如5.1.5版本显示如下: Rainbond grctl v5.1.5-release-381a1da-2019-07-12-15 升级过程会重启管理服务,因此只有单管理节点的集群会短暂影响控制台操作,请选择合理的升级时间段 。 升级过程脚本需要从集群获取节点数据,请务必在集群正常工作情况下进行升级。
下载 5.1.6 更新包 离线包镜像大小约1.3GB,需要保证当前集群磁盘可用空间至少不低于2G # Rainbond 组件升级包 wget https://pkg.rainbond.com/offline/5.1/rainbond.images.2019-08-11-5.1.6.tgz -O /grdata/services/offline/rainbond.images.upgrade.5.1.6.tgz # 升级脚本包 wget https://pkg.rainbond.com/offline/5.1/rainbond-ansible.upgrade.5.1.6.tgz -O /grdata/services/offline/rainbond-ansible.upgrade.5.1.6.tgz
第一个管理节点执行下述命令升级平台 rm -rf /tmp/rainbond-ansible rm -rf /grdata/services/offline/upgrade mkdir -p /tmp/rainbond-ansible tar xf /grdata/services/offline/rainbond-ansible.upgrade.5.1.6.tgz -C /tmp/rainbond-ansible cd /tmp/rainbond-ansible/scripts/upgrade/ bash ./upgrade.sh
平台升级完成验证 执行 grctl cluster 确定所有服务和节点运行正常 grctl version 确认版本已升级到5.1.6,运行组件镜像版本为 v5.1.6-release
插件升级
本次版本更新了性能分析插件,请在平台完成升级后按照如下方式升级插件: 管理节点执行以下命令: docker pull rainbond/plugins-tcm:5.1.6 docker tag rainbond/plugins-tcm:5.1.6 goodrain.me/tcm docker push goodrain.me/tcm 进入平台,不同的团队分别进入插件管理,选择性能分析插件,点击插件的构建。 更新使用当前插件的服务,插件即可生效。
福利来了:
每周三晚上8:30,开源Rainbond产品【线上培训】调整为开源Rainbond用户【线上沙龙】,内容变得更丰富。在每一期的精心选题的基础上,又增加了开源爱好者的互动环节。
【线上交流沙龙 第十期预告】Rainbond高可用集群安装上手、新版本解读。
查看往期: https://www.rainbond.com/video.html
【第一期】Jenkins Pipeline 对接Rainbond用法培训
【第二期】SpringCloud微服务架构应用部署到Rainbond用法培训
【第三期】Eurka集群部署,SpringCloud微服务架构升级培训
【第四期】Java生态的微服务无侵入链路追踪
【第五期】Rainbond 应用市场解读
【第六期】滚动、蓝绿、灰度如何在Rainbond实现
【第七期】服务熔断和全局限流如何在Rainbond实现
【第八期】Rainbond日志管理与插件制作教程
【第九期】Rainbond安装与运维原理解读
参与方式:添加微信进群⬇️
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
Pod是K8S调度的基本单位,一个Pod中包含了一个Pause容器(根容器)和多个用户容器。Pause容器的状态代表了Pod的状态,同一个Pod中的容器共享相同的ip和数据卷。
因此,Pod的创建首先要构建一个Sandbox,包含pause容器并初始化网络/数据卷等一系列资源。
1.sandbox构建
创建一个Pod首先必须要构建一个Sandbox,创建流程如下:
createPodSandbox是创建的入口方法,包含两个步骤:
generatePodSandboxConfig - 构造sandbox的config,当中涉及到通过Kubelet生成sandbox的cgroupParent
RunPodSandBox - 通过Docker Service(dockershim)来创建sandbox的container并启动。包含四个主要步骤:1. pull image; 2. create container; 3. start container; 4. init network
经过以上两个步骤,pod所需的sandbox就运行起来了,同时初始化好了网络/数据卷等资源。
2.用户Container创建
建立了运行的SandBox之后,就可以创建用户Container,并加入到Pod中。主要流程如下:
主要包含三个步骤:
EnsureImageExists - 拉取镜像
CreateContainer - 通过CRI & dockershim创建容器实例
StartContainer - 运行实例 【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
本文作者:yunzhixueyuan
百度大脑开放日·AI战疫专场
直播时间:2020年3月13日15:00-16:00
百度大脑自2016年启动开放以来,已打造成为业内最全面、最领先的AI开放平台,服务规模、调用量都居于业界第一。
百度大脑开放日于2019年开办,覆盖北/上/深等地与众多AI开发者、合作伙伴近距离沟通及深度交流,一起分享百度大脑最新产品和应用案例。
2020我们再度起航,结合当下疫情,推出了百度大脑开放日“AI战疫”专场,将于3月13日通过直播形式与大家见面,全面解析百度大脑在疫情期间助力“抗疫”所开放的能力及应用案例,同时也将分享更多百度大脑新近技术能力。
敬请期待!
直播议程:
一、百度大脑“AI开发者战疫守护计划”详解
二、百度大脑“AI战疫”应用案例解析
1、口罩检测及红外测温方案助力公共卫生防控
2、 飞桨 开源助力智能诊疗
3、OCR赋能社区防疫与高效信息采集
4、语音技术让在线教与学更轻松
三、百度大脑新近开放能力介绍
四、Q&A
直播嘉宾:双双 百度AI技术生态部高级产品经理
原文链接地址: https://developer.baidu.com/topic/show/290680 【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
MicroK8s与K3s都是基于Kubernetes的轻量级发行版,主要面向工作站、边缘计算、物联网等应用场景,但二者也有比较大的区别。
主要区别 MicroK8s主要将一些扩展件集成到系统中,而K3s却将很多扩展件独立出来。 虽然MicroK8s与K3s都能支持ARM体系的低功耗计算,但是MicroK8s主打使用方便性,也更适合开发团队使用,而K3s主打轻量化,更适合低功耗的小型化无人值守的自动化系统使用。 MicroK8s的集群管理内核与Kubernetes标准版的容器镜像是完全一样的,而K3s的内核进行了一些修改,部分模块可能由于兼容性问题无法运行。
K3s修改的部分
主要包括:
删除 过时的功能和非默认功能 Alpha功能 内置的云提供商插件 内置的存储驱动 Docker (可选)
新增 简化安装 除etcd外,还支持SQLite3数据存储 TLS管理 自动的Manifest和Helm Chart管理 containerd, CoreDNS, Flannel
MicroK8s主要的变化
主要包括: 基于snap的安装工具。 kubectl的命名空间化,变为microk8s.kubectl。 各种扩展模块的版本适配,本地存储的直接支持。 各种addon动态加载模块,支持快速Enable/Disable。 内置的GPU支持。
更多参考 K3s官方文档 k3s/k3OS-轻量级Kubernetes及操作系统 MicroK8s 快速入门 Ubuntu发布Microk8s及其GPU支持 MicroK8s-部署到Windows、macOS和Raspberry Pi KubeFlow-在Microk8s部署与应用 【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
本文作者:oschina_2020
移动开发领域近年来已经逐渐告别了野蛮生长的时期,进入了相对成熟的时代。而一直以来 Native 和 Web 的争论从未停止,通过开发者孜孜不倦的努力,Web 的效率和 Native 的体验也一直在寻求着平衡。本文聚焦 iOS 开发和 Web 开发的交叉点,内容涉及到 iOS 开发中全部的 Web 知识,涵盖从基础使用到 WebKit、从 JSCore 到大前端、从 Web 优化到业务扩展等方面,希望通过简要的介绍,帮助开发者一窥 Hybrid 和大前端的构想。
iOS 中 Web 容器与加载
1. iOS 中的 Web 容器
目前 iOS 系统为开发者提供三种方式来展示 Web 内容,分别是 UIWebView、WKWebView 和 SFSafariViewController:
UIWebView
UIWebView 从 iOS2 开始就作为 App 内展示 Web 内容的容器,但是长久以来一直遭受开发者的诟病,它存在系统级的内存泄露、极高内存峰值、较差的稳定性、Touch Delay 以及 JavaScript 的运行性能和通信限制等问题。在 iOS12 以后已经被标记为 Deprecated 不再维护。 WKWebView
在 iOS8 中,Apple 引入了新一代的 WebKit framework,同时提供了 WKWebView 用来替代传统的 UIWebView,它更加稳定,拥有 60fps 滚动刷新率、丰富的手势、KVO、高效的 Web 和 Native 通信,默认进度条等功能,而最重要的是,它使用了和 Safari 相同的 Nitro 引擎极大提升了 JavaScript 的运行速度。WKWebView 独立的进程管理,也降低了内存占用及 Crash 对主 App 的影响。 SFSafariViewController
在 iOS9 中,Apple 引入了 SFSafariViewController,其特点就是在 App 内可以打开一个高度标准化的、和 Safari 一样界面和特性的页面。同时 SFSafariViewController 支持和 Safari 共享 Cookie 和表单数据。
这几中容器如何选择呢?
对于 SFSafariViewController,由于其标准化程度之高,使之界面和交互逻辑无法和 App 统一,基于 App 整体体验的考虑,一般都使用在相对独立的功能和模块中,最常见的就是在 App 内打开 App Store 或者广告、游戏推广的页面。
对于 UIWebView/WKWebView,如果说之前由于 NSURLProtocol 的问题,好多 App 都在继续使用 UIWebView,那么随着 App 放弃维护 UIWebView(iOS12),全部的 App 应该会陆续地切换到 WKWebView 中来。当然,最初 WKWebView 也为开发者们带来了一些难题,但是随着系统的升级与业务逻辑的适配也逐步得到修复,后文会列举几个最为关注的技术点。
UIWebView/WKWebView 对主 App 内存的影响:
2. WebKit 框架与使用
WebKit.framework
WebKit 是一个开源的 Web 浏览器引擎,每当谈到 WebKit,开发者常常迷惑于它和 WebKit2、Safari、iOS 中的框架,以及 Chromium 等浏览器的关系。
广义的 WebKit 其实就是指 WebCore,它主要包含了 HTML 和 CSS 的解析、布局和定位这类渲染 HTML 的功能逻辑。而狭义的 WebKit 就是在 WebCore 的基础上,不同平台封装 JavaScript 引擎、网络层、GPU 相关的技术(WebGL、视频)、绘制渲染技术以及各个平台对应的接口,形成我们可以用的 WebView 或浏览器,也就是所谓的 Webkit Ports。
比如在 Safari 中 JS 的引擎使用 JavascriptCore,而 Chromium 中使用 v8;渲染方而 Safari 使用 CoreGraphics,而 Chromium 中使用 skia;网络方而 Safari 使用 CFNetwork,而 Chromium 中使用 Chromium stack 等等。而 Webkit2 是相对于狭义上的 Webkit 架构而言,主要变化是在 API 层支持多进程,分离了 UI 和 Web 接口的进程,使之通过 IPC 来进行通讯。
iOS 中的 WebKit.framework 就是在 WebCore、底层桥接、JSCore 引擎等核心模块的基础上,针对 iOS 平台的项目封装,它基于新的 WKWebView,提供了一系列浏览特性的设置,以及简单方便的加载回调。
Web 容器使用流程与关键节点
对于大部分日常使用来说,开发者需要关注的就是 WKWebView 的创建、配置、加载、以及系统回调的接收。
对于 Web 开发者,业务逻辑一般通过基于 Web 页面中 Dom 渲染的关键节点来处理,而对于 iOS 开发者,WKWebView 提供的的注册、加载和回调时机,没有明确地与 Web 加载的关键节点相关联。准确地理解和处理两个维度的加载顺序,选择合理的业务逻辑处理时机,才可以实现准确而高效的应用。
WKWebView 常见问题
使用 WKWebView 带来的另外一个好处,就是我们可以通过源码理解部分加载逻辑,为 Crash 提供一些思路,或者使用一些私有方法处理复杂业务逻辑。 NSURLProtocol
WKWebView 最为显著的改变,就是不支持 NSURLProtocol,为了兼容旧的业务逻辑,一部分 App 通过 WKBrowsingContextController 中的非公开方法实现了 NSURLProtocol。 // WKBrowsingContextController + (void)registerSchemeForCustomProtocol:(NSString *)scheme WK_API_DEPRECATED_WITH_REPLACEMENT("WKURLSchemeHandler", macos(10.10, WK_MAC_TBA), ios(8.0, WK_IOS_TBA));
在 iOS11 中,系统增加了 setURLSchemeHandler 函数用来拦截自定义的 Scheme,但是不同于 UIWebView,新的函数只能拦截自定义的 Scheme(SchemeRegistry.cpp),对使用最多的 HTTP/HTTPS 依然不能有效地拦截。 //SchemeRegistry static const StringVectorFunction functions[] { builtinSecureSchemes, // about;data... builtinSchemesWithUniqueOrigins, // javascript... builtinEmptyDocumentSchemes, builtinCanDisplayOnlyIfCanRequestSchemes, builtinCORSEnabledSchemes, //http;https }; 白屏
通常 WKWebView 白屏的原因主要分两种,一种是由于 Web 的进程 Crash(多见于内部进程通信);一种就是 WebView 渲染时的错误(Debug 一切正常只是没有对应的内容)。对于白屏的检测,前者在 iOS9 之后系统提供了对应 Crash 的回调函数,同时业界也有通过判断 URL/Title 是否为空的方式作为辅助;后者业界通过视图树对比,判断 SubView 是否包含 WKCompsitingView,以及通过随机点截图等方式作为白屏判断的依据。 其它 WKWebView 的系统级问题 如 Cookie、POST 参数、异步 JavaScript 等,可以通过业务逻辑的调整重新适配。 由于 WebKit 源码的开放性 ,我们也可以利用私有方法来简化代码逻辑、实现复杂的产品需求。例如在 WKWebViewPrivate 中可以获得各种页面信息、直接取到 UserAgent、 在 WKBackForwardListPrivate 中可以清理掉全部的跳转历史、以及在 WKContentViewInteraction 中替换方法实现自定义的 MenuItem 等。 @interface WKWebView (WKPrivate) @property (nonatomic, readonly) NSString *_userAgent WK_API_AVAILABLE(macosx(10.11), ios(9.0)); ... @interface WKBackForwardList (WKPrivate) - (void)_removeAllItems; ... @interface WKContentView (WKInteraction) - (BOOL)canPerformActionForWebView:(SEL)action withSender:(id)sender;
3. App 中的应用场景
WKWebView 系统提供了四个用于加载渲染 Web 的函数,这四个函数从加载的类型上可以分为两类:加载 URL & 加载 HTML\Data。所以基于此也延伸出两种不同的业务场景:加载 URL 的页面直出类和加载数据的模板渲染类,同时两种类型各自也有不同的优化重点及方向。
页面直出类 //根据URL直接展示Web页面 - (nullable WKNavigation *)loadRequest:(NSURLRequest *)request;
通常各类 App 中的 Web 页面加载都是通过加载 URL 的方式,比如嵌入的运营活动页面、广告页面等等。
模板渲染类 //根据模板&数据渲染Web页面 - (nullable WKNavigation *)loadHTMLString:(NSString *)string baseURL:(nullable NSURL *)baseURL; ...
需要使用 WebView 展示,且交互逻辑较多的页面,最常见的就是资讯类 App 的内容展示页。
iOS 中 Web 与 Native 的通信
单纯使用 Web 容器加载页面已经不能满足复杂的功能,开发者希望数据可以在 Native 和 Web 之间通信传递来实现复杂的功能,而 JavaScript 就是通信的媒介。对于有 WebView 的情况,虽然 WKWebView 提供了系统级的方法,但是大部分 App 仍然使用基于 URLScheme 的 WebViewBridge 用以兼容 UIWebView。而脱离了 WebView 容器,系统提供了 JavascriptCore 的框架,它也为之后蓬勃发展的跨平台和热修复技术提供了可能。
1. 基于 WebView 的通信
基于 WebView 的通信主要有两个途径,一个是通过系统或私有方法,获取 WebView 当中的 JSContext,使用系统封装的基于 JSCore 的函数通信;另一类是通过创建自定义 Scheme 的 iframe Dom,客户端在回调中进行拦截实现。
UIWebView & WKWebView 系统级
在 UIWebView 时代没有提供系统级的函数进行 Web 与 Native 的交互,绝大部分 App 都是通过 WebViewJavascriptBridge(下节介绍)来进行通信,而由于 JavascriptCore 的存在,对于 UIWebView 来说只要有效的获取到内部的 JSContext,也可以达到目的。目前已知的有效获取 Context 的私有方法如下: //通过系统废弃函数获取context - (void)webView:(WebView *)webView didCreateJavaScriptContext:(JSContext *)context forFrame:(WebFrame *)frame; //通过valueForKeyPath获取context self.jsContext = [_webView valueForKeyPath:@"documentView.webView.mainFrame.javaScriptContext"];
在 WKWebView 中提供了系统级的 Web 和 Native 通讯机制,通过 Message Handler 的封装使开发效率有了很大的提升。同时系统封装了 JavaScript 对象和 Objective-C 对象的转换逻辑,也进一步降低了使用的门槛。 // js端发送消息 window.webkit.messageHandlers.{NAME}.postMessage() //Native在回调中接收 - (void)userContentController:(WKUserContentController *)userContentController didReceiveScriptMessage:(WKScriptMessage *)message; 拦截自定义 Scheme 请求 - WebViewJavascriptBridge
由于私有方法的稳定性与审核风险,开发者不愿意使用上文提到的 UIWebView 获取 JSContext 的方式进行通信,所以通常都采用基于 iframe 和自定义 Scheme 的 JavascriptBridge 进行通信。虽然在之后的 WKWebView 提供了系统函数,但是大部分 App 都需要兼容 UIWebView 与 WKWebView,所以目前的使用范围仍然十分广泛。
类似的开源框架有很多,但是无外乎都是 Web 侧根据固定的格式创建包含通信信息的 Request,之后创建隐式 iframe 节点请求;Native 侧在相应的 WebView 回调中解析 Request 的 Scheme,之后按照格式解析数据并处理。
而对于数据传递和回调处理的问题,在兼容两种 WebView、持续更新的 WebViewJavascriptBridge 中,iframe Request 没有直接传递数据,而是 Web 和 Native 侧维护共同的参数或回调 Queue,Native 通过 Request 中 Scheme 的解析触发对 Queue 里数据的读取。
2. 脱离 WebView 的通信 JavaScriptCore
JavascriptCore
JavascriptCore 一直作为 WebKit 中内置的 JS 引擎使用,在 iOS7 之后,Apple 对原有的 C/C++ 代码进行了 OC 封装,成为系统级的框架供开发者使用。作为一个引擎来讲,JavascriptCore 的词法、语法分析,以及多层次的 JIT 编译技术都是值得深入挖掘和学习的方向,由于篇幅的限制暂且不做深入的讨论。
JavascriptCore.framework
虽然 JavascriptCore.framework 只暴露了较少的头文件和系统函数,但却提供了在 App 中脱离 WebView 执行 JavaScript 的环境和能力。 JSVirtualMachine:提供了 JS 执行的底层资源及内存。虽然 Java 与 JavaScript 没有一点关系,但是同样作为虚拟机,JSVM 和 JVM 做了一部分类似的事情,每个 JSVirtualMachine 独占线程,拥有独立的空间和管理,但是可以包含多个 JSContext。 JSContext:提供了 JS 运行的上下文环境和接口,可以不准确地理解为,就是创建了一个 JavaScript 中的 Window 对象。 JSValue:提供了 OC 和 JS 间数据类型的封装和转换 Type Conversions。除了基本的数据类型,需要注意 OC 中的 Block 转换为 JS 中的 function、Class 转换为 Constructor 等等。 JSManagedValue:JavaScript 使用 GC 机制管理内存,而 OC 采用引用计数的方式管理内存。所以在 JavascriptCore 使用过程中,难免会遇到循环引用以及提前释放的问题。JSManagedValue 解决了在两种环境中的内存管理问题。 JSExport:提供了类、属性和实例方法的调用接口。内部实现是在 ProtoType & Constructor 中实现对应的属性和方法。
使用 JavascriptCore 进行通信
对于 JavascriptCore 粗浅的理解,可以认为使用 Block 方法,内部是将 Block 保存到一个 Web 环境中的全局 Object 中,例如 Window,而使用 JSExport 方法,则是在 Web 环境中 Object 的 prototype 中创建属性、实例方法,在 constructor 对象中创建类方法,从而实现 Web 中的调用。 Native - Web:通过 JavascriptCore,Native 可以直接在 Context 中执行 JS 语句,和 Web 侧进行通信和交互。 JSValue *value = [self.jsContext evaluateScript:@"document.cookie"]; Web - Native:对于 Web 侧向 Native 的通信,JavascriptCore 提供两种方式,注册 Block & Export 协议。 //Native self.jsContext[@"addMethod"] = ^ NSInteger(NSInteger a, NSInteger b) { return a + b; }; //JS console.log(addMethod(1, 2)); //3 //Native @protocol testJSExportProtocol @property (readonly) NSString *string; ... @interface OCClass : NSObject //JS var OCClass = new OCClass(); console.log(OCClass.string);
3. App 中的应用场景 基于 WebView 的通信,主要用于 App 向 H5 页面中注入的 JavaScript Open Api,如提供 Native 的拍照、音视频、定位,以及 App 内的登录与分享等功能。 JavascriptCore,则催生了动态化、跨平台以及热修复等一系列技术的蓬勃发展。
跨平台与热修复
近几年来国内外移动端各种跨平台方案如雨后春笋般涌现,“Write once, run anywhere”不再是空话。这些跨平台技术方案的切入点是在 Web 侧 DSL、virtualDom 等方面的优化,以及 Native 侧 Runtime 的应用与封装,但两端通信的核心,依然是 JavascriptCore。
除了对跨平台技术的积极探索,国内开发者对热修复技术也产生了极大的热情,同样作为 Native 和 Web 的交叉点,JavascriptCore 依然承担着整个技术结构中的通信任务。
1. 基于 Web 的热修复技术
对于国内的 iOS 开发者来说,审核周期、敏感业务、支付分成以及 bug 修复都催生了热修复方向的不断探索。在苹果加强审核之前,几乎所有大型的 App 都把热修复当成了 iOS 开发的基础能力,最近在《移动开发还有救么》一文中也详细地介绍了相关黑科技的前世今生。在所有 iOS 热修复的方案中,基于 JavaScript、同时也是影响最大的就是 JSPatch。
基于上文的分析,对于脱离 WebView 的 Native 和 Web 间的通信,我们只能使用 JavascriptCore。而在 JavascriptCore 中提供了两种方式用于通信,即 Context 注册 Block 的回调,以及 JSExport。对于热修复的场景来说,我们不可能把潜在需要修复的函数都一一使用协议进行注册,更不能对新增方法和删除方法等进行处理,所以在 Native 和 Web 通信这个维度,我们只能采用 Context 注册 Block 的方式。 // 注册回调 context[@"_OC_callI"] = ^id(JSValue *obj, NSString *selectorName, JSValue *arguments, BOOL isSuper) { return callSelector(nil, selectorName, arguments, obj, isSuper); }; context[@"_OC_callC"] = ^id(NSString *className, NSString *selectorName, JSValue *arguments) { return callSelector(className, selectorName, arguments, nil, NO); };
确定了通信采用 Block 回调的方式后,热修复就面临着如何在 JS 中调用类以及类的方法的问题。由于没有使用 JSExport 等方式,JS 是无法找到相应类等属性和方法的,在 JSPatch 中,通过简单的字符串替换,将所有方法都替换成通用函数 (__c),然后就可以将相关信息传递给 Native,进而使用 runtime 接口调用方法。 // 替换全部方法调用 static NSString *_replaceStr = @".__c(\"$1\")("; // 调用方法 __c: function(methodName) { ... return function(){ ... var ret = instance ? _OC_callI(instance, selectorName, args, isSuper): _OC_callC(clsName, selectorName, args) return _formatOCToJS(ret) }
当然对于 JSPatch 以及其它热修复的项目来说,Web 和 Native 通信只是整个框架中的一个技术点,更多的实现原理和细节由于篇幅的关系暂且不作介绍。
2. 基于 Web 的跨平台技术
随着 Google 开源了基于 Dart 语言的 Flutter,跨平台的技术又进入了一个新的发展阶段。对于传统的跨平台技术来讲,各个公司以 JavascriptCore 作为通信桥梁,围绕着 DSL 的解析、方法表的注册、模块注册通信、参数传递的设计以及 OC Runtime 的运用等不同方向,封装成了一个又一个跨平台的项目。
而在其中,以 JavaScript 作为前端 DSL 的跨平台技术方案里,Facebook 的 react-native 以及阿里(目前托管给了 Apache 软件基金会)的 Weex 最为流行。在网络上两者的比较文章有很多,集中在学习成本、框架生态、代码侵入、性能以及包大小等方面,各个业务可以根据自己的重点选择合理的技术结构。
而不管是 react-native 还是 Weex,Web 和 Native 的通信桥梁仍然是 JavascriptCore。 //weex 举例 JSValue* (^callNativeBlock)(JSValue *, JSValue *, JSValue *) = ^JSValue*(JSValue *instance, JSValue *tasks, JSValue *callback){ ... return [JSValue valueWithInt32:(int32_t)callNative(instanceId, tasksArray, callbackId) inContext:[JSContext currentContext]]; }; _jsContext[@"callNative"] = callNativeBlock;
和热修复技术一样,跨平台又是一个庞大的技术体系,JavascriptCore 仅仅是作为整个体系运转中的一个小小的部分,而整个跨平台的技术方案就需要另开多个篇幅进行介绍了。
iOS 中 Web 相关优化策略
随着 Web 技术的不断升级以及 App 动态性业务需求的增多,越来越多的 Web 页面加入到了 iOS App 当中,与之对应的,首屏展示速度体验这个至关重要的领域,也成为了移动客户端中 Web 业务最重要的优化方向。
1. 不同业务场景的优化策略
对于单纯的 Web 页面来说,业界早已有了合理的优化方向以及成熟的优化方案,而对于移动客户端中的 Web 来说,开发者在进行单一的 Web 优化时,还可以通过优化 Web 容器以及 Web 页面中数据加载方式等多个途径做出优化。
所以对于 iOS 开发中的优化来说,就是通过 Native 和 Web 两个维度的优化关键渲染路径,保证 WebView 优先渲染完毕。由此我们梳理了常规 Web 页面整体的加载顺序,从中找出关键渲染路径,继而逐个分析、优化。
2. Web 维度的优化
通用 Web 优化
对于 Web 的通用优化方案,一般来说在网络层面,可以通过 DNS 和 CDN 技术减少网络延迟、通过各种 HTTP 缓存技术减少网络请求次数、通过资源压缩和合并减少请求内容等。在渲染层面可以通过精简和优化业务代码、按需加载、防止阻塞、调整加载顺序优化等等。对于这个老生常谈的问题,业内已经有十分成熟和完整的总结,比如可以参考《Best Practices for Speeding Up Your Web Site》。
其它
脱离较为通用的优化,在对代码侵入宽容度较高的场景中,开发者对 Web 优化有着更为激进的做法。例如在 VasSonic 中,除了 Web 容器复用、数据模板分离、预拉取和通用的优化方式外,还通过自定义 VasSonic 标签将 HTML 页面进行划分,分段进行缓存控制,以达到更高的优化效果。
3. Native 维度的优化
容器复用和预热
WKWebView 虽然 JIT 大幅优化了 JS 的执行速度,但是单纯的加载渲染 HTML,WKWebView 比 UIWebView 慢了很多。根据渲染的不同阶段分别对耗时进行测试,同时对比 UIWebView,我们发现 WKWebView 在初始化及渲染开始前的耗时较多。
针对这种情况,业界主流的做法就是复用 & 预热。预热就是在 App 启动时创建一个 WKWebView,使其内部部分逻辑预热以提升加载速度。而复用又分为两种,较为复杂的是处理边界条件以达到真正的复用,还有一种较为取巧的办法就是常驻一个空 WKWebView 在内存。
HybridPageKit 提供了易于集成的完整 WKWebView 重用机制实现,开发者可以无需关注复用细节,无缝地体验更为高效的 WKWebView。
Native 并行资源请求 & 离线包
由于 Web 页面内请求流程不可控以及网络环境的影响,对于 Web 的加载来说,网络请求一直是优化的重点。开发者较为常用的做法是使用 Native 并行代理数据请求,替代 Web 内核的资源加载。在客户端初始化页面的同时,并行开始网络请求数据;当 Web 页面渲染时向 Native 获取其代理请求的数据。
而将并行加载和预加载做到极致的优化,就是离线包的使用。将常用的需要下载资源(HTML 模板、JS 文件、CSS 文件与占位图片)打包,App 选择合适的时机全部下载到本地,当 Web 页面渲染时向 Native 获取其数据。
通过离线包的使用,Web 页面可以并行(提前)加载页面资源,同时摆脱了网络的影响,提高了页面的加载速度和成功率。当然离线包作为资源动态更新的一个方式,合理的下载时机、增量更新、加密和校验等方面都是需要进行设计和思考的方向,后文会简单介绍。
复杂 Dom 节点 Native 化实现
当并行请求资源,客户端代理数据请求的技术方案逐渐成熟时,由于 WKWebView 的限制,开发者不得不面对业务调整和适配。其中保留原有代理逻辑、采用 LocalServer 的方式最为普遍。但是由于 WKWebView 的进程间通信、LocalServer Socket 建立与连接、资源的重复编解码都影响了代理请求的效率。
所以对于一些资讯类 App,通常采用 Dom 节点占位、Native 渲染实现的方式进行优化,如图片、地图、音视频等模块。这样不但能减少通信和请求的建立、提供更加友好的交互、也能并行地进行 View 的渲染和处理,同时减少 Web 页面的业务逻辑。
HybridPageKit 中就提供封装好的功能框架,开发者可以简单的替换 Dom 节点为 NativeView。
按优先级划分业务逻辑
从 App 的维度上看,一个 Web 页面从入口点击到渲染完成,或多或少都会有 Native 的业务逻辑并行执行。所以这个角度的优化关键渲染路径,就是优先保证 WebView 以及其它在首屏直接展示的 Native 模块优先渲染,所以承载 Web 页面的 Native 容器,可以根据业务逻辑的优先级,在保证 WebView 模块展示之后,选择合适的时机进行数据加载、视图渲染等。这样就能保证在 Native 的维度上,关键路径优先渲染。
4. 优化整体流程
整体上对于客户端来说,我们可以从 Native 维度(容器和数据加载)以及 Web 维度两个方向提升加载速度,按照页面的加载流程,整体的优化方向如下:
iOS 中 Web 相关延伸业务
1. 模板引擎
为了并行加载数据以及并行处理复杂的展示逻辑,对于非直出类型的 Web 页面,绝大部分 App 都采用数据和模板分离下发的方式。而这样的技术架构,导致在客户端内需要增加替换对应 DSL 的模板标签,形成最终的 HTML 业务逻辑。简单的字符串替换逻辑不但低效,还无法做到合理的组件化管理,以及组件合理地与 Native 交互,而模板引擎相关技术会使这种逻辑和表现分离的业务场景实现得更加简洁和优雅。
基于模板引擎与数据分离,客户端可以根据数据并行创建子业务模块,同时在子业务模块中处理和 Native 交互的部分,如图片裁剪适配、点击跳转等,生成 HTML 代码片段,之后基于模板进行替换生成完整的页面。这样不但减少了大量的字符串替换逻辑,同时业务也得到了合理拆分。
模板引擎的本质就是字符串的解析和替换拼接,在 Web 端不同的使用场景有很多不同语法的引擎类型,而在客户端较为流行的,有使用较为复杂的 MGTemplateEngine,它类似于 Smarty,支持部分模板逻辑。也有基于 mustache,Logic-less 的 GRMustache 可供选择。
2. 资源动态更新和管理
无论是离线包、本地注入的 JS、CSS 文件,还是本地化 Web 中的默认图片,目的都是通过提前下载,替换网络请求为本地读取来优化 Web 的加载体验和成功率,而对于这些资源的管理,开发者需要从下载与更新,以及 Web 中的访问这两个方面进行设计优化。
下载与更新 下载与重试:对于资源或是离线包的下载,选择合适的时机、失败重载时机、失败重载次数都要根据业务灵活调整。通常为了增加成功率和及时更新,在冷启动、前后台切换、关键的操作节点,或者采用定时轮循的方式,都需要进行资源版本号或 MD5 的判断,用以触发下载逻辑。当然对于服务端来说,合理的灰度控制,也是保证业务稳定的重要途径。 签名校验:对于动态下载的资源,我们都需要将原文件的签名进行校验,防止在传输过程中被篡改。对于单项加密的办法就是双端对数据进行 MD5 的加密,之后客户端校验 MD5 是否符合预期;而双向加密可以采用 DES 等加密算法,客户端使用公钥对资源验证使用。 增量更新:为了减少资源和离线包的重复下载,业内大部分使用离线包的场景都采用了增量更新的方式。即客户端在触发请求资源时,带上本地已存在资源的标示,服务端根据标示和最新资源做对比,之后只提供新增或修改的 Patch 供客户端下载。
基于 LocalServer 的访问
在完成资源的下载与更新后,如何将 Web 请求重定向到本地,大部分 App 都依赖于 NSURLProtocol。上文提到在 WKWebView 中虽然可以使用私有函数实现(或者 iOS11+ 提供的系统函数),但是仍然有许多问题。
目前业界一部分 App,都采用了集成 LocalServer 的方式,接管部分 Web 请求,从而达到访问本地资源的目的。同时集成了 LocalServer,通过将本地资源封装成 Response,利用 HTTP 的缓存技术,进一步的优化了读取的时间和性能,实现层次化的缓存结构。而使用了本地资源的 HTTP 缓存,就需要考虑缓存的控制和过期时间,通常可以通过在 URL 上增加本地文件的修改时间、或本地文件的 MD5 来确保缓存的有效性。
GCDWebServer 浅析
排除 Socket 类型,业界流行的 Objc 版针对 HTTP 开源的 WebServer,不外乎年久失修的 CocoaHTTPServer 以及 GCDWebServer。GCDWebServer 是一个基于 GCD 的轻量级服务器,拥有简单的四个模块:Server/Connection/Request/Reponse,它通过维护 LIFO 的 Handler 队列传入业务逻辑生成响应。在排除了基于 RFC 的 Request/Response 协议设计之后,关键的代码和流程如下: //GCDWebServer 端口绑定 bind(listeningSocket, address, length) listen(listeningSocket, (int)maxPendingConnections) //GCDWebServer 绑定Socket端口并接收数据源 dispatch_source_t source = dispatch_source_create(DISPATCH_SOURCE_TYPE_READ, listeningSocket, 0, dispatch_get_global_queue(_dispatchQueuePriority, 0)); //GCDWebServer 接收数据并创建Connection dispatch_source_set_event_handler(source, ^{ ... GCDWebServerConnection* connection = [(GCDWebServerConnection*)[self->_connectionClass alloc] initWithServer:self localAddress:localAddress remoteAddress:remoteAddress socket:socket]; //GCDWebServerConnection 读取数据 dispatch_read(_socket, length, dispatch_get_global_queue(_server.dispatchQueuePriority, 0), ^(dispatch_data_t buffer, int error) { //GCDWebServerConnection 处理GCDWebServerMatchBlock和GCDWebServerAsyncProcessBlock self->_request = self->_handler.matchBlock(requestMethod, requestURL, requestHeaders, requestPath, requestQuery); ... _handler.asyncProcessBlock(request, [completion copy]);
在 LocalServer 的使用上,也要注意端口的选择(ports used by Apple),以及前后台切换时 suspendInBackground 的设置和业务处理。
3. JavaScript Open Api
随着 App 业务的不断发展,单纯的 Web 加载与渲染无法满足复杂的交互逻辑,如拍照、音视频、蓝牙、定位等,同时 App 内也需要统一的登录态、统一的分享逻辑以及支付逻辑等,所以针对第三方的 Web 页面,Native 需要注册相应的 JavaScript 接口供 Web 使用。
对于 Api 需要提供的能力、接口设计和文档规范,不同的业务逻辑和团队代码风格会有不同的定义,微信 JS-SDK 说明文档就是一个很好的例子。而脱离 JavaScript Open Api 对外的接口设计和封装,在内部的实现上也有一些通用的关键因素,这里简单列举几个:
注入方式和时机
对于 JavaScript 文件的注入,最简单的就是将 JS 文件打包到项目中,使用 WKWebView 提供的系统函数进行注入。这种方式无需网络加载,可以合理地选择注入时机,但是无法动态地进行修改和调整。而对于这部分业务需求需要经常调整的 App 来说,也可以把文件存储到 CDN,通过模板替换或者和 Web 合作者约定,在 Web 的 HTML 中通过 URL 的方式进行加载,这种方式虽然动态化程度较高,但是需要合作方的配合,同时对于 JS Api 也不能做到拆分地注入。
针对上面的两种方式的不足,一个较为合理的方式是 JavaScript 文件采用本地注入的方式,同时建立资源的动态更新系统(上文)。这样一方面支持了动态更新,同时也无需合作方的配合,对于不同的业务场景也可以拆分不同的 Api 进行注入,保证安全。
安全控制
JavaScript Open Api 设计实现的另一个重要方面,就是安全性的控制。由于完整的 Api 需要支持 Native 登录、Cookies 等较为敏感的信息获取,同时也支持一些对 UI 和体验影响较多的功能,如页面跳转、分享等,所以 App 需要一套权限分级的逻辑控制 Web 相关的接口调用,保证体验和安全。
常规的做法就是对 JavaScript Open Api 建立分级的管理,不同权限的 Web 页面只能调用各自权限内的接口。客户端通过 Domain 进行分级,同时支持动态拉取权限 Domain 白名单,灵活地配置 Web 页面的权限。在此基础上 App 内部也可以通过业务逻辑划分,在 Native 层面使用不同的容器加载页面,而容器根据业务逻辑的不同,注入不同的 JS 文件进行 Api 权限控制。
回顾一下,本文聚焦 iOS 开发和 Web 开发的交叉点,内容涉及到 iOS 开发中全部的 Web 知识,涵盖从基础使用到 WebKit、从 JSCore 到大前端、从 Web 优化到业务扩展等方面,希望通过这样简要的介绍,帮助开发者一窥 Hybrid 和大前端的构想,如果觉得本文对你有所帮助,欢迎点赞。
作者介绍
朱德权,个人 GitHub:https://github.com/dequan1331。
原文链接地址: https://developer.baidu.com/topic/show/290637 【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
##部署
解压安装包 tar xf etcd-v3.3.12-linux-amd64.tar.gz cd etcd-v3.3.12-linux-amd64 mv etcd* /usr/bin/ chmod +x /usr/bin/etcd*
运行Etcd etcd --name 'etcd' --data-dir '/var/lib/etcd/default.etcd' \ --listen-client-urls "http://10.0.102.211:2379,http://127.0.0.1:2379" \ --advertise-client-urls http://10.0.102.211:2379,http://127.0.0.1:2379& 【见图1】
检查状态 etcdctl --endpoints http://10.0.102.169:2379 cluster-health 【见图2】 etcdctl --endpoints http://10.0.102.169:2379 mk /coreos.com/network/config '{ "Network" : "10.88.0.0/16" , "SubnetLen" : 24 , "SubnetMin" : "10.88.1.0" , "SubnetMax" : "10.88.50.0" , "Backend" : { "Type" : "vxlan" }}' 【见图3】 检查 etcdctl --endpoints http://10.0.102.169:2379 ls /coreos.com/network/config etcdctl --endpoints http://10.0.102.169:2379 get /coreos.com/network/config 【见图4】 【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
作者 | 声东 阿里云售后技术专家
导读 :不知道大家有没有意识到一个现实:大部分时候,我们已经不像以前一样,通过命令行,或者可视窗口来使用一个系统了。
前言
现在我们上微博、或者网购,操作的其实不是眼前这台设备,而是一个又一个集群。通常,这样的集群拥有成百上千个节点,每个节点是一台物理机或虚拟机。集群一般远离用户,坐落在数据中心。为了让这些节点互相协作,对外提供一致且高效的服务,集群需要操作系统。Kubernetes 就是这样的操作系统。
比较 Kubernetes 和单机操作系统,Kubernetes 相当于内核,它负责集群软硬件资源管理,并对外提供统一的入口,用户可以通过这个入口来使用集群,和集群沟通。
而运行在集群之上的程序,与普通程序有很大的不同。这样的程序,是“关在笼子里”的程序。它们从被制作,到被部署,再到被使用,都不寻常。我们只有深挖根源,才能理解其本质。
“关在笼子里”的程序
代码
我们使用 go 语言写了一个简单的 web 服务器程序 app.go,这个程序监听在 2580 这个端口。通过 http 协议访问这个服务的根路径,服务会返回 "This is a small app for kubernetes..." 字符串。 package main import ( "github.com/gorilla/mux" "log" "net/http" ) func about(w http.ResponseWriter, r *http.Request) { w.Write([]byte("This is a small app for kubernetes...\n")) } func main() { r := mux.NewRouter() r.HandleFunc("/", about) log.Fatal(http.ListenAndServe("0.0.0.0:2580", r)) }
使用 go build 命令编译这个程序,产生 app 可执行文件。这是一个普通的可执行文件,它在操作系统里运行,会依赖系统里的库文件。 # ldd app linux-vdso.so.1 => (0x00007ffd1f7a3000) libpthread.so.0 => /lib64/libpthread.so.0 (0x00007f554fd4a000) libc.so.6 => /lib64/libc.so.6 (0x00007f554f97d000) /lib64/ld-linux-x86-64.so.2 (0x00007f554ff66000)
“笼子”
为了让这个程序不依赖于操作系统自身的库文件,我们需要制作容器镜像,即隔离的运行环境。Dockerfile 是制作容器镜像的“菜谱”。我们的菜谱就只有两个步骤,下载一个 centos 的基础镜像,把 app 这个可执行文件放到镜像中 /usr/local/bin 目录中去。 FROM centos ADD app /usr/local/bin
地址
制作好的镜像存再本地,我们需要把这个镜像上传到镜像仓库里去。这里的镜像仓库,相当于应用商店。我们使用阿里云的镜像仓库,上传之后镜像地址是: registry.cn-hangzhou.aliyuncs.com/kube-easy/app:latest
镜像地址可以拆分成四个部分:仓库地址/命名空间/镜像名称:镜像版本。显然,镜像上边的镜像,在阿里云杭州镜像仓库,使用的命名空间是 kube-easy,镜像名:版本是 app:latest。至此,我们有了一个可以在 Kubernetes 集群上运行的、“关在笼子里”的小程序。
得其门而入
入口
Kubernetes 作为操作系统,和普通的操作系统一样,有 API 的概念。有了 API,集群就有了入口;有了 API,我们使用集群,才能得其门而入。Kubernetes 的 API 被实现为运行在集群节点上的组件 API Server。这个组件是典型的 web 服务器程序,通过对外暴露 http(s) 接口来提供服务。
这里我们创建一个阿里云 Kubernetes 集群。登录集群管理页面,我们可以看到 API Server 的公网入口。 API Server 内网连接端点: https://xx.xxx.xxx.xxx:6443
双向数字证书验证
阿里云 Kubernetes 集群 API Server 组件,使用基于 CA 签名的双向数字证书认证来保证客户端与 api server 之间的安全通信。这句话很绕口,对于初学者不太好理解,我们来深入解释一下。
从概念上来讲,数字证书是用来验证网络通信参与者的一个文件。这和学校颁发给学生的毕业证书类似。在学校和学生之间,学校是可信第三方 CA,而学生是通信参与者。如果社会普遍信任一个学校的声誉的话,那么这个学校颁发的毕业证书,也会得到社会认可。参与者证书和 CA 证书可以类比毕业证和学校的办学许可证。
这里我们有两类参与者,CA 和普通参与者;与此对应,我们有两种证书,CA 证书和参与者证书;另外我们还有两种关系,证书签发关系以及信任关系。这两种关系至关重要。
我们先看签发关系。如下图,我们有两张 CA 证书,三个参与者证书。
其中最上边的 CA 证书,签发了两张证书,一张是中间的 CA 证书,另一张是右边的参与者证书;中间的 CA 证书,签发了下边两张参与者证书。这六张证书以签发关系为联系,形成了树状的证书签发关系图。
然而,证书以及签发关系本身,并不能保证可信的通信可以在参与者之间进行。以上图为例,假设最右边的参与者是一个网站,最左边的参与者是一个浏览器,浏览器相信网站的数据,不是因为网站有证书,也不是因为网站的证书是 CA 签发的,而是因为浏览器相信最上边的 CA,也就是信任关系。
理解了 CA(证书),参与者(证书),签发关系,以及信任关系之后,我们回过头来看“基于 CA 签名的双向数字证书认证”。客户端和 API Server 作为通信的普通参与者,各有一张证书。而这两张证书,都是由 CA 签发,我们简单称它们为集群 CA 和客户端 CA。客户端信任集群 CA,所以它信任拥有集群 CA 签发证书的 API Server;反过来 API Server 需要信任客户端 CA,它才愿意与客户端通信。
阿里云 Kubernetes 集群,集群 CA 证书,和客户端 CA 证书,实现上其实是一张证书,所以我们有这样的关系图。
KubeConfig 文件
登录集群管理控制台,我们可以拿到 KubeConfig 文件。这个文件包括了客户端证书,集群 CA 证书,以及其他。证书使用 base64 编码,所以我们可以使用 base64 工具解码证书,并使用 openssl 查看证书文本。 首先,客户端证书的签发者 CN 是集群 id c0256a3b8e4b948bb9c21e66b0e1d9a72,而证书本身的 CN 是子账号 252771643302762862; Certificate: Data: Version: 3 (0x2) Serial Number: 787224 (0xc0318) Signature Algorithm: sha256WithRSAEncryption Issuer: O=c0256a3b8e4b948bb9c21e66b0e1d9a72, OU=default, CN=c0256a3b8e4b948bb9c21e66b0e1d9a72 Validity Not Before: Nov 29 06:03:00 2018 GMT Not After : Nov 28 06:08:39 2021 GMT Subject: O=system:users, OU=, CN=252771643302762862 其次,只有在 API Server 信任客户端 CA 证书的情况下,上边的客户端证书才能通过 API Server 的验证。kube-apiserver 进程通过 client-ca-file 这个参数指定其信任的客户端 CA 证书,其指定的证书是 /etc/kubernetes/pki/apiserver-ca.crt。这个文件实际上包含了两张客户端 CA 证书,其中一张和集群管控有关系,这里不做解释,另外一张如下,它的 CN 与客户端证书的签发者 CN 一致; Certificate: Data: Version: 3 (0x2) Serial Number: 787224 (0xc0318) Signature Algorithm: sha256WithRSAEncryption Issuer: O=c0256a3b8e4b948bb9c21e66b0e1d9a72, OU=default, CN=c0256a3b8e4b948bb9c21e66b0e1d9a72 Validity Not Before: Nov 29 06:03:00 2018 GMT Not After : Nov 28 06:08:39 2021 GMT Subject: O=system:users, OU=, CN=252771643302762862 再次,API Server 使用的证书,由 kube-apiserver 的参数 tls-cert-file 决定,这个参数指向证书 /etc/kubernetes/pki/apiserver.crt。这个证书的 CN 是 kube-apiserver,签发者是 c0256a3b8e4b948bb9c21e66b0e1d9a72,即集群 CA 证书; Certificate: Data: Version: 3 (0x2) Serial Number: 2184578451551960857 (0x1e512e86fcba3f19) Signature Algorithm: sha256WithRSAEncryption Issuer: O=c0256a3b8e4b948bb9c21e66b0e1d9a72, OU=default, CN=c0256a3b8e4b948bb9c21e66b0e1d9a72 Validity Not Before: Nov 29 03:59:00 2018 GMT Not After : Nov 29 04:14:23 2019 GMT Subject: CN=kube-apiserver 最后,客户端需要验证上边这张 API Server 的证书,因而 KubeConfig 文件里包含了其签发者,即集群 CA 证书。对比集群 CA 证书和客户端 CA 证书,发现两张证书完全一样,这符合我们的预期。 Certificate: Data: Version: 3 (0x2) Serial Number: 786974 (0xc021e) Signature Algorithm: sha256WithRSAEncryption Issuer: C=CN, ST=ZheJiang, L=HangZhou, O=Alibaba, OU=ACS, CN=root Validity Not Before: Nov 29 03:59:00 2018 GMT Not After : Nov 24 04:04:00 2038 GMT Subject: O=c0256a3b8e4b948bb9c21e66b0e1d9a72, OU=default, CN=c0256a3b8e4b948bb9c21e66b0e1d9a72
访问
理解了原理之后,我们可以做一个简单的测试:以证书作为参数,使用 curl 访问 api server,并得到预期结果。 # curl --cert ./client.crt --cacert ./ca.crt --key ./client.key https://xx.xx.xx.xxx:6443/api/ { "kind": "APIVersions", "versions": [ "v1" ], "serverAddressByClientCIDRs": [ { "clientCIDR": "0.0.0.0/0", "serverAddress": "192.168.0.222:6443" } ] }
择优而居
两种节点,一种任务
如开始所讲,Kubernetes 是管理集群多个节点的操作系统。这些节点在集群中的角色,却不必完全一样。Kubernetes 集群有两种节点:master 节点和 worker 节点。
这种角色的区分,实际上就是一种分工:master 负责整个集群的管理,其上运行的以集群管理组件为主,这些组件包括实现集群入口的 api server;而 worker 节点主要负责承载普通任务。
在 Kubernetes 集群中,任务被定义为 pod 这个概念。pod 是集群可承载任务的原子单元,pod 被翻译成容器组,其实是意译,因为一个 pod 实际上封装了多个容器化的应用。原则上来讲,被封装在一个 pod 里边的容器,应该是存在相当程度的耦合关系。
择优而居
调度算法需要解决的问题,是替 pod 选择一个舒适的“居所”,让 pod 所定义的任务可以在这个节点上顺利地完成。
为了实现“择优而居”的目标,Kubernetes 集群调度算法采用了两步走的策略: 第一步,从所有节点中排除不满足条件的节点,即预选; 第二步,给剩余的节点打分,最后得分高者胜出,即优选。
下面我们使用文章开始的时候制作的镜像,创建一个 pod,并通过日志来具体分析一下,这个 pod 怎么样被调度到某一个集群节点。
Pod 配置
首先,我们创建 pod 的配置文件,配置文件格式是 json。这个配置文件有三个地方比较关键,分别是镜像地址,命令以及容器的端口。 { "apiVersion": "v1", "kind": "Pod", "metadata": { "name": "app" }, "spec": { "containers": [ { "name": "app", "image": "registry.cn-hangzhou.aliyuncs.com/kube-easy/app:latest", "command": [ "app" ], "ports": [ { "containerPort": 2580 } ] } ] } }
日志级别
集群调度算法被实现为运行在 master 节点上的系统组件,这一点和 api server 类似。其对应的进程名是 kube-scheduler。kube-scheduler 支持多个级别的日志输出,但社区并没有提供详细的日志级别说明文档。查看调度算法对节点进行筛选、打分的过程,我们需要把日志级别提高到 10,即加入参数 --v=10。 kube-scheduler --address=127.0.0.1 --kubeconfig=/etc/kubernetes/scheduler.conf --leader-elect=true --v=10
创建 Pod
使用 curl,以证书和 pod 配置文件等作为参数,通过 POST 请求访问 api server 的接口,我们可以在集群里创建对应的 pod。 # curl -X POST -H 'Content-Type: application/json;charset=utf-8' --cert ./client.crt --cacert ./ca.crt --key ./client.key https://47.110.197.238:6443/api/v1/namespaces/default/pods -d@app.json
预选
预选是 Kubernetes 调度的第一步,这一步要做的事情,是根据预先定义的规则,把不符合条件的节点过滤掉。不同版本的 Kubernetes 所实现的预选规则有很大的不同,但基本的趋势,是预选规则会越来越丰富。
比较常见的两个预选规则是 PodFitsResourcesPred 和 PodFitsHostPortsPred。前一个规则用来判断,一个节点上的剩余资源,是不是能够满足 pod 的需求;而后一个规则,检查一个节点上某一个端口是不是已经被其他 pod 所使用了。
下图是调度算法在处理测试 pod 的时候,输出的预选规则的日志。这段日志记录了预选规则 CheckVolumeBindingPred 的执行情况。某些类型的存储卷(PV),只能挂载到一个节点上,这个规则可以过滤掉不满足 pod 对 PV 需求的节点。
从 app 的编排文件里可以看到,pod 对存储卷并没有什么需求,所以这个条件并没有过滤掉节点。
优选
调度算法的第二个阶段是优选阶段。这个阶段,kube-scheduler 会根据节点可用资源及其他一些规则,给剩余节点打分。
目前,CPU 和内存是调度算法考量的两种主要资源,但考量的方式并不是简单的,剩余 CPU、内存资源越多,得分就越高。
日志记录了两种计算方式:LeastResourceAllocation 和 BalancedResourceAllocation。 前一种方式计算 pod 调度到节点之后,节点剩余 CPU 和内存占总 CPU 和内存的比例,比例越高得分就越高; 第二种方式计算节点上 CPU 和内存使用比例之差的绝对值,绝对值越大,得分越少。
这两种方式,一种倾向于选出资源使用率较低的节点,第二种希望选出两种资源使用比例接近的节点。这两种方式有一些矛盾,最终依靠一定的权重来平衡这两个因素。
除了资源之外,优选算法会考虑其他一些因素,比如 pod 与节点的亲和性,或者如果一个服务有多个相同 pod 组成的情况下,多个 pod 在不同节点上的分散程度,这是保证高可用的一种策略。
得分
最后,调度算法会给所有的得分项乘以它们的权重,然后求和得到每个节点最终的得分。因为测试集群使用的是默认调度算法,而默认调度算法把日志中出现的得分项所对应的权重,都设置成了 1,所以如果按日志里有记录得分项来计算,最终三个节点的得分应该是 29,28 和 29。
之所以会出现日志输出的得分和我们自己计算的得分不符的情况,是因为日志并没有输出所有的得分项,猜测漏掉的策略应该是 NodePreferAvoidPodsPriority,这个策略的权重是 10000,每个节点得分 10,所以才得出最终日志输出的结果。
结束语
在本文中,我们以一个简单的容器化 web 程序为例,着重分析了客户端怎么样通过 Kubernetes 集群 API Server 认证,以及容器应用怎么样被分派到合适节点这两件事情。
在分析过程中,我们弃用了一些便利的工具,比如 kubectl,或者控制台。我们用了一些更接近底层的小实验,比如拆解 KubeConfig 文件,再比如分析调度器日志来分析认证和调度算法的运作原理。希望这些对大家进一步理解 Kubernetes 集群有所帮助。
架构师成长系列直播
“ 阿里巴巴云原生 关注微服务、Serverless、容器、Service Mesh 等技术领域、聚焦云原生流行技术趋势、云原生大规模的落地实践,做最懂云原生开发者的技术圈。” 【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
作者 | Rafal
导读 :Helm 是 Kubernetes 的一个软件包管理器。两个月前,它发布了第三个主要版本,Helm 3。在这一新版本中,有许多重大变化。本文作者将介绍自己认为最关键的 5 个方面。
移除了 Tiller
Helm 最终移除了其服务器端组件,Tiller。现在,它完全没有代理。Tiller 之前是一个运行在 Kubernetes 上的小型应用程序,它用于监听 Helm 命令并处理设置 Kubernetes 资源的实际工作。
这是 Helm3 中最重大的更改。为什么 Tiller 的移除备受关注呢?首先,Helm 应该是一种在 Kubernetes 配置上的模板机制。那么,为什么需要在服务器上运行某些代理呢?
Tiller 本身也存在一些问题,因为它需要集群管理员的 ClusterRole 才能创建。因此,假设你要在 Google Cloud Platform 中启动的 Kubernetes 集群上运行 Helm 应用程序。首先,你需要启动一个新的 GKE 集群,然后使用 helm init 初始化 Helm,然后…发现它失败了。
这种情况之所以会发生是因为,在默认状态下,你没有给你的 kubectl 上下文分配管理员权限。现在你了解到了这一点,开始搜索为分配管理员权限的 magic 命令。这一系列操作下来,也许你已经开始怀疑 Helm 是否真的是一个不错的选择。
此外,由于 Tiller 使用的访问权限与你在 kubectl 上下文中配置的访问权限不同。因此,你也许可以使用 Helm 创建应用程序,但你可能无法使用 kubectl 创建该程序。这一情况如果没排查出来,看起来感觉像是安全漏洞。
幸运的是,现在 Tiller 已经被完全移除,Helm 现在是一个客户端工具。这一更改会导致以下结果: Helm 使用与 kubectl 上下文相同的访问权限; 你无需再使用 helm init 来初始化 Helm; Release Name 位于命名空间中。
Helm 3 一直保持不变的是:它应该只是一个在 Kubernetes API 上执行操作的工具。如此,如果你可以使用纯粹的 kubectl 命令执行某项操作,那么也可以使用 helm 执行该操作。
分布式仓库以及 Helm Hub
Helm 命令可以从远程仓库安装 Chart。在 Helm 3 之前,它通常使用预定义的中心仓库,但你也能够添加其他仓库。但是从现在开始,Helm 将其仓库模型从集中式迁移到分布式。这意味着两个重要的改变: 预定义的中心仓库被移除; Helm Hub(一个发现分布式 chart 仓库的平台)被添加到 helm search。
为了能够更好地理解这一改变,我给你们一个示例。在 Helm 3 之前,如果你想要安装一个 Hazelcast 集群,你需要执行以下命令: $ helm2 install --name my-release stable/hazelcast
现在,这个命令不起作用了。你需要先添加远程仓库才能进行安装。这是因为这里不再存在一个预定义中心仓库。要安装 Hazelcast 集群,你首先需要添加其仓库然后安装 chart: $ helm3 repo add hazelcast https://hazelcast.github.io/charts/ $ helm3 repo update $ helm3 install my-release hazelcast/hazelcast
好消息是现在 Helm 命令可以直接在 Helm Hub 中寻找 Chart。例如,如果你想知道在哪个仓库中可以找到 Hazelcast,你只需执行以下命令即可: $ helm3 search hub hazelcast
以上命令列出在 Helm Hub 中所有分布式仓库中名称中包含 “hazelcast” 的 Chart。
现在,我来问你一个问题。移除掉中心仓库是进步还是退步?这有两种观点。第一种是 chart 维护者的观点。例如,我们维护 Hazelcast Helm Chart,而 Chart 中的每个更改都需要我们将其传播到中心仓库中。这项额外的工作使得中心仓库中的许多 Helm Chart 没有得到很好地维护。这一情况与我们在 Ubuntu/Debian 包仓库中所经历的很相似。你可以使用默认仓库,但它常常只有旧的软件包版本。
第二种观点来自 Chart 的使用者。对于他们来说,虽然现在安装一个 chart 比之前稍微困难了一些,但另一方面,他们能够从主要的仓库中安装到最新的 chart。
JSON Schema 验证
从 Helm 3 开始,chart 维护者可以为输入值定义 JSON Schema。这一功能的完善十分重要,因为迄今为止你可以在 values.yaml 中放入任何你所需的内容,但是安装的最终结果可能不正确或出现一些难以理解的错误消息。 例如,你在 port 参数中输入字符串而不是数字。那么你会收到以下错误: $ helm2 install --name my-release --set service.port=string-name hazelcast/hazelcast Error: release my-release failed: Service in version "v1" cannot be handled as a Service: v1.Service.Spec: v1.ServiceSpec.Ports: []v1.ServicePort: v1.ServicePort.Port: readUint32: unexpected character: �, error found in #10 byte of ...|","port":"wrong-name|..., bigger context ...|fault"},"spec":{"ports":[{"name":"hzport","port":"wrong-name","protocol": "TCP","targetPort":"hazelca|...
你不得不承认这个问题难以分析和理解。
此外,Helm 3 默认添加了针对 Kubernetes 对象的 OpenAPI 验证,这意味着发送到 Kubernetes API 的请求将会被检查是否正确。这对于 Chart 维护者来说,是一项重大利好。
Helm 测试
Helm 测试是一个小小的优化。尽管微小,但它也许实际上鼓励了维护者来写 Helm 测试以及用户在安装完每个 chart 之后执行 helm test 命令。在 Helm 3 之前,进行测试多少都显得有些奇怪: 此前测试作为 Pod 执行(好像需要一直运行);现在你可以将其定义为 Job;
测试 Pod 不会自动被移除(除非你使用 magic flag –cleanup),所以默认状态下,没有任何技巧,对于既定的版本你不能多次执行 helm test。但幸运的是,现在可以自动删除测试资源(Pod、Job)。
当然旧的测试版本也并非不能使用,只需要使用 Pod 并始终记得执行 helm test –cleanup。但也不得不承认,这一改进有助于提升测试体验。
命令行语法
最后一点是,Helm 命令语法有所改变。从积极的一面来看,我认为所有的改变都是为了让体验更好;从消极的方面看,这一语法不与之前的版本兼容。因此,现在编写有关如何使用 Helm 安装东西的步骤时,需要明确指出所使用的命令是用于 Helm 2 还是用于 Helm 3。
举个例子,从 helm install 开始说起。现在版本名称已经成为必填参数,尽管在 Helm 2 中你可以忽略它,名称也能够自动生成。如果在 Helm3 中要达成相同的效果,你需要添加参数 --generate-name。所以,使用 Helm 2 进行标准的安装应该如下: $ helm2 install --name my-release --set service.port=string- $ helm2 install --name my-release hazelcast/hazelcast
在 Helm 3 中,需要执行以下命令: $ helm3 install my-release hazelcast/hazelcast
还有另一个比较好的改变是,删除 Helm 版本后,无需添加— purge。简单地输入命令 helm uninstall 即可删除所有相关的资源。
还有一些其他改变,如一些命令被重命名(不过使用旧的名称作为别名),有一些命令则被删除(如 helm init)。如果你还想了解更多关于 Helm 命令语法更改的信息,请参考官方文档: https://helm.sh/docs/faq/#cli-command-renames
结 论
Helm 3 的发布,使得这一工具迈向一个新的阶段。作为用户,我十分喜欢 Helm 现在只是一个单纯的客户端工具。作为 Chart 维护者,Helm Hub 以及分布式仓库的方法深得我心。我希望能在未来看到更多更有意思的改变。
如果你想了解 Helm 3 中的所有变化,请查看官方文档: https://helm.sh/docs/faq/#changes-since-helm-2
本文转载自:RancherLabs, 点击查看原文 。 “ 阿里巴巴云原生 关注微服务、Serverless、容器、Service Mesh 等技术领域、聚焦云原生流行技术趋势、云原生大规模的落地实践,做最懂云原生开发者的技术圈。” 【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
Serverless 是炙手可热的技术,被认为是云计算发展的未来方向。尤其是在前端研发领域,使用 Node 开发云函数,可以让前端工程师更加专注于业务逻辑,实现全栈工程师的角色转变。
Serverless 的优势
技术 Leader 和架构师在进行技术选型时会关注很多指标, Serverless 贡献最大的就是 研发交付速度(Time to Market) 和 成本(Cost) 。
研发交付速度方面,衡量的指标是 Time to Market,是从需求产出到上线所用的总时长,Serverless 在这方面的优势在技术和团队协作两个视角上均有体现。
一是技术视角。 有一种观点称 Serverless 是一种很简单的技术,我对这种观点并不完全同意。Serverless 架构让用户和底层架构的关系发生了变化,之前开发者需要关注核心业务逻辑、运维和底层架构的治理,在 Serverless 架构中底层的部分由 Serverless 架构提供方来解决。从整个应用系统的角度来看,系统架构的难度和复杂度并没有实质简化。
这里我们不展开讲 Serverless 架构的底层实现细节。 只需要了解一点:Serverless 底层架构做的事情越多,业务层面需要关注的架构和运维工作就越少,因为做的工作少了,所以交付的时间就更快了。
**二是团队协作视角。在 Serverless 的模式下,全栈开发的工作模式会执行得更加顺畅。**我们知道,前后端分离确实是一种很好的架构模式:细化了分工,降低了耦合,提升了复用。但随之而来的问题,是团队间的沟通成本、KPI 目标的差异所带来的各种催排期、接口确认以及联调测试。不少技术团队用全栈开发的模式来解决这些问题, Serverless 下不需要在架构和技术栈花费过多精力,Runtime 和语言也没有强制依赖,而是完全面向业务,每个前端工程师都可以是全栈的。
另一个优势就是 Serverless 会大大降低成本,体现在计算资源和人力两个层面。
在计算资源的成本方面,主要体现在弹性扩缩容量,按需付费。在传统的计算资源预算时,往往为了能抗住峰值流量,系统容量都有 Buffer,说白了就是日常的浪费。
在 Serverless 模式下,当业务代码上线后,一分钱都不需要支付。只有当真实请求和流量过来了,平台才会根据请求量,瞬时拉起对应数量的函数实例,去接收请求和执行业务代码,此时才需要为真正的代码执行所消耗的资源付费。**No Pay for Idle ,从会计学的角度,Serverless 让计算资源从固定成本变成了可变成本。**这种付费模式对于那种流量波动很大的业务优势明显。
还要说明的是人力成本。很多技术 Leader 总抱怨人手不够,也许真实情况并非如此,只是没有足够比例的人投入到业务功能的开发和迭代上,而是去做了架构、底层等必要的支撑性工作。我承认这些工作确实非常有挑战、非常必要,也非常重要。在 Serverless 模式下,由于不再需要关注底层架构,所以缩小这部分的工作量和人力占比,就有了更多的工程师可以放在核心业务上,多做迭代,从而加速产品功能的研发。这不是更高的 ROI 吗?
Serverless 的适用场景
Serverless 适用于事件触发的场景。当某个事件发生时,拉起并调用 Serverless 云函数,比如文件上传、消息队列中的消息事件、定时器事件,也可以是 IoT 设备的某个事件。还可以用于一些文件处理,比如图像处理、音视频处理和日志分析等场景。
当然,这些事件也包括 HTTP 请求事件,这是 Serverless 的一个很大的适用场景—— HTTP Service,主要实现基于 HTTP 应用的后端服务,比如 REST API、BFF 和 SSR 服务,以及业务逻辑的实现。
我主要关注 Serverless 在 HTTP 场景下的应用。这也是和前端工程师结合最紧密的部分。小到为小游戏、运营活动提供后端的支持,大到整个 App 或站点的 REST API、BFF,或是 H5 页面的 SSR,都是 Serverless 适用的场景。
Serverless 对前端开发者的意义
Serverless 的诸多优势业内有很多讨论,也有不少文章谈及。我想聚焦到前端开发者身上来说一说,**Serverless 能够帮助前端工程师实现真全栈的梦想。**可能有人会质疑,为什么你又提出一个真全栈,和之前的全栈有什么区别吗?
我先明确一下真全栈的定义:如何判断一个工程师是真全栈工程师?
当公司有了一堆产品功能需求,招了一个程序员张全占,如果他能从 0 到 1 把需求做成产品,那才叫真全栈。如果张全占完成了前端功能开发、后端开发以及数据库开发,实现了所有的需求功能,并且部署到对应的服务上,就完事了,那么问题也就来了:服务挂了谁来重启?环境稳定性谁来做?日志把磁盘写满了谁来清理?定时任务怎么搞?产品突然火爆了,流量一夜间突然扩大了十几倍的时候(产品经理狂喜中),谁负责扩容?这些问题虽然不是核心业务需求,却是每一个线上产品都必须考虑的东西,否则只能称为功能集合,不能称之为产品。
Serverless 架构的出现,将刚才说到的一些非核心业务逻辑,以及运维相关的事情给“屏蔽”了。前端工程师张全占只需关注前台功能、后台功能和数据这些核心的业务逻辑,就可以独立做出产品。例如目前的微信小程序云开发就是 Serverless 式的,开发者完全不用关注底层架构。
Serverless 对前端工程师群体来说是一个机会。让一个前端工程师能够得到独立负责某些产品研发的机会,完成某些产品从需求到上线的从 0 到 1 的机会,一个回归到互联网研发工程师角色的机会。 我希望所有的前端工程师都有机会成为 Serverless 工程师,有机会独立负责研发整个产品。
采用 Serverless 的准备
总体上来说,采用 Serverless 不需要工程师大量的学习和准备过程。
Serverless 本身就是在现有的架构中做减法,减去那些服务器的管理和配置工作。当然在具体落地的时候,还是有一些准备工作要做:
首先是明确目标,开发者在了解 Serverless 之后,应该去思考对于自身业务和开发架构,采用 Serverless 是为了解决什么问题?想取得哪方面的提升?没有一种技术是为了用而用,都是针对具体场景解决具体问题。这是第一个需要搞明白的。
明确了目标之后,接着是 Serverless 模式下架构的一些设计工作。与传统的开发模式一样,系统设计的工作量是根据业务的复杂程度决定的。对于复杂业务逻辑来说,在开发之前需要明确有多少个云函数,每个云函数的输入输出定义、采用哪些 BaaS 后端服务,都需要提前设计规划好。
特别要说明的是,这些设计和非 Serverless 并没有什么本质上的不同,Serverless 云函数也不是神秘莫测的。简单理解,它所提供的就是一个语言的 Runtime。在非 Serverless 架构下如何执行的代码,Serverless 架构下还是那样执行。如果业务是基于 Express 或者 koa 这类应用框架,那么 Serverless 云函数下,还是直接使用这些框架即可。
最后是一些实施上的准备,以腾讯云函数为例,只要是写过代码的,花小半天时间阅读一些基础文档、教程,或者是跟着 Demo 走一遍,就可以立刻开始写代码,几乎没有什么门槛和不同。要敲黑板强调的是,别忘记了工程化和 CI/CD 方面的考虑,尤其是和现有研发流程的结合。这块有一些小小的工作量,毕竟是开发模式的升级,但基于云函数提供的 CLI 和 SDK 都很容易实现。
Serverless 和云函数的关系
Serverless 架构由两部分构成,分别是 FaaS(Functions as a Service)和 BasS(Backend as a Sevice)。其中 FaaS 就是指云函数,它是一种新的算力组织和提供方式,它让用户不再需要关心服务器的管理和配置,只用专注于核心业务逻辑业务代码的编写。BaaS 指的是一些服务化的后端功能,包括数据库 / 对象存储、账户权鉴、消息队列、社交媒体整合和 AI 能力等,这些服务和接口在 FaaS 层使用相应的 SDK 或 API 来连接和调用。
FaaS+BaaS 的组合,构成了 Serverless 无服务器架构,免除了所有运维性操作,让企业和开发者可以更加专注于核心业务的开发,实现快速上线和迭代,把握业务发展的节奏。
由此可见,云函数是 Severless 架构中的算力部分,是实现 Severless 架构的基础计算资源。在 Severless 架构下的业务系统中,因业务功能、需求场景不同,所需的 BaaS 后端服务也可能各不相同,但业务逻辑都需要通过云函数来实现。
具体案例
刚才也提到 Serverless 本身有很多很多的应用场景,这个问题在不同的 Serverless 的场景下,答案也是不同的。
如果业务需求是基于类似于 Express、koa 的应用框架来实现的,那么在设计上,基本没有任何区别。Serverless 云函数可以很好地支持这些应用框架,只是部署方式不同而已。
如果需求场景不需要任何应用框架,直接使用原生代码,在 Serverless 架构下进行设计时,需要以函数为粒度来考虑,将函数作为业务中的最小功能单元。
还有一个场景使用 Serverless 和不使用就有很大的不同——企业上云。
现在很多企业应用都做应用上云,上云其实是一件非常有技术门槛的事情。可能需要上云的代码只有几百行,但传统上云绝不是上传部署几百行代码那么简单(估计很多工程师看到 Kubernetes 那几本厚书的时候就已经快疯了)。这个过程需要专业的、有经验的工程师,花费大量的工作,才能把业务系统迁移到云上。
Serverless 下的体验就非常不同,因为无服务器架构,所以不需要关注虚机或者容器配置和治理工作,基本上只用上传代码就完成了上云。
Serverless 的未来演化
从以往的历史来看,技术的演化还是存在一些一般规律的。
首先我预测 Serverless 生态一定会趋于繁荣。一个技术很有优势,相关的社区贡献,以及周边的支持就越强大,用的人就越多;用的人越多,这个技术就越火,类似于经济学里的有效市场理论。最近 Serverless 的发展很快,可能大家看到这篇内容的时候,我们的 Serverless DB 产品已经发布了,就是开发者连数据库的存在都不需要关注了。Serverless 的使用者会越来越多,同时生态里的贡献者也会更多,整个生态也会更加繁荣。
第二个方向是 Serverless 的标准化。当生态繁荣之后,对于标准化的需求就变得非常强烈了。国内外各家云都有了自己的 Serverless 解决方案,对开发者隐藏了底层基础设置。但是各家的接口、实现还是不一样。试想一下,开发者在国内云上用 Serverless 实现的代码,在做国际化的时候,要迁移到另一个云厂商,却发现完全无法平滑迁移是什么感受?公司内两个技术团队如何在 Serverless 的架构下复用功能和代码?如何能够用统一的标准或者框架来构建应用?Serverless 开发需要一些标准,或是某一种框架来适配各个云厂商之间的不同实现和接口,很可能是 Serverless 接下来的发展方向。
Serverless Framework 30 天试用计划
我们诚邀您来体验最便捷的 Serverless 开发和部署方式。在试用期内,相关联的产品及服务均提供免费资源和专业的技术支持,帮助您的业务快速、便捷地实现 Serverless! 详情可查阅: Serverless Framework 试用计划
One More Thing
3 秒你能做什么?喝一口水,看一封邮件,还是 —— 部署一个完整的 Serverless 应用? 复制链接至 PC 浏览器访问: https://serverless.cloud.tencent.com/deploy/express
3 秒极速部署,立即体验史上最快的 Serverless HTTP 实战开发! 传送门: GitHub: github.com/serverless 官网: serverless.com
欢迎访问: Serverless 中文网 ,您可以在 最佳实践 里体验更多关于 Serverless 应用的开发! 推荐阅读: 《Serverless 架构:从原理、设计到项目实战》 【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>> 课程目录: 01、课程介绍 02、背景说明 03、课程目标和主要内容 04、课程案例需求 05、课程补充说明 06、为何采用微服务架构? 07、架构设计和技术栈选型 08、数据和接口模型设计:账户服务 09、数据和接口模型设计:业务服务 10、Dubbo、SpringCloud和Kubernetes该如何选型(上) 11、Dubbo、SpringCloud和Kubernetes该如何选型(中) 12、Dubbo、SpringCloud和Kubernetes该如何选型(下) 13、技术中台到底讲什么? 14、Staffjoy项目结构组织 15、谷歌为何采用单体仓库(Mono、Repo)? 16、微服务接口参数校验为何重要? 17、如何实现统一异常处理? 18、DTO和DMO为什么要互转? 19、如何实现基于Feign的强类型接口? 20、为什么框架层就要考虑分环境配置? 21、异步处理为何要复制线程上下文信息? 22、为你的接口添加Swagger文档 23、主流微服务框架概览 24、网关和BFF是如何演化出来的(上) 25、网关和BFF是如何演化出来的(下) 26、网关和反向代理是什么关系? 27、网关需要分集群部署吗? 28、如何设计一个最简网关? 29、Faraday网关代码解析(上) 30、Faraday网关代码解析(下) 31、生产级网关需要考虑哪些环节? 32、主流开源网关概览 33、安全认证架构演进:单块阶段(上) 34、安全认证架构演进:单块阶段(下) 35、安全认证架构演进:微服务阶段 36、基于JWT令牌的安全认证架构 37、JWT的原理是什么? 38、JWT有哪两种主要流程? 39、Staffjoy安全认证架构和SSO 40、用户认证代码剖析 41、服务调用鉴权代码剖析 42、如何设计用户角色鉴权? 43、SpringBoot微服务测试该如何分类? 44、什么是契约驱动测试? 45、什么是测试金字塔? 46、单元测试案例分析 47、集成测试案例分析 48、组件测试案例分析 49、Mock、vs、Spy 50、何谓生产就绪(Production、Ready)? 51、SpringBoot如何实现分环境配置 52、Apollo、vs、SpringCloud、Config、vs、K8s、ConfigMap 53、CAT、vs、Zipkin、vs、Skywalking(上) 54、CAT、vs、Zipkin、vs、Skywalking(下) 55、结构化日志和业务审计日志 56、集中异常监控和Sentry 57、EFK&Prometheus&Skywalking+K8s集成架构 58、本地开发部署架构和软件需求 59、手工服务部署和测试(上) 60、手工服务部署和测试(中) 61、手工服务部署和测试(下) 62、SkyWalking调用链监控实验 63、Docker和DockerCompose简介 64、容器镜像构建Dockerfile解析 65、DockerCompose服务部署文件剖析 66、将Staffjoy部署到本地DockerCompose环境(上) 67、将Staffjoy部署到本地DockerCompose环境(下) 68、到底什么是云原生架构 68、到底什么是云原生架构? 69、Kubernetes背景和架构 70、Kubernetes有哪些基本概念?(上)
下载地址: Spring Boot与Kubernetes云原生微服务实践 【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
docker本身提供有 attach 、 exec 等方法进入容器中,本身却没有支持远程管理容器的方法。本文介绍为centos基础镜像添加SSH支持
手动构建 docker pull centos:7 :下载一个contos镜像
docker run -it --name ssh_cenots7 docker.io/centos:7 bash :运行并进入centos7容器
yum install openssh-server :下载并安装 penssh-server
ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key;ssh-keygen -t ecdsa -f /etc/ssh/ssh_host_ecdsa_key;ssh-keygen -t ed25519 -f /etc/ssh/ssh_host_ed25519_key :配置密钥文件
vi /etc/pam.d/sshd :注销 pam_loginuid.so ,关闭pam登陆限制
passwd root :设置修改root密码或者添加账户
创建run.sh文件,并添加运行权限, chmod +x run.sh #!/bin/bash /usr/sbin/sshd -D docker commit ssh_cenots7 sshd:centos7 :将容器制作为镜像
docker run -p 2222:22 -d sshd:centos7 /run.sh :运行sshd镜像,之后可以使用ip地址连接2222端口ssh进入docker容器
使用dockerfile构建 FROM centos:7 #作者信息 MAINTAINER shuangmu RUN yum install -y openssh-server RUN ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key;ssh-keygen -t ecdsa -f /etc/ssh/ssh_host_ecdsa_key;ssh-keygen -t ed25519 -f /etc/ssh/ssh_host_ed25519_key #取消pam登陆限制 RUN sed -ri 's/session required pam_loginuid.so/#session required pam_loginuid.so/g' /etc/pam.d/sshd #修改root密码 RUN echo "root:root" | chpasswd COPY run.sh /run.sh RUN chmod 755 /run.sh #开放端口 EXPOSE 22 CMD ["/run.sh"]
使用 docker build -t ssh:centos_dockerfile . 进行构建 【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
今年的这个春节假期,对于所有中国人来说,都是一次非常难忘的记忆。受冠状病毒肺炎疫情的影响,各个企业的复工也面临着诸多挑战。在假期延长之后,在线办公的形式成为各个企业的共同选择。
在SaaS应用逐渐普及的当下,随着信息技术、5G、人工智能的高速发展和迅速普及,我们正在进入一个“云时代”。SaaS模式的云应用对于当下这个时间节点的中国企业来说,无疑不正是一个良好的选择。
目前,优秀的SaaS服务是在线订阅的基础上提供服务,免去了企业购买传统本地部署软件或者构建自己的本地部署软件的成本,轻松解决远程协同中的“沟通、流程、跨地域”这3大难题 。所有员工通过互联网、电脑、手机即可登录使用,同时它还允许客户根据自身需要扩大和缩减其支出、按需定制。
JEPaaS云平台,中国领先的企业数字化中台和SaaS快速开发领导者,是集低代码快速开发、实干型数字中台工具、SaaS快速开发运营管理、万物互联的物联网接口引擎这四大核心承载力的新一代企业级快速开发平台。JEPaaS的SaaS+PaaS平台,能提供字段级别的功能自定义,并且使用的通用编程语言,让众多开发者可以在不用学习新型编程语言的情况下,就可以在线进行二次开发。
JEPa aS平台功能架构
JEPaaS让更多的各行各业的企业成为其平台的客户,从而开发出基于他们平台的多种SaaS应用,而技术人员也不用再面对诸多的系统服务提供商难以抉择的困境。实现再统一云平台即可简单开发实现包括CRM、OA、HR、SCM、进销存管理等任何企业管理软件,而且不需要使用其他软件开发工具并立即在线运行。
JEPaaS专为SaaS而生
JEPaaS丰富的SaaS应用
JEPaaS的SaaS商城界面
JEPaaS的SaaS运营监控
肺炎疫情带来的影响正冲击着各行各业。一边是疫情防控战仍在持续,一边是大小企业陆续开启“云办公”模式。在这个全国“战疫”的特殊时期,各类数字化服务正发挥出更大的作用。JEPaaS云平台所打造的SaaS生态体系,正通过自身以及合作伙伴推出各类服务和解决方案,助力各地抗击疫情,也帮助企业恢复经营。 【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
这几天,全国中小学生经历了“过山车”一样的心情。 因为疫情的不断蔓延,1月27日,教育部下发通知,2020年春季学期延期开学。 随后,教育部又提出“利用网络平台,停课不停学”。 紧接着,阿里巴巴旗下的钉钉发起了“在家上课”计划,将“在线课堂”功能免费开放给全国大中小学使用,并覆盖广大农村地区的学校。同时,钉钉的群直播“连麦功能”也将免费开放。 这意味着,只需要通过电脑或者手机打开钉钉,老师便可以在家上课,同学们也可以在家听课。不仅如此,还可以通过“连麦”像课堂上一样互动,目前全国已经有上万所学校加入。 一天点了70万个赞 “真没想到,初六那天学生给我们点了70万个赞。”说这话的是金乡二中的英语老师陈方园。 大年初六,山东省金乡一中和金乡二中“网上开课”第一天,两校高三学生都通过钉钉直播上课。 每课90分钟,每天四节课,总计六小时的时间里,2600多名同学点赞70万次,平均每人点赞269次。 点赞之外,同学们还时不时地发出赞美:“上课效果真的很好”,“有一对一辅导的感觉”。 因为钉钉上的直播视频可以回放,同学们在二次学习后,还会和老师进行交流。 同一天晚上八点,浙江宁波的镇海仁爱中学也有两堂课在钉钉上同步进行。一堂是25分钟的英语课,讲解了“过去完成时”;一堂是10分钟的科学课,讲解了寒假作业中的难题。 通过手机钉钉直播讲课的老师 在这短短的时间里,120位学生点了15000次赞,不停为上课的老师“打call”。 “网络不仅没有减少课程效果,反而因为新奇和有趣,提升了同学们的参与度。很多人都‘连麦’回答了问题或者‘连麦’提问,整体的气氛很好。”负责智慧校园建设的教师王雪建说。 一拍即合的“在线课堂” 尽管钉钉直播课初六才开始,但各方的准备工作却早已进行。 新春之后,山东省金乡县两所高中的校领导们就已经对不断加重的疫情产生了担忧。他们商量着将“钉钉直播上课”作为备案。恰在此时,金乡县教育局下发“网络直播开课”的通知。 早在一年前,金乡县的130所学校、120家幼儿园和300多家培训机构就已经使用钉钉。但那时,钉钉更多用于“家校联系”、“一键传达”。如今,钉钉“在线课堂”免费开放解了燃眉之急。 大年初三,金乡二中的英语老师陈方园接到了“初六上课”的紧急通知。次日,她和其他几位老师“网络备课”一整天,完成学案,一来交给教育局打印发放,二来上传钉钉供学生自取。 几乎同一时间,浙江镇海的王雪建也接到了校长的电话,要求着手进行网上课堂建设的准备。 早在2019年9月,镇海仁爱学校就已经开始使用钉钉,王雪建正是这方面的负责人——钉钉提供教学平台,教育局、学校多方提前准备,这才有了同学们的“如期上课”。 500万学生在线上课 如果说初六是部分地区的学校尝试“网络上课”,是星星之火,那么现在钉钉的“在线课堂”已经燎原。 1月31日,山西省太原市第五中学、第十二中学迎来开年第一课,通过钉钉直播在家听课。 同日,浙江温州、海宁、丽水等城市的40余所学校也已经使用钉钉APP展开网络教学或在线通知等功能。 镇海中学高三任课老师王燕告诉记者,老师们正在紧急备课,以期尽快开展网络教学。 据了解,目前浙江、江苏、河南、山西、山东、湖北等20多个省份纷纷加入阿里巴巴钉钉“在家上课”计划,预计超过1万所大中小学、超过500万学生将通过钉钉直播的方式上课。 不少父母也会通过钉钉回看课程,了解孩子们的学习状态。一位山东家长告诉记者,自己平常也会辅导孩子,现在就和他一起在钉钉上学习,希望后面四个月的高考冲刺,可以更好地帮助他。 我们不知道疫情还会持续多久,但教育一定会持续进行,并且会最先迎来繁花盛开的春天。 上云就看云栖号,点此 查看更多 ! 本文为阿里云原创内容,未经允许不得转载。 【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
本文作者:oschina_2020
我们的中国文化,对“面子”看得特别重,所以你会发现身边到处都是高级 XXX,听着倍儿有面子,程序员也不例外。
但是你真要问每个人,你认为的高级 XXX 是什么样子的,估计每个人都有不同的回答。
我还记得在我刚开始从事编程工作的时候,对坐在边上不远的那位我心目中的高级程序员的印象是: 工作至少有 6、7 年以上,能写一个用起来很方便、看起来很牛逼、但是不太容易让初级人员看懂的框架。
前两天,我把这个问题丢到群里,大家给出的答案中,占比最高的是以下几个。 有 N 年以上编程经验(大部分都说 5 年以上) 有出版过技术图书 对某领域内对常用框架原理有了解,并且实际使用超过 2 年 可以随时随地快速写出常见的一些算法 至少封装过一个被全局使用的开发框架 写出来的代码,阅读起来很好理解 能带领其他人员成功完成项目
你看,这件事对大家来说就是常说的,“一千个人眼中有一千个哈姆雷特”。
不过这也正常,毕竟像初级、中级、高级这种高度抽象的词汇,想要得到一个可描述的定义与人交流,必然需要夹杂着个人的主观因素。
但是很多行业都在这么进行分类,自然有它的道理和好处。
我觉得 其中最大的一个好处恰好是“主观”的附属品——弹性 。
比如,我现在想招一位高级程序员,面试的时候不管是通过还是不通过,我都有理由来解释我对“高级”的定义。如此一来,我对陌生人的判断就有了更大的“弹性”。
这其实是面试官的一种权利,也是长期以来面试者总在面试中处于下峰的原因之一。
事物总是有两面性的,我们在对陌生人弹性的同时,间接地也对内部的人弹性了,会导致内部的一些人才培养出现问题。
比如,你觉得内部的高级程序员不够,希望能在外部招聘的同时,从内部也培养一些出来。但是此时,你又面临了需要定义什么是“高级”的问题。
如果没法定义一个能够达成共识的标准,又如何指导培养的方向呢?只能是一句空话。
长此以往会导致更严重的问题: 真正的高级程序员不够,只能让中级程序员顶上。顶替的时间长了,会让一些中级程序员误以为自己已经达到了高级水平 。
在我平时的面试中,这样的案例屡见不鲜,网上流传的工作 10 年 = 1 年重复 10 次的段子是真实存在的。
下面我来聊聊我对“什么是高级程序员”的个人看法,欢迎你和我一起探讨。
不管是什么行业,什么岗位,在这个高度分工协作的现代社会,所需的能力主要分为三个维度,我的理解大概是这样的: 专业能力:好奇心、敢于挑战困难、刻意养成好习惯、要求严格 连接能力:共同体意识、同理心、实事求是、接地气 领导能力:主人翁意识、沟通/谈判技巧、目的导向
先卖个关子,文章的最后我会将这三个维度组合起来,你会发现一片新的天地。
根据这三个维度的水平差异,我们对初级程序员、中级程序员、高级程序员做一个简要的描述。
初级程序员 - 知道有事要做
处在初级阶段的时候,我们的精力大多只会专注在专业能力的提升上。这个时候“领导能力”和“连接能力”是很弱的。
所以,这个时候哪怕你有强烈的好奇心也无法很好地表达出来,大多只能被动的接受工作安排。
在这个时期做事情需要依赖一些教程、文档,只能“依样画葫芦”,几乎不能在不借助外部信息的情况下解决之前从未遇到过的新问题,所以百度、Google 就成了他们唯一的选择。
你可以在你的身边观察一下,如果经常有以下这些场景出现,大多是初级程序员的表现。 很难提出正确的问题,大多会直接问别人这个功能应该怎么做。如果你清楚地向他解释,他就会完全按你说的去做,甚至你写的示例代码都会 copy 过去。因为在他们的世界里,只有编译成功和编译失败,任务完成和任务未完成。 经常犯错误,所以会预留过多“弹性时间”,以便有时间在到期日之前重做。所以总会抱怨“没时间”。 对与自己有工作交集的人员的职能没有认识。比如,对测试人员总是充满敌意的,因为他们发现了错误,“阻碍”了自己完成工作。 还没注意养成一些好习惯,比如习惯性地提炼重复代码、编写风格一致的代码、自测等等。
很遗憾,看似很初级的阶段,并不只是刚踏入工作的程序员所属,在实际工作中,也有不少工作多年的人还处在这个阶段。
中级程序员 - 知道如何做某事
对人群按照单一维度进行划分,大多数时候都是符合正态分布的,这里也不例外。中级程序员是我们身边最多的,包括那些不得不穿上高级程序员马甲的中级程序员。
在这个阶段,有些中级程序员开始具备了一定的“连接能力”,但并不是所有人,主要看是不是拥有了“共同体意识”。
在专业能力上,中级程序员已经明白了一定的“整体与局部”的概念,但仍然看不到整个“森林”,大多局限在某个模块、流程上。比如,他们会想“这是做敏捷的正确方式吗?”,但不会考虑“这对整个团队、整个公司会产生什么实际的影响?”。
他们开始注重代码质量,因为担心低质量的代码会影响他们视野中的“整体”。
但是对于质量的理解还是比较单一。比如,这个时候你会经常听到他们把“性能”挂在嘴边,在他们心目中“性能”的地位是至高无上的,总是想着你这个方案和我的方案哪个性能更好。
同样可以观察一下周围,中级的开发大多数会这样做事: 针对一个问题,可以提出多个方案,但是无法做出准确的决策。一旦更权威的人给出了他的选择,中级程序员就会不假思索地按照建议执行。 可以看出代码中的一些设计模式,但是自己写代码的时候除了单例和工厂,其它的几乎想不到。 在讨论一些时髦的框架和技术的时候总能聊上几句,但是追问这个框架或者技术有什么缺点,基本说不上来。甚至,草率地在项目中运用上这些时髦的框架和技术,最终导致线上问题频发,不得不让高级程序员来收拾残局。 能够对自己完成任务所需的时间有准确的评估,但是评估他人的时间不会因人而异,也会以自己作为标准来评估。 对与自己有工作交集的人员的职能有了一定的认识。比如,会主动寻求测试的配合,帮助自己交付更高质量的项目。
其实这个阶段是最危险的阶段,因为最可怕的不是无知,而是一知半解 。心理学中的邓宁-克鲁格效应(The Dunning-Kruger Effect)讲述的就是这个问题。
两位社会心理学家在 1999 年做的 4 项研究,证实了下面的这个曲线的存在。
在这种状态下,人最容易高估自己,这也是很多导致产生很多“假高级程序员”的原因所在。
高级程序员 - 知道必须做些什么
高级程序员在“专业能力”、“连接能力”与“领导能力”这三个维度都有所建树。因为他们不但可以把从 1 到 100 的事情做得很好,也有能力带领其它人完成 0 到 1 的事情。
根据我身边所接触的程序员群体来看,我所认为的高级程序员,他们明白没有什么是完美的,相反,问题、缺点和风险总是存在的。
他们的决策总是站在为了整体的“平衡”角度去考虑,而不是技术的酷炫或者外界流传的所谓“正确的”技术。
他们会更多地关心那些不显而易见的东西,如可维护性、可扩展性、易阅读、易调试等等。
高级程序员就好比社会中的成年人,他们踩过足够多的坑,也填过足够多的坑,已经认清了现实的残酷,寻求适合而不是完美。周到、务实、简单,是他们做事的时候强烈散发出的“味道”。
可以根据下面的这些场景来看看你身边有多少“有味道”的高级程序员? 与初级和中级程序员不同,他们抛出问题不是为了正确地做事,而是做正确的事。他们会询问为什么要这样做以及你想要实现什么。当你告诉他们目标是什么后,他们或许会通过暗示这种方式是错误的而另一种更好来做出一些修正;当然,更重要的是还会提供论据说服你。 因为提前明确了做事的目标,所以在动手做一件事的过程中,他会在关键细节思考有没有更好的方法,甚至是那些不在之前的讨论范围的新尝试。 他可以轻松地承认他不知道什么,并且向你请教。同时也可以轻松地向他人讲清楚他所知道的事情。 他们理解合作的人员的职能的作用,不但知道什么时候向谁寻求帮助,还知道自己如何更好地帮助他们。 困难的事交给他们很放心,因为他们擅长的不是某种技术,而是解决问题的能力。他们总能解决那些之前从未遇到过的新问题,哪怕它们很困难。
那么,怎么做有助于我们成为高级程序员呢?
1、关注技术之余还要关注业务
为什么把它放第一点,因为我觉得这点最重要,是其它项的基础,也最容易做到,但是很多程序员不愿意去做。
一定要搞清楚业务目标,不搞清楚不开工。相信我,只要是一位合格的 leader,一定会不厌其烦地和你说清楚的。
然后要习惯基于业务目标去分析可能会面临的技术挑战。比如,多少流量,涉及哪些用户角色和功能,复杂度有多大等等。
再带着下面的“不可能三角”去寻找合适的技术框架、解决方案。尽可能地寻求最优的平衡,而不是走极端。
如果拿捏不准,可以将多个方案各自的优缺点罗列出来,向 leader 寻求建议。
2、“设计”代码而不是“写”代码
一般人可能拿到需求,就开始写代码了,写着写着由于页面功能越来越多,感觉代码越来越复杂,自己都会觉得难以维护了。
虽说要做好设计离不开大量的实战经验的积累,但还是有些方法可以让塑造这个能力的过程更快一些。比如: 首先就是前面提到的第一点,多关注业务。不了解业务,你啥都设计不出来,或者把马设计成了驴…… 如果某个功能的开发/修改,以“天”为工时单位,一定要先画图。具体画什么图,可以参考我之前写的文章: 软件开发中会用到的图 。 搞明白每个设计模式的特点和适用场景,注意,不需要把代码怎么写背下来。只要你每次写代码之前扫一眼设计模式的列表,看看有没有适用的。如果有的话,再去“依样画葫芦”按照设计模式去实现,经过时间的积累,慢慢地,你真正掌握的设计模式就越来越多了。这有助于锻炼你的设计能力。
3、“接”需求之前会先“砍”需求
要做这点还得依赖于第一点,否则,你提出的“砍”需求建议大多是不会被采纳的。
很多人在听需求讲解的时候,思考的是,这个功能能不能实现、怎么实现、难不难。大多数的提问也是基于这个思路展开的。
可能也会提出“砍”需求的问题,但是理由大多是这个实现起来太麻烦了,这个没法实现之类。
其实只要你时刻保持着“做这个需求的目的是什么”这个问题去思考,“砍”需求会变成一件更容易成功,而且自然而然的事情。
4、解决一类问题而不是一个问题
很多人觉得,每天看到 bug 清完就万事大吉了,哪怕同一个问题在生产环境出现多次,最多也就说一句“不会吧,怎么又出问题了”。
这种对待问题的方式只会让你越来越忙,因为你的解决问题效率与投入的时间多少是成同比变化的。
我们要习惯于解决掉一个 bug 之后,想一下能否通过什么方式找到现有代码中的同类问题,并把它们处理掉。
甚至是考虑有没有什么办法能够一劳永逸地避免此类问题再次发生,比如封装一个 SDK 或者写一个组件,尽可能用一种低侵入的通用方式将问题扼杀在摇篮里。不但让自己轻松了,也造福了大家。
5、遵循 KISS 原则,写尽可能简单的代码
KISS 原则:保持简单,愚蠢(Keep it simple, stupid)。
不单单是程序员,任何化繁为简的能力才是一个人功力深厚的体现,没有之一 。
越简单,越接近本质。就好比,有的人要用长篇大论才能讲明白一件事,而有的人只要做一个形象的比喻你就懂了。
这个“简单”指的是整体的简单,而不是通过局部的复杂让另一个局部简单。比如,为了上层的使用更加傻瓜化,底层封装的代码错综复杂、晦涩难懂,这并不是真正的“简单”。
如果你自认为已经是一个中级或者高级程序员了,那么你回头去看看自己还是初级程序员那会写的代码,就会很容易发现一些显得冗余的代码。
第二点提到的——“设计代码而不是写代码”对做好这点有很大的帮助。
6、选择忍受某些问题
在人工智能还不能代替我们 coding 之前,我们永远要亲自面对无穷无尽的、这样那样的问题。
然而,任何事物都有两面性的,一个方案在解决一个老问题的同时,总会带来新的问题。所以,我们一定要意识到,忍受某些问题是必然的。
那些你现在看起来很傻逼的设计,可能就是当时的人做出的妥协。
所以,既然如此,你更应该考虑的是,当前的这个问题现在到底有没有必要解决?值不值得,为什么之前没去解决?它是不是你当前所有待解决问题列表中优先级最高的?
7、打造自己的“T型”专业技能
可能很多人都听过“T型人才”的概念,我们程序员在专业技能的打造上也适合用这种模型。
但是对于“先竖再横”还是“先横再竖”可能不同的人有不同的看法。
我的观点是, 大多数情况下,先竖再横。特别是某个技术、领域发展得越成熟,越应该如此 。
因为很多事物的本质是一样的,所以对某一个领域达到非常深入,洞察到一些本质的东西之后,对其它相邻的领域有触类旁通的效果。可以加速自己在“广度”上的扩展。
不过,“广度”也不是说蜻蜓点水,只知道最表象的“它是什么”。我认为比较合适的程度是,可以不用清楚某个技术具体的使用方式,但得知道它可以解决哪些问题,以及使用成本和潜在的风险,我将这些信息概括为 “它怎么样” 。
8、构建自驱动的“闭环”
很多人都知道闭环的概念,但是它的重要性和价值往往被低估。因为人总是短视的,“聚沙成塔”之类的方式总是不受待见。
常规的搭建一个闭环的过程大多是这样的。
这里所说的自驱动的“闭环”是这样的。
如何才能变成这样呢? 只要做一件事,尽可能多地对外输出自己的知识 。
举个我自己的例子,我在 2015 年那会在项目中开始引入领域驱动设计,并且不断地在内部进行分享它的好处,慢慢地越来越多的项目开始往这个方向走。
因为前期的不断分享,所以在组织内部,别人对我的人设多了一个“DDD专家”的标签,那么大家遇到有关 DDD 的问题就会来和我一起探讨。
越到后面,我已经不用自己主动去寻找这个领域的知识去学习了,因为接收到的外部反馈已经足够多了,它们能够倒逼我往前走。并且这些反馈都是实际的真实场景,此时的信息获取和学习自然能达到“学以致用”的效果。
说实话,有不少人并不是这么想的,他们想的恰恰相反:“为什么每个人都在问我问题!你自己去学习吧!”。
所以,当你遇到其他人来请教你的时候,如果恰巧这是你所关注的领域,那么应该去拥抱这个问题而不是排斥它。 因为你是团队里最权威的人,这是你构建自驱动“闭环”的好机会 。错过这一回,下一回不知道得等多久。
前面文章里说到,我会将“专业技能”、“连接外部的能力”、“领导力”三个维度组合起来给你看。就是下面这个样子。
你会发现这里面包含了程序员在进阶后的几个常见岗位。
可以对号入座一下:D
好了,我们总结一下。
这篇我先和你聊了一下在大家眼中高级程序员是什么样子,发现没有特别统一的标准,都是模糊的。这也体现在了几个现实的场景中,比如招聘高级程序员、培养高级程序员上。
其次,我对初级、中级、高级程序员的特点分别阐述了自己的观点。
然后,给出了一些帮助大家往高级程序员靠拢的实践思路。
希望对你有所启发。
最后,用Martin Fowler 的一句话作为结尾:“任何傻瓜都能写计算机能理解的代码,优秀的程序员编写人类能够理解的代码。” Any fool can write code that a computer can understand. Good programmers write code that humans can understand
Martin Fowler
希望看到这篇文章的每个程序员最终都能成为头发茂盛的码农:D
作者介绍
张帆(Zachary),7 年电商行业经验,5 年开发团队管理经验,4 年互联网架构经验,目前任职某垂直电商技术总监。专注大型系统架构与分布式系统,坚持用心打磨每一篇原创。个人公众号:跨界架构师(ID:Zachary_ZF)。
原文链接地址: https://developer.baidu.com/topic/show/290543 【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
随着以函数即服务(Function as a Service)为代表的无服务器计算(Serverless)的广泛使用,很多用户遇到了涉及多个函数的场景,需要组合多个函数来共同完成一个业务目标,这正是微服务“分而治之,合而用之”的精髓所在。本文以阿里云 函数计算 为例,试图全面介绍函数组合的常见模式和使用场景,希望有助于选择合适的解决方案。
虽然本文主要介绍的是函数组合,但是基本思想也可用于服务组合。
函数同步调用函数
在这种模式里,函数直接调用 InvokeFunction 同步 API 执行一个或者多个函数,等待被调用函数返回结果,然后继续执行。这是一个有些争议的模式,不使用同步调用通常有以下原因: 从费用的角度:由于函数计算按照函数实际执行时间收费,调用者在等待被调用函数返回前也会产生一定费用。 执行时长限制:由于函数最长执行10分钟,这就决定了调用的其它函数执行时间之和有限。 从容错的角度:被调用者出错会直接影响调用者,如果这个调用链很长,则这种错误会一直蔓延到最初的调用者,容错性较差。同时由于执行时长限制,调用者通常不容易针对错误做长时间重试。
上面的理由是在有些场景下成立的,但是微服务最经典最常见的组合方式就是同步调用,函数作为微服务的一种实现方式,这种同步调用的需求是不可回避的,在有些场景下采用同步调用模式是值得考虑的,这些场景包括: 调用者函数需要被调用函数执行结果做后续处理或者返回给客户端。 函数执行时间较短,最好在毫秒到秒级别。 调用者是无状态的,不需要针对被调用者的错误做复杂重试。
在这种模式里,调用者通常不需要做复杂的计算,主要时间花在调用函数和等待返回上,因此调用者函数可以设置较小的内存,以减少费用;调用者还可以根据业务需求缓存调用结果,减少对其它函数的调用,从而节约费用和增强容错性。
函数通过 API 网关调用函数
与函数直接调用函数不同,这里 被调用函数在 API 网关后面 ,使它看起来更像一个微服务。这种模式的限制和使用场景跟上面的直接调用模式类似,不同之处是 API 网关提供了一些额外的能力,比如认证和限流等。如果被调用者要根据某些业务信息对请求做处理,则使用 API 网关是一个好的选择。当然,使用 API 网关也带来了额外的延迟和费用,如果不需要使用 API 网关提供的能力,则让函数直接调用函数是一个更好的选择。
函数异步调用函数
在这种模式里,函数执行完自身业务逻辑后,调用 InvokeFunction 异步 API 通知其它函数执行并退出,它不关心被调用函数是否执行完成。函数计算的 InvokeFunction 异步 API 是通过队列实现的,异步请求首先被写入队列,然后有一个组件从队列里消费请求,执行相应函数。这种模式的优势和使用场景有: 对执行延迟不敏感的场景,适合削峰填谷,减轻对依赖服务的压力。函数计算会根据用户的资源使用情况动态的调整队列的处理速度,平滑请求对系统的压力,当然这种平滑也可能会导致一些请求被延缓执行。 调用者可以较容易的触发多个被调用者执行,实现 Fan-Out 模式。比如一个视频处理函数可以异步调用多个函数来分别将视频转换成不同格式。 由于每个函数所花时间都用在执行业务逻辑,而非等待其它函数返回上,没有产生不必要的费用。
这种模式有如下局限性: 调用者显然无法知道被调用者的执行结果。 被调用者之间最好是独立执行的,不需要相互协调,否则通过数据库来协调执行会增加复杂度。例如,上面提到的视频处理函数调用多个函数分别将视频转换成不同格式,如果需要在所有的视频转换完成后发邮件通知用户,这就需要等待所有的转换函数执行结束。这种 等待多个事件发生 的模式叫做 Fan-In,不适合通过这种异步调用模式实现。
基于消息主题的函数调用
与上面的模式需要指定被调用函数不同,基于事件触发模式让调用者只需要发布消息,不关心谁去消费消息。在消息服务(MNS)中,主题是发布消息的目的地,发布者可以通过 PublishMessage API 向主题发布消息, 主题的订阅者会接收到发布到主题上的消息, MNS 与函数计算服务的集成 让函数可以直接作为订阅者,简化了消息处理应用的开发和运维代价。
和上面的异步调用模式相比,基于消息主题的调用模式有以下优势: 进一步解耦函数调用。调用者无需知道被调用者的信息,只需要约定消息的格式。 得益于一个主题可以对应多个订阅者,更容易实现 Fan-Out 模式。发布者只需要发布一条消息就能触发多个函数。在上面的异步调用方式中,调用者仍需要显式调用一个或者多个函数来触发执行。 虽然主题模式本质上是消息服务 推送 消息给订阅者,不会考虑订阅者的承载能力,但是由于阿里云消息服务是通过 InvokeFunction 异步 API 调用函数,因此这种模式也具备基于消息队列模式的削峰填谷能力。
这种模式的局限性跟异步调用函数类似: 很难支持等待多个事件触发一个函数的场景(Fan-In)。 需要做一定工作才能跟踪多个函数执行状态。 很难限制单个函数的执行时间或者所有函数的总执行时间。 无法针对函数执行错误定义重试策略。
基于对象存储服务的函数调用
函数计算服务除了集成了消息主题以外,还集成了对象存储服务 (OSS),表格存储等其它事件源,这些事件源服务同样可以作为连接函数的渠道。比如,一个非函数应用对 OSS 对象操作(创建,删除等)后,通常需要其它渠道(比如消息服务)通知其它应用做后续处理,而由于 OSS 和函数计算的集成 ,只需简单配置,这些事件就可以直接传递给自定义函数,而不需要额外渠道再传递信息,简化了数据处理流水线的开发和运维代价。
基于日志库的函数调用
日志服务的 日志库 是一个流(Stream)存储,生产者写入数据到日志库,消费者读出数据并处理。 日志服务和函数计算的集成 ,使得消费者可以是函数,从而实现了通过流存储来协调函数调用。上面所有模式都是调用者显式或者隐式的触发一个或多个被调用函数执行,而这里生产者函数写入的数据不一定会立刻被消费者函数处理,日志服务会根据用户配置将多个数据批量推送给消费者函数。
这种模式有以下优势: 日志服务会针对每个分区(Shard)并行调用函数,如果数据吞吐较大,可以通过扩展分区来提高消费吞吐能力。 日志服务给函数推送的同一分区数据是串行的和严格保序的,在老的数据没有消费成功前不会推送新的数据。 日志服务会持续推送相同数据到函数直到函数消费数据后返回正常。
基于函数工作流的函数组合
函数工作流 (Function Flow,简称 FnF)是一个用来协调多个分布式任务执行的全托管 Serverless 云服务,简化了开发和运行业务流程所需要的任务协调、状态管理以及错误处理等繁琐工作,让用户更好的专注业务逻辑开发。可以说函数工作流是转为函数组合而生,有效的解决了上面几种异步组合模式的局限性。
上面的所有模式都是通过点对点的方式来组合函数,而函数工作流是一个集中的协调者,函数之前不再直接或者间接通信,所有的触发都是由函数工作流发起,不同函数的输入和输出是通过函数工作流来传递。因此,这种方式下的函数代码全是业务逻辑相关,没有上面模式里的发送主题消息,或者调用其它函数的逻辑,实现更加清晰。
函数工作流有以下优势: 服务编排能力:可以将流程逻辑与任务执行分开,支持多种控制原语,比如顺序执行多个函数,根据函数执行结果选择执行其它函数,让多个函数并行处理数据,或者让一个函数并行处理一组数据等,以及上面的 Fan-In 模式。函数工作流还内置了错误重试和捕获能力,节省了编写编排代码的时间。 支持长流程:无论是毫秒级还是长达一年的业务流程,FnF 都可以跟踪整个流程,确保流程执行完成。 流程状态管理:FnF 会管理流程执行中的所有状态,包括跟踪它所处的执行步骤,以及存储在步骤之间的输入输出。您无需自己管理流程状态,也不必将复杂的状态管理构建到任务中。 协调分布式组件:FnF 能够协调运行在不同架构,不同网络,不同语言实现的分布式应用。无论是私有云、专有云的应用想要平滑过渡到混合云、公共云,还是单体架构的应用想要演进到微服务架构,FnF 都能在其中发挥协调作用。函数工作流通过集成消息队列,让任何可以访问消息队列的应用也可以作为流程一部分,相互协作,共同完成业务目标。 可视化监控:FnF 提供了可视化界面来协助定义流程和查看执行状态,方便您快速识别故障位置,并快速排除故障问题。 运维全托管和按需付费:FnF 让您从基础设施维护中解放出来,提供了安全的、高可用的、高容错的弹性服务。用户只需支付步骤转换费用,不使用不产生费用。
函数工作流目前还不支持同步调用方式,如果您有同步调用需求,欢迎联系我们(见文章最后钉钉客户群)。
总结
总的来说,上面的组合模式可以分为同步和异步两种,在场景适合的情况下优先选择异步模式,享受异步模式带来的松耦合,高容错等特性,否则使用同步模式。在异步模式中,如果需要编写复杂的组合逻辑,支持可靠的重试,把控整个流程,则推荐使用函数工作流,否则使用消息主题或者其它事件源服务来组合函数。
上面的模式也不是割裂的,它们在有些场景下可以搭配使用,比如有时候基于对象存储服务的调用需要触发多个函数,这就可以 结合使用 OSS 的事件触发和函数工作流 ;又比如 函数工作流通过消息队列将任务发送给更广泛的消费者 ,触达函数计算无法触达的地方。
最后,欢迎加入函数工作流和函数计算客户群。
“ 阿里巴巴云原生 关注微服务、Serverless、容器、Service Mesh 等技术领域、聚焦云原生流行技术趋势、云原生大规模的落地实践,做最懂云原生开发者的技术圈。” 【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
Helm是Kubernetes的一个软件包管理器。两个月前,它发布了第三个主要版本,Helm 3。在这一新版本中,有许多重大变化。本文将介绍我认为最关键的5个方面。
1、 移除了Tiller
Helm最终移除了其服务器端组件,Tiller。现在,它完全没有代理。Tiller之前是一个运行在Kubernetes上的小型应用程序,它用于监听Helm命令并处理设置Kubernetes资源的实际工作。
这是Helm3中最重大的更改。为什么Tiller的移除备受关注呢?首先,Helm应该是一种在Kubernetes配置上的模板机制。那么,为什么需要在服务器上运行某些代理呢?
Tiller本身也存在一些问题,因为它需要集群管理员的ClusterRole才能创建。因此,假设你要在Google Cloud Platform中启动的Kubernetes集群上运行Helm应用程序。首先,你需要启动一个新的GKE集群,然后使用helm init初始化Helm,然后…发现它失败了。这种情况之所以会发生是因为,在默认状态下,你没有给你的kubectl上下文分配管理员权限。现在你了解到了这一点,开始搜索为分配管理员权限的magic命令。这一系列操作下来,也许你已经开始怀疑Helm是否真的是一个不错的选择。
此外,由于Tiller使用的访问权限与你在kubectl上下文中配置的访问权限不同。因此,你也许可以使用Helm创建应用程序,但你可能无法使用kubectl创建该程序。这一情况如果没排查出来,看起来感觉像是安全漏洞。
幸运的是,现在Tiller已经被完全移除,Helm现在是一个客户端工具。这一更改会导致以下结果: Helm使用与kubectl上下文相同的访问权限 你无需再使用helm init来初始化Helm Release Name 位于命名空间中
Helm 3一直保持不变的是:它应该只是一个在Kubernetes API上执行操作的工具。如此,如果你可以使用纯粹的kubectl命令执行某项操作,那么也可以使用helm执行该操作。
2、 分布式仓库以及Helm Hub
Helm命令可以从远程仓库安装Chart。在Helm 3之前,它通常使用预定义的中心仓库,但你也能够添加其他仓库。但是从现在开始,Helm将其仓库模型从集中式迁移到分布式。这意味着两个重要的改变: 预定义的中心仓库被移除 Helm Hub(一个发现分布式chart仓库的平台)被添加到helm search
为了能够更好地理解这一改变,我给你们一个示例。在Helm 3之前,如果你想要安装一个Hazelcast集群,你需要执行以下命令: $ helm2 install --name my-release stable/hazelcast
现在,这个命令不起作用了。你需要先添加远程仓库才能进行安装。这是因为这里不再存在一个预定义中心仓库。要安装Hazelcast集群,你首先需要添加其仓库然后安装chart: $ helm3 repo add hazelcast https://hazelcast.github.io/charts/ $ helm3 repo update $ helm3 install my-release hazelcast/hazelcast
好消息是现在Helm 命令可以直接在Helm Hub中寻找Chart。例如,如果你想知道在哪个仓库中可以找到Hazelcast,你只需执行以下命令即可: $ helm3 search hub hazelcast
以上命令列出在Helm Hub中所有分布式仓库中名称中包含“hazelcast”的Chart。
现在,我来问你一个问题。移除掉中心仓库是进步还是退步?这有两种观点。第一种是chart维护者的观点。例如,我们维护Hazelcast Helm Chart,而Chart中的每个更改都需要我们将其传播到中心仓库中。这项额外的工作使得中心仓库中的许多Helm Chart没有得到很好地维护。这一情况与我们在Ubuntu/Debian包仓库中所经历的很相似。你可以使用默认仓库,但它常常只有旧的软件包版本。
第二种观点来自Chart的使用者。对于他们来说,虽然现在安装一个chart比之前稍微困难了一些,但另一方面,他们能够从主要的仓库中安装到最新的chart。
3、 JSON Schema 验证
从Helm 3开始,chart维护者可以为输入值定义JSON Schema。这一功能的完善十分重要,因为迄今为止你可以在values.yaml中放入任何你所需的内容,但是安装的最终结果可能不正确或出现一些难以理解的错误消息。
例如,你在port参数中输入字符串而不是数字。那么你会收到以下错误: $ helm2 install --name my-release --set service.port=string-name hazelcast/hazelcast Error: release my-release failed: Service in version "v1" cannot be handled as a Service: v1.Service.Spec: v1.ServiceSpec.Ports: []v1.ServicePort: v1.ServicePort.Port: readUint32: unexpected character: �, error found in #10 byte of ...|","port":"wrong-name|..., bigger context ...|fault"},"spec":{"ports":[{"name":"hzport","port":"wrong-name","protocol": "TCP","targetPort":"hazelca|...
你不得不承认这个问题难以分析和理解。
此外,Helm 3默认添加了针对Kubernetes对象的OpenAPI验证,这意味着发送到Kubernetes API的请求将会被检查是否正确。这对于Chart维护者来说,是一项重大利好。
4、 Helm 测试
Helm测试是一个小小的优化。尽管微小,但它也许实际上鼓励了维护者来写Helm测试以及用户在安装完每个chart之后执行helm test命令。在Helm 3之前,进行测试多少都显得有些奇怪:
1、 此前测试作为Pod执行(好像需要一直运行);现在你可以将其定义为Job。
2、 测试Pod不会自动被移除(除非你使用magic flag –cleanup ),所以默认状态下,没有任何技巧,对于既定的版本你不能多次执行helm test。但幸运的是,现在可以自动删除测试资源(Pod、Job)。
当然旧的测试版本也并非不能使用,只需要使用Pod并始终记得执行 helm test –cleanup 。但也不得不承认,这一改进有助于提升测试体验。
5、 命令行语法
最后一点是,Helm命令语法有所改变。从积极的一面来看,我认为所有的改变都是为了让体验更好;从消极的方面看,这一语法不与之前的版本兼容。因此,现在编写有关如何使用Helm安装东西的步骤时,需要明确指出所使用的命令是用于Helm 2还是用于Helm 3。
举个例子,从 helm install 开始说起。现在版本名称已经成为必填参数,尽管在Helm 2中你可以忽略它,名称也能够自动生成。如果在Helm3中要达成相同的效果,你需要添加参数 --generate-name 。所以,使用Helm 2进行标准的安装应该如下: $ helm2 install --name my-release hazelcast/hazelcast
在Helm 3中,需要执行以下命令: $ helm3 install my-release hazelcast/hazelcast
还有另一个比较好的改变是,删除Helm版本后,无需添加—purge。简单地输入命令 helm uninstall 即可删除所有相关的资源。
还有一些其他改变,如一些命令被重命名(不过使用旧的名称作为别名),有一些命令则被删除(如 helm init )。如果你还想了解更多关于Helm 命令语法更改的信息,请参考官方文档:
https://helm.sh/docs/faq/#cli-command-renames
结 论
Helm 3的发布,使得这一工具迈向一个新的阶段。作为用户,我十分喜欢Helm现在只是一个单纯的客户端工具。作为Chart维护者,Helm Hub以及分布式仓库的方法深得我心。我希望能在未来看到更多更有意思的改变。
如果你想了解Helm 3中的所有变化,请查看官方文档:
https://helm.sh/docs/faq/#changes-since-helm-2 原文链接:
https://dzone.com/articles/helm-3-top-five-improvements 【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
作者 | 匡大虎 阿里巴巴技术专家 导读 :如何解决多租户集群的安全隔离问题是企业上云的一个关键问题,本文主要介绍 Kubernetes 多租户集群的基本概念和常见应用形态,以及在企业内部共享集群的业务场景下,基于 Kubernetes 原生和 ACK 集群现有安全管理能力快速实现多租户集群的相关方案。
什么是多租户集群?
这里首先介绍一下"租户",租户的概念不止局限于集群的用户,它可以包含为一组计算,网络,存储等资源组成的工作负载集合。而在多租户集群中,需要在一个集群范围内(未来可能会是多集群)对不同的租户提供尽可能的安全隔离,以最大程度的避免恶意租户对其他租户的攻击,同时需要保证租户之间公平地分配共享集群资源。
在隔离的安全程度上,我们可以将其分为软隔离 (Soft Multi-tenancy) 和硬隔离 (Hard Multi-tenancy) 两种。 其中软隔离更多的是面向企业内部的多租需求,该形态下默认不存在恶意租户,隔离的目的是为了内部团队间的业务保护和对可能的安全攻击进行防护; 而硬隔离面向的更多是对外提供服务的服务供应商,由于该业务形态下无法保证不同租户中业务使用者的安全背景,我们默认认为租户之间以及租户与 K8s 系统之间是存在互相攻击的可能,因此这里也需要更严格的隔离作为安全保障。
关于多租户的不同应用场景,在下节会有更细致的介绍。
多租户应用场景
下面介绍一下典型的两种企业多租户应用场景和不同的隔离需求:
企业内部共享集群的多租户
该场景下集群的所有用户均来自企业内部,这也是当前很多 K8s 集群客户的使用模式,因为服务使用者身份的可控性,相对来说这种业务形态的安全风险是相对可控的,毕竟老板可以直接裁掉不怀好意的员工:)根据企业内部人员结构的复杂程度,我们可以通过命名空间对不同部门或团队进行资源的逻辑隔离,同时定义以下几种角色的业务人员: 集群管理员:具有集群的管理能力(扩缩容、添加节点等操作);负责为租户管理员创建和分配命名空间;负责各类策略(RAM/RBAC/networkpolicy/quota...)的 CRUD; 租户管理员:至少具有集群的 RAM 只读权限;管理租户内相关人员的 RBAC 配置; 租户内用户:在租户对应命名空间内使用权限范围内的 K8s 资源。
在建立了基于用户角色的访问控制基础上,我们还需要保证命名空间之间的网络隔离,在不同的命名空间之间只能够允许白名单范围内的跨租户应用请求。
另外,对于业务安全等级要求较高的应用场景,我们需要限制应用容器的内核能力,可以配合 seccomp / AppArmor / SELinux 等策略工具达到限制容器运行时刻 capabilities 的目的。
当然 Kubernetes 现有的命名空间单层逻辑隔离还不足以满足一部分大型企业应用复杂业务模型对隔离需求,我们可以关注 Virtual Cluster ,它通过抽象出更高级别的租户资源模型来实现更精细化的多租管理,以此弥补原生命名空间能力上的不足。
SaaS & KaaS 服务模型下的多租户
在 SaaS 多租场景下, Kubernetes 集群中的租户对应为 SaaS 平台中各服务应用实例和 SaaS 自身控制平面,该场景下可以将平台各服务应用实例划分到彼此不同的命名空间中。而服务的最终用户是无法与 Kubernetes 的控制平面组件进行交互,这些最终用户能够看到和使用的是 SaaS 自身控制台,他们通过上层定制化的 SaaS 控制平面使用服务或部署业务(如下左图所示)。
例如,某博客平台部署在多租户集群上运行。在该场景下,租户是每个客户的博客实例和平台自己的控制平面。平台的控制平面和每个托管博客都将在不同的命名空间中运行。客户将通过平台的界面来创建和删除博客、更新博客软件版本,但无法了解集群的运作方式。
KaaS 多租场景常见于云服务提供商,该场景下业务平台的服务直接通过 Kubernetes 控制平面暴露给不同租户下的用户,最终用户可以使用 K8s 原生 API 或者服务提供商基于 CRDs/controllers 扩展出的接口。出于隔离的最基本需求,这里不同租户也需要通过命名空间进行访问上的逻辑隔离,同时保证不同租户间网络和资源配额上的隔离。
与企业内部共享集群不同,这里的最终用户均来自非受信域,他们当中不可避免的存在恶意租户在服务平台上执行恶意代码,因此对于 SaaS/KaaS 服务模型下的多租户集群,我们需要更高标准的安全隔离,而 Kubernetes 现有原生能力还不足以满足安全上的需求,为此我们需要如安全容器这样在容器运行时刻内核级别的隔离来强化该业务形态下的租户安全。
实施多租户架构
在规划和实施多租户集群时,我们首先可以利用的是 Kubernetes 自身的资源隔离层,包括集群本身、命名空间、节点、pod 和容器均是不同层次的资源隔离模型。当不同租户的应用负载能够共享相同的资源模型时,就会存在彼此之间的安全隐患。为此,我们需要在实施多租时控制每个租户能够访问到的资源域,同时在资源调度层面尽可能的保证处理敏感信息的容器运行在相对独立的资源节点内;如果出于资源开销的角度,当有来自不同租户的负载共享同一个资源域时,可以通过运行时刻的安全和资源调度控制策略减少跨租户攻击的风险。
虽然 Kubernetes 现有安全和调度能力还不足以完全安全地实施多租隔离,但是在如企业内部共享集群这样的应用场景下,通过命名空间完成租户间资源域的隔离,同时通过 RBAC、PodSecurityPolicy、NetworkPolicy 等策略模型控制租户对资源访问范围和能力的限制,以及现有资源调度能力的结合,已经可以提供相当的安全隔离能力。而对于 SaaS、KaaS 这样的服务平台形态,我们可以通过阿里云容器服务近期推出的 安全沙箱容器 来实现容器内核级别的隔离,能够最大程度的避免恶意租户通过逃逸手段的跨租户攻击。
本节重点关注基于 Kubernetes 原生安全能力的多租户实践。
访问控制
AuthN & AuthZ & Admission
ACK 集群的授权分为 RAM 授权和 RBAC 授权两个步骤,其中 RAM 授权作用于集群管理接口的访问控制,包括对集群的 CRUD 权限(如集群可见性、扩缩容、添加节点等操作),而 RBAC 授权用于集群内部 Kubernetes 资源模型的访问控制,可以做到指定资源在命名空间粒度的细化授权。
ACK 授权管理为租户内用户提供了不同级别的预置角色模板,同时支持绑定多个用户自定义的集群角色,此外支持对批量用户的授权。如需详细了解 ACK 上集群相关访问控制授权,请参阅 相关帮助文档 。
NetworkPolicy
NetworkPolicy 可以控制不同租户业务 pod 之间的网络流量,另外可以通过白名单的方式打开跨租户之间的业务访问限制。
您可以在使用了 Terway 网络插件的容器服务集群上配置 NetworkPolicy, 这里 可以获得一些策略配置的示例。
PodSecurityPolicy
PSP 是 K8s 原生的集群维度的资源模型,它可以在apiserver中pod创建请求的 admission 阶段校验其运行时刻行为是否满足对应 PSP 策略的约束,比如检查 pod 是否使用了 host 的网络、文件系统、指定端口、PID namespace 等,同时可以限制租户内的用户开启特权(privileged)容器,限制挂盘类型,强制只读挂载等能力;不仅如此,PSP 还可以基于绑定的策略给 pod 添加对应的 SecurityContext,包括容器运行时刻的 uid,gid 和添加或删除的内核 capabilities 等多种设置。
关于如何开启 PSP admission 和相关策略及权限绑定的使用,可以参阅 这里 。
OPA
OPA(Open Policy Agent)是一种功能强大的策略引擎,支持解耦式的 policy decisions 服务并且社区已经有了相对成熟的与 Kubernetes 的 集成方案 。当现有 RBAC 在命名空间粒度的隔离不能够满足企业应用复杂的安全需求时,可以通过 OPA 提供 object 模型级别的细粒度访问策略控制。
同时 OPA 支持七层的 NetworkPolicy 策略定义及基于 labels/annotation 的跨命名空间访问控制,可以作为 K8s 原生 NetworkPolicy 的有效增强。
资源调度相关
Resource Quotas & Limit Range
在多租户场景下,不同团队或部门共享集群资源,难免会有资源竞争的情况发生,为此我们需要对每个租户的资源使用配额做出限制。其中 ResourceQuota 用于限制租户对应命名空间下所有 pod 占用的总资源 request 和 limit,LimitRange 用来设置租户对应命名空间中部署 pod 的默认资源 request 和 limit 值。另外我们还可以对租户的存储资源配额和对象数量配额进行限制。
关于资源配额的详细指导可以参见 这里 。
Pod Priority/Preemption
从 1.14 版本开始 pod 的优先级和抢占已经从 beta 成为稳定特性,其中 pod priority 标识了 pod 在 pending 状态的调度队列中等待的优先级;而当节点资源不足等原因造成高优先的 pod 无法被调度时,scheduler 会尝试驱逐低优先级的 pod 来保证高优先级 pod 可以被调度部署。
在多租户场景下,可以通过优先级和抢占设置确保租户内重要业务应用的可用性;同时 pod priority 可以和 ResouceQuota 配合使用,完成租户在指定优先级下有多少配额的限制。
Dedicated Nodes
注意:恶意租户可以规避由节点污点和容忍机制强制执行的策略。以下说明仅用于企业内部受信任租户集群,或租户无法直接访问 Kubernetes 控制平面的集群。
通过对集群中的某些节点添加污点,可以将这些节点用于指定几个租户专门使用。在多租户场景下,例如集群中的 GPU 节点可以通过污点的方式保留给业务应用中需要使用到 GPU 的服务团队使用。集群管理员可以通过如 effect: "NoSchedule" 这样的标签给节点添加污点,同时只有配置了相应容忍设置的 pod 可以被调度到该节点上。
当然恶意租户可以同样通过给自身 pod 添加同样的容忍配置来访问该节点,因此仅使用节点污点和容忍机制还无法在非受信的多租集群上保证目标节点的独占性。
关于如何使用节点污点机制来控制调度,请参阅 这里 。
敏感信息保护
secrets encryption at REST
在多租户集群中不同租户用户共享同一套 etcd 存储,在最终用户可以访问 Kubernetes 控制平面的场景下,我们需要保护 secrets 中的数据,避免在访问控制策略配置不当情况下的敏感信息泄露。为此可以参考 K8s 原生的 secret 加密能力,请参阅 这里 。
ACK 也提供了基于阿里云 KMS 服务的 secrets 加密开源解决方案,可以参阅 这里 。
总结
在实施多租户架构时首先需要确定对应的应用场景,包括判断租户内用户和应用负载的可信程度以及对应的安全隔离程度。在此基础上以下几点是安全隔离的基本需求: 开启 Kubernetes 集群的默认安全配置:开启 RBAC 鉴权并实现基于namespace的软隔离;开启 secrets encryption 能力,增强敏感信息保护;基于 CIS Kubernetes benchmarks 进行相应的安全配置; 开启 NodeRestriction, AlwaysPullImages, PodSecurityPolicy 等相关 admission controllers; 通过 PSP 限制 pod 部署的特权模式,同时控制其运行时刻 SecurityContext; 配置 NetworkPolicy; 使用Resource Quota & Limit Range限制租户的资源使用配额; 在应用运行时刻遵循权限的最小化原则,尽可能缩小pod内容器的系统权限; Log everything; 对接监控系统,实现容器应用维度的监控。
而对于如 SaaS、KaaS 等服务模型下,或者我们无法保证租户内用户的可信程度时,我们需要采取一些更强有力的隔离手段,比如: 使用如 OPA 等动态策略引擎进行网络或 Object 级别的细粒度访问控制; 使用安全容器实现容器运行时刻内核级别的安全隔离; 完备的监控、日志、存储等服务的多租隔离方案。
注意: 文中图片来源 。 “ 阿里巴巴云原生 关注微服务、Serverless、容器、Service Mesh 等技术领域、聚焦云原生流行技术趋势、云原生大规模的落地实践,做最懂云原生开发者的技术圈。” 【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
在Heketi的glusterd容器服务,使用systemctl探针来检测glusterfs服务是否可用,发现总是出现失败问题。
经查,在Ubuntu 18.04 上 systemctl status glusterd.service 运行时输出信息不是K8s livenessProbe希望的,导致检测器超时挂起了。 使用 systemctl status glusterd.service并不能检测到服务的真实状态 ,会挂起、超时,返回错误状态码。
使用下面的方式,可以正确检测service的真实状态: systemctl is-active --quiet glusterd.service; echo $?;
或者(类似于): systemctl is-active sshd >/dev/null 2>&1 && echo 0 || echo 1
输出: 正常时 0; 非正常时为错误码。 如下所示: livenessProbe: exec: command: - /bin/bash - -c - systemctl is-active --quiet glusterd.service; echo $?; failureThreshold: 3 initialDelaySeconds: 60 periodSeconds: 10 successThreshold: 1 timeoutSeconds: 3 readinessProbe: exec: command: - /bin/bash - -c - systemctl is-active --quiet glusterd.service; echo $?;
修改后的k8s yaml文件如下: apiVersion: apps/v1 kind: DaemonSet metadata: name: glusterfs-daemon namespace: gluster labels: k8s-app: glusterfs-node spec: selector: matchLabels: name: glusterfs-daemon template: metadata: labels: name: glusterfs-daemon spec: tolerations: - key: node-role.kubernetes.io/master effect: NoSchedule containers: - image: gluster/gluster-centos:latest imagePullPolicy: IfNotPresent name: glusterfs livenessProbe: exec: command: - /bin/bash - -c - systemctl is-active --quiet glusterd.service; echo $?; failureThreshold: 3 initialDelaySeconds: 60 periodSeconds: 10 successThreshold: 1 timeoutSeconds: 3 readinessProbe: exec: command: - /bin/bash - -c - systemctl is-active --quiet glusterd.service; echo $?; failureThreshold: 3 initialDelaySeconds: 60 periodSeconds: 10 successThreshold: 1 timeoutSeconds: 3 resources: {} securityContext: capabilities: {} privileged: true terminationMessagePath: /dev/termination-log terminationMessagePolicy: File volumeMounts: - mountPath: /var/lib/heketi name: glusterfs-heketi - mountPath: /run name: glusterfs-run - mountPath: /run/lvm name: glusterfs-lvm - mountPath: /etc/glusterfs name: glusterfs-etc - mountPath: /var/log/glusterfs name: glusterfs-logs - mountPath: /var/lib/glusterd name: glusterfs-config - mountPath: /dev name: glusterfs-dev - mountPath: /sys/fs/cgroup name: glusterfs-cgroup dnsPolicy: ClusterFirst hostNetwork: true restartPolicy: Always schedulerName: default-scheduler securityContext: {} terminationGracePeriodSeconds: 30 volumes: - hostPath: path: /var/lib/heketi type: "" name: glusterfs-heketi - emptyDir: {} name: glusterfs-run - hostPath: path: /run/lvm type: "" name: glusterfs-lvm - hostPath: path: /etc/glusterfs type: "" name: glusterfs-etc - hostPath: path: /var/log/glusterfs type: "" name: glusterfs-logs - hostPath: path: /var/lib/glusterd type: "" name: glusterfs-config - hostPath: path: /dev type: "" name: glusterfs-dev - hostPath: path: /sys/fs/cgroup type: "" name: glusterfs-cgroup
可能在不同的Linux版本上,systemd的版本不同,参数也可能不一样,输入systemctl help来获取当前版本的帮助。 【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
ceph的MDS是cephFS文件存储服务的元数据服务。
当创建cephfs后便会有ceph-mds服务进行管理。默认情况下ceph会分配一个mds服务管理cephfs,即使已经创建多个mds服务,如下: [root@ceph-admin my-cluster]# ceph-deploy mds create ceph-node01 ceph-node02 ....... [root@ceph-admin ~]# ceph -s cluster: id: 06dc2b9b-0132-44d2-8a1c-c53d765dca5d health: HEALTH_OK services: mon: 2 daemons, quorum ceph-admin,ceph-node01 mgr: ceph-admin(active) mds: mytest-fs-1/1/1 up {0=ceph-admin=up:active}, 2 up:standby osd: 3 osds: 3 up, 3 in rgw: 2 daemons active data: pools: 8 pools, 64 pgs objects: 299 objects, 137 MiB usage: 3.4 GiB used, 297 GiB / 300 GiB avail pgs: 64 active+clean
此时mds中只有ceph-admin处于active状态,其余处于standby状态。
standby已近是一种灾备状态,但事实上切换速度比较缓慢,对于实际业务系统必定会造成影响。
测试情况如下: [root@ceph-admin my-cluster]# killall ceph-mds [root@ceph-admin my-cluster]# ceph -s cluster: id: 06dc2b9b-0132-44d2-8a1c-c53d765dca5d health: HEALTH_WARN 1 filesystem is degraded services: mon: 2 daemons, quorum ceph-admin,ceph-node01 mgr: ceph-admin(active) mds: mytest-fs-1/1/1 up {0=ceph-node02=up:rejoin}, 1 up:standby osd: 3 osds: 3 up, 3 in rgw: 2 daemons active data: pools: 8 pools, 64 pgs objects: 299 objects, 137 MiB usage: 3.4 GiB used, 297 GiB / 300 GiB avail pgs: 64 active+clean [root@ceph-admin my-cluster]# ceph -s cluster: id: 06dc2b9b-0132-44d2-8a1c-c53d765dca5d health: HEALTH_OK services: mon: 2 daemons, quorum ceph-admin,ceph-node01 mgr: ceph-admin(active) mds: mytest-fs-1/1/1 up {0=ceph-node02=up:active}, 1 up:standby osd: 3 osds: 3 up, 3 in rgw: 2 daemons active data: pools: 8 pools, 64 pgs objects: 299 objects, 137 MiB usage: 3.4 GiB used, 297 GiB / 300 GiB avail pgs: 64 active+clean io: client: 20 KiB/s rd, 3 op/s rd, 0 op/s wr
系统在active的mds被kill之后,standby的mds在经过rejoin状态后才变成了active,大约经过3-5s。而在生产环境中由于元数据的数据量更庞大,往往会更漫长。
而要让mds更快切换,需要将我们的mds服务切换至 standby_replay 状态,官方对于此状态的说明如下:
The MDS is following the journal of another up:active MDS. Should the active MDS fail, having a standby MDS in replay mode is desirable as the MDS is replaying the live journal and will more quickly takeover. A downside to having standby replay MDSs is that they are not available to takeover for any other MDS that fails, only the MDS they follow.
事实上就是standby_replay会实时根据active的mds元数据日志进行同步更新,这样就能加快切换的速率,那么如何让mds运行在standby_replay状态? [root@ceph-node01 ~]# ps aufx|grep mds root 700547 0.0 0.0 112704 976 pts/1 S+ 13:45 0:00 \_ grep --color=auto mds ceph 690340 0.0 0.5 451944 22988 ? Ssl 10:09 0:03 /usr/bin/ceph-mds -f --cluster ceph --id ceph-node01 --setuser ceph --setgroup ceph [root@ceph-node01 ~]# killall ceph-mds [root@ceph-node01 ~]# /usr/bin/ceph-mds -f --cluster ceph --id ceph-node01 --setuser ceph --setgroup ceph --hot-standby 0 starting mds.ceph-node01 at -
我们手动关闭了ceph-mds服务并且添加了--hot-standby 参数重新启动了mds服务。
接下来看到,ceph-node02的mds已经处于standby-replay状态: [root@ceph-admin my-cluster]# ceph -s cluster: id: 06dc2b9b-0132-44d2-8a1c-c53d765dca5d health: HEALTH_OK services: mon: 2 daemons, quorum ceph-admin,ceph-node01 mgr: ceph-admin(active) mds: mytest-fs-1/1/1 up {0=ceph-admin=up:active}, 1 up:standby-replay, 1 up:standby osd: 3 osds: 3 up, 3 in rgw: 2 daemons active data: pools: 8 pools, 64 pgs objects: 299 objects, 137 MiB usage: 3.4 GiB used, 297 GiB / 300 GiB avail pgs: 64 active+clean io: client: 851 B/s rd, 1 op/s rd, 0 op/s wr
当然或者可以ceph-mds的启动脚本来让服务启动时自动处于standby-replay状态 【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
2019年已经过去,小编为大家整理了这一年以来云加社区发布的 200多篇腾讯干货,点击文章标题即可跳转到原文,请速速收藏哦~
看腾讯技术 :
腾讯成本优化黑科技: 整机CPU利用率最高提升至90% ;
腾讯科技升级1000天: 团战、登月与烟囱革命 ;
“看一看”推荐模型揭秘!微信团队提出实时Look-alike算法,解决推荐系统多样性问题 ;
10亿级存储挑战!看一看、微信广告、微信支付、小程序都在用的存储系统究竟是怎么扛住的?!
微信扫物上线,全面揭秘扫一扫背后的识物技术!
微信搜一搜正在用的新一代海量数据搜索引擎 TurboSearch 是什么来头?
微信读书怎么给你做推荐的?
浅谈微视推荐系统中的特征工程 ;
一直陪伴你成长的 QQ 相册后台长什么样?
一支笔撑起黑科技课堂? 背后的技术秘密原来是这样的 ;
服务15亿+游戏用户数据的腾讯iData分析中心进化之路: 计算引擎基础能力构建 ;
服务15亿+游戏用户数据的腾讯iData分析中心进化之路: 为什么要用Spark? ;
旧的不去、新的不来: 腾讯iData分析中心的进化之路 ;
2019腾讯区块链白皮书 | 附完整版下载 ;
IPv4 地址已耗尽,IPv6 涅槃重生 | 腾讯云IPv6改造综 ;
述 腾讯云IPv6私有网络及负载均衡最佳实践指南 。
看腾讯上云:
冲上云霄! 腾讯海量业务上云实践 ;
基于腾讯云TKE的大规模强化学习实践 ;
聚焦技术和实践,腾讯云全面揭秘基础设施和大数据演进之路 ;
如何利用Kubernetes集群提升资源利用率?
腾讯游戏营销活动在腾讯云K8S上的实践 ;
腾讯自研业务上云: 优化Kubernetes集群负载的技术方案探讨 ;
重磅! 腾讯云首次披露自研业务上云历程 ;
迁移1500TB视频! 腾讯课堂音视频上云变革之路 ;
细节披露:腾讯课堂是如何把海量视频资源搬上云端的?
硬核实战 | 腾讯在线教育部上云实践和架构演进思考 。
看腾讯开源:
从用户成为“股东”--在Apache基金会的2600天 ;
覆盖4.6亿+设备量!腾讯开源的Hardcoder框架是如何提升Android APP性能的?
首次! 腾讯全面公开整体开源路线图 ;
腾讯开源内部跨端框架 Hippy,打磨三年,日均 PV 过亿 ;
腾讯正式开源图计算框架Plato,十亿级节点图计算进入分钟级时代 ;
写速度提升20%,Elasticsearch 创始人给腾讯云发来感谢信 ;
正式开源!腾讯自研轻量级物联网操作系统 TencentOS tiny,最小体积仅1.8KB!
看业界专家:
竞技世界资深数据库工程师杨建荣:程序员软实力如何构建? 他坚持了2100多天,收获了这些心得 ;
vivo互联网架构师杨振涛: DevOps时代的软件过程改进探讨 ;
心莱科技CEO/CTO李文强: 割裂的云计算服务与其发展理念相悖 ;
北辰时代信息技术有限公司技术总监涂川:十四年从业经验看传统行业落地云计算现状 ;
沪江资深应用架构师王清培: Zookeeper 实现分布式锁安全用法 ;
蘑菇街技术总监赵成: 给运维同学的一个转型建议 ;
猫眼基础架构&基础服务团队负责人陈超: 架构师成长之路之Servicemesh罪与罚 ;
猫眼基础架构&基础服务团队负责人陈超: 架构师成长之路之限流 ;
开源社联合创始人刘天栋: 开源 社区重于代码,应避免“KPI”项目 ;
同程艺龙交通首席架构师李智慧:如何用反应式编程提升系统性能与可用性?
猫眼娱乐基础架构负责人陈超: 图解大型网站技术架构的历史演化过程 ;
同程艺龙机票事业群CTO王晓波: 云上“多活”,同程艺龙应用架构设计与实践 ;
蘑菇街技术总监赵成:做容灾,双活、多活、同城、异地、多云,到底应该怎么选?
感知5G风起:
重磅! 腾讯5G探索地图揭秘 。
2024年视频在移动端流量占比将达74%或更高,将极大促进多媒体技术发展 ;
5G风起,CDN边缘计算将乘风破浪 ;
5G风起,未来数据库有哪些关键词?
5G风起:技术演进背后,标准必要专利扮演着怎样的角色?
5G下CDN技术与产业发展变化,将会如何引领时代发展?
只有5G而没有视频压缩,那么多媒体传输一切都是0 ;
捕捉Serverless前沿:
4招教你基于 Serverless 快速构建应用 ;
Serverless 2.0 重磅发布,无服务器时代来临 ;
Serverless,将给前端发展带来大变革的技术?
Serverless开发者工具上手实践 │ 腾讯云大学 ;
前端学Serverless系列--性能调优 ;
使用 Serverless 进行 AI 预测推理 ;
腾讯云成为Serverless.com大中华区独家合作伙伴!揭秘其背后的技术发展与生态建设 ;
以微信小程序相册为例,看Serverless DevOps最佳实践 ;
掌握Serverless: 基本概念入门 ;
掌握Serverless: 运行原理与组件架构 ;
周维跃: Severless 云函数架构精解(附视频回放) ;
踏上物联网时代:
5G时代,日益重要的边缘计算,你真的了解吗?
边缘计算为什么会迅速占据市场?
说说边缘计算那些事儿│腾讯云大学 ;
腾讯发布智能门锁安全规范,守卫物联网产业链安全 | 附全文下载 ;
腾讯物联网操作系统 TencentOS tiny 架构解析与实践 ;
腾讯云重磅发布“腾讯连连”,以小程序为载体助力万物互联 ;
物联网的未来是什么? 边缘计算助力万物智联(文末有福利) ;
详解腾讯云IoT全栈产品矩阵,6大产品及3大案例 。
面向大前端:
腾讯专家工程师: 2020年,前端发展关键词有哪些?
一行代码解决! iOS二进制重排启动优化 ;
NGW,前端新技术赛场: Serverless SSR 技术内幕 ;
Node部署和运维工作量降低80%,腾讯NOW直播是怎么做到的?
Webpack 4 编译代码如何完美适配 IE 内核 ;
从前端开发到全栈开发;你都了解吗?
秒开率达90%: 腾讯看点客户端 GIF 转视频优化方案 ;
前端工程化实践总结 | QQ音乐商业化Web团队 ;
前端解答>>你真的了解回流和重绘吗?
实时渲染不是梦: 通过共享内存优化Flutter外接纹理的渲染性能 ;
腾讯视频Node.js服务是如何支撑国庆阅兵直播高并发的?
图解浏览器缓存 写给前端工程师的 Flutter 教程 ;
收获小程序技巧:
AI智能客服小程序·云开发实践 ;
大漠穷秋:如何快速构建一款SCRM小程序?
借助云能力,小游戏开发过程是如何升级的?
开发小游戏,云开发真的是银弹吗?
快速实现运营需求,猫眼电影是如何做的?
同程艺龙小程序性能监控系统的探索与实践 ;
微信官方小程序同构新方案Kbone全解析 ;
InfoQ专访腾讯高级工程师: 小程序云开发即将发布实时数据推送服务 ;
我的小游戏开发之路|腾讯TGideas周桂华(花叔) ;
如何快速构建一款联机游戏?
mpvue+云开发,纯前端实现婚礼邀请函小程序 ;
Omi × 云开发『半天』搞定小程序 『markdown 内容发布系统』 ;
Taro + 小程序云开发实战|日语用例助手 ;
单机小游戏变多人联机,原来只需要几分钟!
零部署,零维护,随手记Lite小程序云开发实战分享 ;
巧用云调用,实现【共享名片夹】小程序 ;
如何不用服务器来开发一个小游戏 ;
如何不用服务器来开发一个小游戏 ;
云开发xWePY,快速实现Linux命令查询小程序 ;
云开发定时触发器应用实战 I Moly 订阅助手小程序 ;
云开发实战分享|诗和远方: 旅行小账本云开发 ;
云开发实战分享|一天搭建一个社区 ;
云开发数据库又增新技能!
云调用,小程序鉴权正确姿势 。
把握智慧未来:
AIoT,构建更佳边缘AI能力 ;
AI在K8S中的实践: 云智天枢AI中台架构揭秘 ;
多轮对话机器人打造: 着手设计 ;
多轮对话机器人打造: 话题意图识别 ;
机器学习技术如何推动工业界发展?
基于LSTM的情感识别在鹅漫评论分析中的应用与实践 ;
基于混合集成学习算法的热迁移超时预测模型 ;
厉害了!用腾讯优图AI视觉模组DIY一个属于自己的疲劳驾驶检测仪!
三次大浪潮推进的AI背后对应哪些技术? | 产品经理眼中的AI简史 ;
深入浅出话智能语音识别 | 腾讯云大学大咖分享 ;
腾讯车载小程序:智慧出行的场景化落地 腾讯云人脸融合技术是如何构建的?
腾讯云人脸识别系统在传统行业的应用与落地 ;
腾讯云文字识别OCR技术构建和应用 ;
腾讯云音视频AI技术落地实践全解析 ;
腾讯云知识图谱实践 | 腾讯云大学大咖分享 ;
腾讯云自然语言处理的技术架构与应用 ;
腾讯专家浅谈构建图像识别系统的方法 ;
游戏AI:只是AI间的游戏,还是游戏的未来?
语音识别中CTC算法的基本原理解释 ;
云+ AI 技术在高端酒店行业的应用 ;
智慧城市数字化园区建设,背后实现的技术解析 ;
智能钛机器学习平台在工业和金融行业的落地 ;
云+AI技术助攻,智慧酒店原来是这样的!
剖析数据秘密:
后端开发术语大全 ;
快速读懂innodb存储引擎 ;
(内附独家PPT)李岩: CynosDB高可用系统介绍 ;
【迪B课堂】MySQL运行时系统CPU压力大怎么办?
CynosDB for MySQL 计算存储分离架构的实现和优化 ;
CynosDB分布式存储的核心原理 ;
3分钟学会如何调度运营海量Redis系统 ;
CynosDB for PostgreSQL 一主多读架构设计及优化[内附独家PPT] ;
国际数据库顶会VLDB,解密腾讯TDSQL全时态数据库系统 ;
揭秘全球最大出行业务背后的数据库系统 ;
金融级分布式数据库打造! TDSQL在微众银行的大规模实践 ;
科普:如何正确的选择云数据库?
了解数据库分片(Database Sharding) ;
磊哥测评之数据库SaaS篇: 腾讯云控制台、DMC和小程序 ;
你的数据库,真的安全吗?
深度 | 腾讯云自研数据库技术揭秘 ;
数据库大咖丁奇:MySQL索引存储顺序和order by不一致,怎么办?
想让MySQL跑得更快,更不可忽略这些硬件和系统的优化!
一节课搞懂MySQL数据类型 ;
蛰伏到爆发! 腾讯云数据库获全球“实力竞争者” ;
自研数据库CynosDB可计算智能存储揭秘!
yarn 在快手的应用实践与技术演进之路 ;
腾讯数据库专家雷海林分享智能运维架构 。
构建安全壁垒:
从图文到视频直播,内容风控应如何做到准确、实时、批量鉴黄?
黑灰产技术手段不断“进阶”,如何防御双十二“羊毛党”?
几乎所有企业都要参加的网络安全大考,应该如何准备?
实力认证! 腾讯主导确立全球首个零信任安全国际标准 ;
腾讯专家解读:内容平台如何借助 AI 鉴黄,提升风控能力? | 群分享预告 ;
我们常听说UDP反射攻击,那你听说过TCP反射攻击吗?
如何利用云安全运营中心监测数据泄露 ;
云端安全小建议-使用EMR分析云审计数据 。
盘点架构发展:
企业微服务技术中台落地实践 ;
从技术演变的角度看互联网后台架构 ;
基于Kubernetes 构建.NET Core 技术中台 ;
如何架构海量存储系统 ;
什么是容器云?
如何在Kubernetes中实现容器原地升级 ;
Elasticsearch 7.0 Zen2 开启Elasticsearch分布式新纪元 ;
基于Elastic Stack的日志分析系统 ;
如何基于PaaS快速构建企业运维的工具文化?
掌握音视频趋势:
今年火热的实时音视频技术为什么要和古老的PSTN融合?
视频制作领域——如何提升内容产出效率 ;
腾讯云海外直播系统架构是怎么设计的?(附视频回放)
移动直播连麦技术实践(附视频回放) ;
音视频融合通信技术的最佳实践,全在这里了 ;
张鹏: 腾讯云直播PCDN加速方案(附视频回放) 。
集赞得奖
感谢大家过去一年来的陪伴,为此我们也准备了一些小小的礼物送给大家。请大家到我们的 微信公众号“云加社区”同一篇文章下面参与评论和留言(扫描文章底部二维码即可关注) ,发表你对云加社区过去一年内容的想法或者建议。我们将会 抽选留言区点赞数最多的15位同学,送上爱心公仔。
/活动礼品/
鼠年公仔*5
腾讯云公仔*10
/集赞规则/
1.留言点赞数排名前15的同学将会获得公仔礼品,其中排名前5位得鼠年公仔一份,剩下10位得腾讯云公仔一份;
2.本次集赞活动截止到2020年1月7日中午12:00为止;
3.中奖后请于2020年1月10日前将留言截图及邮寄地址发送至公众号后台,进行兑奖,逾期视为放弃领奖。
技术沙龙大盘点
在最后,我们还为大家准备了一份别样的礼物。整个2019年,社区举办了超过15场线下沙龙,邀请了腾讯及行业内近百位高级工程师、产品负责人等,为大家带来最新的技术分享和行业应用案例。这些内容,我们也统统为大家做好了归纳和盘点。
公众号后台回复“技术沙龙”,即可获得全套内容下载链接 ,感兴趣的小伙伴一定不要错过。
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>> 作者 | 杨成立(忘篱) 阿里巴巴高级技术专家 关注“阿里巴巴云原生”公众号,回复 Go 即可查看清晰知识大图! 导读 :从问题本身出发,不局限于 Go 语言,探讨服务器中常常遇到的问题,最后回到 Go 如何解决这些问题,为大家提供 Go 开发的关键技术指南。我们将以系列文章的形式推出 《Go 开发的关键技术指南》 ,共有 4 篇文章,本文为第 2 篇。 Could Not Recover 在 C/C++ 中, 最苦恼的 莫过于上线后发现有野指针或内存越界,导致不可能崩溃的地方崩溃; 最无语的 是因为很早写的日志打印,比如 %s 把整数当字符串,突然某天执行到了崩溃; 最无奈的 是无论因为什么崩溃都导致服务的所有用户受到影响。 如果能有一种方案,将指针和内存都管理起来,避免用户错误访问和释放,这样虽然浪费了一部分的 CPU,但是可以在快速变化的业务中避免这些头疼的问题。在现代的高级语言中,比如 Java、Python 和 JS 的异常,以及 Go 的 panic-recover 都是这种机制。 毕竟,用一些 CPU 换得快速迭代中的不 Crash,怎么算都是划得来的。 哪些可以 Recover Go 有 Defer, Panic, and Recover 。其中 defer 一般用在资源释放或者捕获 panic。而 panic 是中止正常的执行流程,执行所有的 defer,返回调用函数继续 panic;主动调用 panic 函数,还有些运行时错误都会进入 panic 过程。最后 recover 是在 panic 时获取控制权,进入正常的执行逻辑。 注意 recover 只有在 defer 函数中才有用,在 defer 的函数调用的函数中 recover 不起作用,如下实例代码不会 recover: go package main import "fmt" func main() { f := func() { if r := recover(); r != nil { fmt.Println(r) } } defer func() { f() } () panic("ok") } 执行时依旧会 panic,结果如下: $ go run t.go panic: ok goroutine 1 [running]: main.main() /Users/winlin/temp/t.go:16 +0x6b exit status 2 有些情况是不可以被捕获,程序会自动退出,这种都是无法正常 recover。当然,一般的 panic 都是能捕获的,比如 Slice 越界、nil 指针、除零、写关闭的 chan。 下面是 Slice 越界的例子,recover 可以捕获到: go package main import ( "fmt" ) func main() { defer func() { if r := recover(); r != nil { fmt.Println(r) } }() b := []int{0, 1} fmt.Println("Hello, playground", b[2]) } 下面是 nil 指针被引用的例子,recover 可以捕获到: go package main import ( "bytes" "fmt" ) func main() { defer func() { if r := recover(); r != nil { fmt.Println(r) } }() var b *bytes.Buffer fmt.Println("Hello, playground", b.Bytes()) } 下面是除零的例子,recover 可以捕获到: go package main import ( "fmt" ) func main() { defer func() { if r := recover(); r != nil { fmt.Println(r) } }() var v int fmt.Println("Hello, playground", 1/v) } 下面是写关闭的 chan 的例子,recover 可以捕获到: go package main import ( "fmt" ) func main() { defer func() { if r := recover(); r != nil { fmt.Println(r) } }() c := make(chan bool) close(c) c <- true } Recover 最佳实践 一般 recover 后会判断是否 err,有可能需要处理特殊的 error,一般也需要打印日志或者告警,给一个 recover 的例子: package main import ( "fmt" ) type Handler interface { Filter(err error, r interface{}) error } type Logger interface { Ef(format string, a ...interface{}) } // Handle panic by hdr, which filter the error. // Finally log err with logger. func HandlePanic(hdr Handler, logger Logger) error { return handlePanic(recover(), hdr, logger) } type hdrFunc func(err error, r interface{}) error func (v hdrFunc) Filter(err error, r interface{}) error { return v(err, r) } type loggerFunc func(format string, a ...interface{}) func (v loggerFunc) Ef(format string, a ...interface{}) { v(format, a...) } // Handle panic by hdr, which filter the error. // Finally log err with logger. func HandlePanicFunc(hdr func(err error, r interface{}) error, logger func(format string, a ...interface{}), ) error { var f Handler if hdr != nil { f = hdrFunc(hdr) } var l Logger if logger != nil { l = loggerFunc(logger) } return handlePanic(recover(), f, l) } func handlePanic(r interface{}, hdr Handler, logger Logger) error { if r != nil { err, ok := r.(error) if !ok { err = fmt.Errorf("r is %v", r) } if hdr != nil { err = hdr.Filter(err, r) } if err != nil && logger != nil { logger.Ef("panic err %+v", err) } return err } return nil } func main() { func() { defer HandlePanicFunc(nil, func(format string, a ...interface{}) { fmt.Println(fmt.Sprintf(format, a...)) }) panic("ok") }() logger := func(format string, a ...interface{}) { fmt.Println(fmt.Sprintf(format, a...)) } func() { defer HandlePanicFunc(nil, logger) panic("ok") }() } 对于库如果需要启动 goroutine,如何 recover 呢? 如果不可能出现 panic,可以不用 recover,比如 tls.go 中的一个 goroutine: errChannel <- conn.Handshake() ; 如果可能出现 panic,也比较明确的可以 recover,可以调用用户回调,或者让用户设置 logger,比如 http/server.go 处理请求的 goroutine: if err := recover(); err != nil && err != ErrAbortHandler { ; 如果完全不知道如何处理 recover,比如一个 cache 库,丢弃数据可能会造成问题,那么就应该由用户来启动 goroutine,返回异常数据和错误,用户决定如何 recover、如何重试; 如果完全知道如何 recover,比如忽略 panic 继续跑,或者能使用 logger 打印日志,那就按照正常的 panic-recover 逻辑处理。 哪些不能 Recover 下面看看一些情况是无法捕获的,包括(不限于): Thread Limit,超过了系统的线程限制,详细参考下面的说明; Concurrent Map Writers,竞争条件,同时写 map,参考下面的例子。推荐使用标准库的 sync.Map 解决这个问题。 Map 竞争写导致 panic 的实例代码如下: go package main import ( "fmt" "time" ) func main() { m := map[string]int{} p := func() { defer func() { if r := recover(); r != nil { fmt.Println(r) } }() for { m["t"] = 0 } } go p() go p() time.Sleep(1 * time.Second) } 注意:如果编译时加了 -race ,其他竞争条件也会退出,一般用于死锁检测,但这会导致严重的性能问题,使用需要谨慎。 备注:一般标准库中通过 throw 抛出的错误都是无法 recover 的,搜索了下 Go1.11 一共有 690 个地方有调用 throw。 Go1.2 引入了能使用的最多线程数限制 ThreadLimit ,如果超过了就 panic,这个 panic 是无法 recover 的。 fatal error: thread exhaustion runtime stack: runtime.throw(0x10b60fd, 0x11) /usr/local/Cellar/go/1.8.3/libexec/src/runtime/panic.go:596 +0x95 runtime.mstart() /usr/local/Cellar/go/1.8.3/libexec/src/runtime/proc.go:1132 默认是 1 万个物理线程,我们可以调用 runtime 的 debug.SetMaxThreads 设置最大线程数。 SetMaxThreads sets the maximum number of operating system threads that the Go program can use. If it attempts to use more than this many, the program crashes. SetMaxThreads returns the previous setting. The initial setting is 10,000 threads. 用这个函数设置程序能使用的最大系统线程数,如果超过了程序就 crash,返回的是之前设置的值,默认是 1 万个线程。 The limit controls the number of operating system threads, not the number of goroutines. A Go program creates a new thread only when a goroutine is ready to run but all the existing threads are blocked in system calls, cgo calls, or are locked to other goroutines due to use of runtime.LockOSThread. 注意限制的并不是 goroutine 的数目,而是使用的系统线程的限制。goroutine 启动时,并不总是新开系统线程,只有当目前所有的物理线程都阻塞在系统调用、cgo 调用,或者显示有调用 runtime.LockOSThread 时。 SetMaxThreads is useful mainly for limiting the damage done by programs that create an unbounded number of threads. The idea is to take down the program before it takes down the operating system. 这个是最后的防御措施,可以在程序干死系统前把有问题的程序干掉。 举一个简单的例子,限制使用 10 个线程,然后用 runtime.LockOSThread 来绑定 goroutine 到系统线程,可以看到没有创建 10 个 goroutine 就退出了(runtime 也需要使用线程)。参考下面的例子 Playground: ThreadLimit: go package main import ( "fmt" "runtime" "runtime/debug" "sync" "time" ) func main() { nv := 10 ov := debug.SetMaxThreads(nv) fmt.Println(fmt.Sprintf("Change max threads %d=>%d", ov, nv)) var wg sync.WaitGroup c := make(chan bool, 0) for i := 0; i < 10; i++ { fmt.Println(fmt.Sprintf("Start goroutine #%v", i)) wg.Add(1) go func() { c <- true defer wg.Done() runtime.LockOSThread() time.Sleep(10 * time.Second) fmt.Println("Goroutine quit") }() <- c fmt.Println(fmt.Sprintf("Start goroutine #%v ok", i)) } fmt.Println("Wait for all goroutines about 10s...") wg.Wait() fmt.Println("All goroutines done") } 运行结果如下: bash Change max threads 10000=>10 Start goroutine #0 Start goroutine #0 ok ...... Start goroutine #6 Start goroutine #6 ok Start goroutine #7 runtime: program exceeds 10-thread limit fatal error: thread exhaustion runtime stack: runtime.throw(0xffdef, 0x11) /usr/local/go/src/runtime/panic.go:616 +0x100 runtime.checkmcount() /usr/local/go/src/runtime/proc.go:542 +0x100 ...... /usr/local/go/src/runtime/proc.go:1830 +0x40 runtime.startm(0x1040e000, 0x1040e000) /usr/local/go/src/runtime/proc.go:2002 +0x180 从这次运行可以看出,限制可用的物理线程为 10 个,其中系统占用了 3 个物理线程,user-level 可运行 7 个线程,开启第 8 个线程时就崩溃了。 注意这个运行结果在不同的 go 版本是不同的,比如 Go1.8 有时候启动 4 到 5 个 goroutine 就会崩溃。 而且加 recover 也无法恢复,参考下面的实例代码。 可见这个机制是最后的防御,不能突破的底线。我们在线上服务时,曾经因为 block 的 goroutine 过多,导致触发了这个机制。 go package main import ( "fmt" "runtime" "runtime/debug" "sync" "time" ) func main() { defer func() { if r := recover(); r != nil { fmt.Println("main recover is", r) } } () nv := 10 ov := debug.SetMaxThreads(nv) fmt.Println(fmt.Sprintf("Change max threads %d=>%d", ov, nv)) var wg sync.WaitGroup c := make(chan bool, 0) for i := 0; i < 10; i++ { fmt.Println(fmt.Sprintf("Start goroutine #%v", i)) wg.Add(1) go func() { c <- true defer func() { if r := recover(); r != nil { fmt.Println("main recover is", r) } } () defer wg.Done() runtime.LockOSThread() time.Sleep(10 * time.Second) fmt.Println("Goroutine quit") }() <- c fmt.Println(fmt.Sprintf("Start goroutine #%v ok", i)) } fmt.Println("Wait for all goroutines about 10s...") wg.Wait() fmt.Println("All goroutines done") } 如何避免程序超过线程限制被干掉?一般可能阻塞在 system call,那么什么时候会阻塞?还有, GOMAXPROCS 又有什么作用呢? The GOMAXPROCS variable limits the number of operating system threads that can execute user-level Go code simultaneously. There is no limit to the number of threads that can be blocked in system calls on behalf of Go code; those do not count against the GOMAXPROCS limit. This package's GOMAXPROCS function queries and changes the limit. GOMAXPROCS sets the maximum number of CPUs that can be executing simultaneously and returns the previous setting. If n < 1, it does not change the current setting. The number of logical CPUs on the local machine can be queried with NumCPU. This call will go away when the scheduler improves. 可见 GOMAXPROCS 只是设置 user-level 并行执行的线程数,也就是真正执行的线程数 。实际上如果物理线程阻塞在 system calls,会开启更多的物理线程。关于这个参数的说明,文章《 Number of threads used by goroutine 》解释得很清楚: There is no direct correlation. Threads used by your app may be less than, equal to or more than 10. So if your application does not start any new goroutines, threads count will be less than 10. If your app starts many goroutines (>10) where none is blocking (e.g. in system calls), 10 operating system threads will execute your goroutines simultaneously. If your app starts many goroutines where many (>10) are blocked in system calls, more than 10 OS threads will be spawned (but only at most 10 will be executing user-level Go code). 设置 GOMAXPROCS 为 10:如果开启的 goroutine 小于 10 个,那么物理线程也小于 10 个。如果有很多 goroutines,但是没有阻塞在 system calls,那么只有 10 个线程会并行执行。如果有很多 goroutines 同时超过 10 个阻塞在 system calls,那么超过 10 个物理线程会被创建,但是只有 10 个活跃的线程执行 user-level 代码。 那么什么时候会阻塞在 system blocking 呢?例子《 Why does it not create many threads when many goroutines are blocked in writing 》解释很清楚,虽然设置了 GOMAXPROCS 为 1,但实际上还是开启了 12 个线程,每个 goroutine 一个物理线程,具体执行下面的代码 Writing Large Block: go package main import ( "io/ioutil" "os" "runtime" "strconv" "sync" ) func main() { runtime.GOMAXPROCS(1) data := make([]byte, 128*1024*1024) var wg sync.WaitGroup for i := 0; i < 10; i++ { wg.Add(1) go func(n int) { defer wg.Done() for { ioutil.WriteFile("testxxx"+strconv.Itoa(n), []byte(data), os.ModePerm) } }(i) } wg.Wait() } 运行结果如下: Mac chengli.ycl$ time go run t.go real 1m44.679s user 0m0.230s sys 0m53.474s 虽然 GOMAXPROCS 设置为 1,实际上创建了 12 个物理线程。 有大量的时间是在 sys 上面,也就是 system calls。 So I think the syscalls were exiting too quickly in your original test to show the effect you were expecting. Effective Go 中的解释: Goroutines are multiplexed onto multiple OS threads so if one should block, such as while waiting for I/O, others continue to run. Their design hides many of the complexities of thread creation and management. 由此可见,如果程序出现因为超过线程限制而崩溃,那么可以在出现瓶颈时,用 linux 工具查看系统调用的统计,看哪些系统调用导致创建了过多的线程。 Errors 错误处理是现实中经常碰到的、难以处理好的问题,下面会从下面几个方面探讨错误处理: 为什么 Go 没有选择异常,而是返回错误码(error)? 因为异常模型很难看出有没有写对,错误码方式也不容易,相对会简单点。 Go 的 error 有什么问题,为何 Go2 草案这么大篇幅说 error 改进? 因为 Go 虽然是错误码但还不够好,问题在于啰嗦、繁杂、缺失关键信息。 有哪些好用的 error 库,如何和日志配合使用? 推荐用库 pkg/errors ;另外,避免日志和错误混淆。 Go 的错误处理最佳实践是什么? 配合日志使用错误。错误需要带上上下文、堆栈等信息。 错误和异常 我们总会遇到非预期的非正常情况,有一种是符合预期的,比如函数返回 error 并处理,这种叫做可以预见到的错误,还有一种是预见不到的比如除零、空指针、数组越界等叫做 panic,panic 的处理主要参考 Defer, Panic, and Recover 。 错误处理的模型一般有两种,一般是错误码模型比如 C/C++ 和 Go,还有异常模型比如 Java 和 C#。Go 没有选择异常模型,因为错误码比异常更有优势,参考文章《 Cleaner, more elegant, and wrong 》以及《 Cleaner, more elegant, and harder to recognize 》。 看下面的代码: try { AccessDatabase accessDb = new AccessDatabase(); accessDb.GenerateDatabase(); } catch (Exception e) { // Inspect caught exception } public void GenerateDatabase() { CreatePhysicalDatabase(); CreateTables(); CreateIndexes(); } 这段代码的错误处理有很多问题,比如如果 CreateIndexes 抛出异常,会导致数据库和表不会删除,造成脏数据。从代码编写者和维护者的角度看这两个模型,会比较清楚: 错误处理不容易做好,要说容易那说明做错了;要把错误处理写对了,基于错误码模型虽然很难,但比异常模型简单。 如果使用错误码模型,非常容易就能看出错误处理没有写对,也能很容易知道做得好不好;要知道是否做得非常好,错误码模型也不太容易。 如果使用异常模型,无论做的好不好都很难知道,而且也很难知道怎么做好。 Errors in Go Go 官方的 error 介绍,简单一句话就是返回错误对象的方式,参考《 Error handling and Go 》,解释了 error 是什么?如何判断具体的错误?以及显式返回错误的好处。 文中举的例子就是打开文件错误: func Open(name string) (file *File, err error) Go 可以返回多个值,最后一个一般是 error,我们需要检查和处理这个错误,这就是 Go 的错误处理的官方介绍: if err := Open("src.txt"); err != nil { // Handle err } 看起来非常简单的错误处理,有什么难的呢?稍等,在 Go2 的草案中,提到的三个点 Error Handling 、 Error Values 和 Generics 泛型 ,两个点都是错误处理的,这说明了 Go1 中对于错误是有改进的地方。 再详细看下 Go2 的草案, 错误处理:Error Handling 中,主要描述了发生错误时的重复代码,以及不能便捷处理错误的情况。比如草案中举的这个例子 No Error Handling: CopyFile,没有做任何错误处理: package main import ( "fmt" "io" "os" ) func CopyFile(src, dst string) error { r, _ := os.Open(src) defer r.Close() w, _ := os.Create(dst) io.Copy(w, r) w.Close() return nil } func main() { fmt.Println(CopyFile("src.txt", "dst.txt")) } 还有草案中这个例子 Not Nice and still Wrong: CopyFile,错误处理是特别啰嗦,而且比较明显有问题: package main import ( "fmt" "io" "os" ) func CopyFile(src, dst string) error { r, err := os.Open(src) if err != nil { return err } defer r.Close() w, err := os.Create(dst) if err != nil { return err } defer w.Close() if _, err := io.Copy(w, r); err != nil { return err } if err := w.Close(); err != nil { return err } return nil } func main() { fmt.Println(CopyFile("src.txt", "dst.txt")) } 当 io.Copy 或 w.Close 出现错误时,目标文件实际上是有问题,那应该需要删除 dst 文件的。而且需要给出错误时的信息,比如是哪个文件,不能直接返回 err。所以 Go 中正确的错误处理,应该是这个例子 Good: CopyFile,虽然啰嗦繁琐不简洁: package main import ( "fmt" "io" "os" ) func CopyFile(src, dst string) error { r, err := os.Open(src) if err != nil { return fmt.Errorf("copy %s %s: %v", src, dst, err) } defer r.Close() w, err := os.Create(dst) if err != nil { return fmt.Errorf("copy %s %s: %v", src, dst, err) } if _, err := io.Copy(w, r); err != nil { w.Close() os.Remove(dst) return fmt.Errorf("copy %s %s: %v", src, dst, err) } if err := w.Close(); err != nil { os.Remove(dst) return fmt.Errorf("copy %s %s: %v", src, dst, err) } return nil } func main() { fmt.Println(CopyFile("src.txt", "dst.txt")) } 具体应该如何简洁的处理错误,可以读 Error Handling ,大致是引入关键字 handle 和 check,由于本文重点侧重 Go1 如何错误处理,就不展开分享了。 明显上面每次都返回的 fmt.Errorf 信息也是不够的,所以 Go2 还对于错误的值有提案,参考 Error Values 。大规模程序应该面向错误编程和测试,同时错误应该包含足够的信息。 Go1 中判断 error 具体是什么错误,有以下几种办法: 直接比较,比如返回的是 io.EOF 这个全局变量,那么可以直接比较是否是这个错误; 可以用类型转换 type 或 switch,尝试来转换成具体的错误类型,看是哪种错误; 提供某些函数来判断是否是某个错误,比如 os.IsNotExist 判断是否是指定错误; 当多个错误被糅合到一起时,只能用 error.Error() 返回的字符串匹配,看是否是某个错误。 在复杂程序中,有用的错误需要包含调用链的信息。例如,考虑一次数据库写,可能调用了 RPC,RPC 调用了域名解析,最终是没有权限读 /etc/resolve.conf 文件,那么给出下面的调用链会非常有用: write users database: call myserver.Method: \ dial myserver:3333: open /etc/resolv.conf: permission denied Errors Solutions 由于 Go1 的错误值没有完整的解决这个问题,才导致出现非常多的错误处理的库,比如: 2017 年 12 月, upspin.io/errors,带逻辑调用堆栈的错误库,而不是执行的堆栈,引入了 errors.Is 、 errors.As 和 errors.Match ; 2015 年 12 月, github.com/pkg/errors,带堆栈的错误,引入了 %+v 来格式化错误的额外信息比如堆栈; 2014 年 10 月, github.com/hashicorp/errwrap,可以 wrap 多个错误,引入了错误树,提供 Walk 函数遍历所有的错误; 2014 年 2 月, github.com/juju/errgo,Wrap 时可以选择是否隐藏底层错误。和 pkg/errors 的 Cause 返回最底层的错误不同,它只反馈错误链的下一个错误; 2013 年 7 月, github.com/spacemonkeygo/errors,是来源于一个大型 Python 项目,有错误的 hierarchies,自动记录日志和堆栈,还可以带额外的信息。打印错误的消息比较固定,不能自己定义; 2019 年 9 月, Go1.13 标准库扩展了 error,支持了 Unwrap、As 和 Is,但没有支持堆栈信息。 Go1.13 改进了 errors,参考如下实例代码: package main import ( "errors" "fmt" "io" ) func foo() error { return fmt.Errorf("read err: %w", io.EOF) } func bar() error { if err := foo(); err != nil { return fmt.Errorf("foo err: %w", err) } return nil } func main() { if err := bar(); err != nil { fmt.Printf("err: %+v\n", err) fmt.Printf("unwrap: %+v\n", errors.Unwrap(err)) fmt.Printf("unwrap of unwrap: %+v\n", errors.Unwrap(errors.Unwrap(err))) fmt.Printf("err is io.EOF? %v\n", errors.Is(err, io.EOF)) } } 运行结果如下: err: foo err: read err: EOF unwrap: read err: EOF unwrap of unwrap: EOF err is io.EOF? true 从上面的例子可以看出: 没有堆栈信息,主要是想通过 Wrap 的日志来标识堆栈,如果全部 Wrap 一层和堆栈差不多,不过对于没有 Wrap 的错误还是无法知道调用堆栈; Unwrap 只会展开第一个嵌套的 error,如果错误有多层嵌套,取不到最里面的那个 error,需要多次 Unwrap 才行; 用 errors.Is 能判断出是否是最里面的那个 error。 另外,错误处理往往和 log 是容易混为一谈的,因为遇到错误一般会打日志,特别是在 C/C 中返回错误码一般都会打日志记录下,有时候还会记录一个全局的错误码比如 linux 的 errno,而这种习惯,导致 error 和 log 混淆造成比较大的困扰。考虑以前写了一个 C 的服务器,出现错误时会在每一层打印日志,所以就会形成堆栈式的错误日志,便于排查问题,如果只有一个错误,不知道调用上下文,排查会很困难: avc decode avc_packet_type failed. ret=3001 Codec parse video failed, ret=3001 origin hub error, ret=3001 这种比只打印一条日志 origin hub error, ret=3001 要好,但是还不够好: 和 Go 的错误一样,比较啰嗦,有重复的信息。如果能提供堆栈信息,可以省去很多需要手动写的信息; 对于应用程序可以打日志,但是对于库,信息都应该包含在 error 中,不应该直接打印日志。如果底层的库都要打印日志,将会导致底层库都要依赖日志库,这时很多库都有日志打印函数供调用者重写; 对于多线程,看不到线程信息,或者看不到业务层 ID 的信息。对于服务器来说,有时候需要知道这个错误是哪个连接的,从而查询这个连接之前的上下文信息。 改进后的错误日志变成了在底层返回,而不在底层打印在调用层打印,有调用链和堆栈,有线程切换的 ID 信息,也有文件的行数: Error processing video, code=3001 : origin hub : codec parser : avc decoder [100] video_avc_demux() at [srs_kernel_codec.cpp:676] [100] on_video() at [srs_app_source.cpp:1076] [101] on_video_imp() at [srs_app_source:2357] 从 Go2 的描述来说,实际上这个错误处理也还没有考虑完备。从实际开发来说,已经比较实用了。 总结下 Go 的 error,错误处理应该注意以下几点: 凡是有返回错误码的函数,必须显式的处理错误,如果要忽略错误,也应该显式的忽略和写注释; 错误必须带丰富的错误信息,比如堆栈、发生错误时的参数、调用链给的描述等等。特别要强调变量,我看过太多日志描述了一对常量,比如 "Verify the nonce, timestamp and token of specified appid failed",而这个消息一般会提到工单中,然后就是再问用户,哪个 session 或 request 甚至时间点?这么一大堆常量有啥用呢,关键是变量呐; 尽量避免重复的信息,提高错误处理的开发体验,糟糕的体验会导致无效的错误处理代码,比如拷贝和漏掉关键信息; 分离错误和日志,发生错误时返回带完整信息的错误,在调用的顶层决定是将错误用日志打印,还是发送到监控系统,还是转换错误,或者忽略。 Best Practice 推荐用 github.com/pkg/errors 这个错误处理的库,基本上是够用的,参考 Refine: CopyFile,可以看到 CopyFile 中低级重复的代码已经比较少了: package main import ( "fmt" "github.com/pkg/errors" "io" "os" ) func CopyFile(src, dst string) error { r, err := os.Open(src) if err != nil { return errors.Wrap(err, "open source") } defer r.Close() w, err := os.Create(dst) if err != nil { return errors.Wrap(err, "create dest") } nn, err := io.Copy(w, r) if err != nil { w.Close() os.Remove(dst) return errors.Wrap(err, "copy body") } if err := w.Close(); err != nil { os.Remove(dst) return errors.Wrapf(err, "close dest, nn=%v", nn) } return nil } func LoadSystem() error { src, dst := "src.txt", "dst.txt" if err := CopyFile(src, dst); err != nil { return errors.WithMessage(err, fmt.Sprintf("load src=%v, dst=%v", src, dst)) } // Do other jobs. return nil } func main() { if err := LoadSystem(); err != nil { fmt.Printf("err %+v\n", err) } } 改写的函数中,用 errors.Wrap 和 errors.Wrapf 代替了 fmt.Errorf ,我们不记录 src 和 dst 的值,因为在上层会记录这个值(参考下面的代码),而只记录我们这个函数产生的数据,比如 nn 。 import "github.com/pkg/errors" func LoadSystem() error { src, dst := "src.txt", "dst.txt" if err := CopyFile(src, dst); err != nil { return errors.WithMessage(err, fmt.Sprintf("load src=%v, dst=%v", src, dst)) } // Do other jobs. return nil } 在这个上层函数中,我们用的是 errors.WithMessage 添加了这一层的错误信息,包括 src 和 dst ,所以 CopyFile 里面就不用重复记录这两个数据了。同时我们也没有打印日志,只是返回了带完整信息的错误。 func main() { if err := LoadSystem(); err != nil { fmt.Printf("err %+v\n", err) } } 在顶层调用时,我们拿到错误,可以决定是打印还是忽略还是送监控系统。 比如我们在调用层打印错误,使用 %+v 打印详细的错误,有完整的信息: err open src.txt: no such file or directory open source main.CopyFile /Users/winlin/t.go:13 main.LoadSystem /Users/winlin/t.go:39 main.main /Users/winlin/t.go:49 runtime.main /usr/local/Cellar/go/1.8.3/libexec/src/runtime/proc.go:185 runtime.goexit /usr/local/Cellar/go/1.8.3/libexec/src/runtime/asm_amd64.s:2197 load src=src.txt, dst=dst.txt 但是这个库也有些小毛病: CopyFile 中还是有可能会有重复的信息,还是 Go2 的 handle 和 check 方案是最终解决; 有时候需要用户调用 Wrap ,有时候是调用 WithMessage (不需要加堆栈时),这个真是非常不好用的地方(这个我们已经修改了库,可以全部使用 Wrap 不用 WithMessage,会去掉重复的堆栈)。 Logger 一直在码代码,对日志的理解总是不断在变,大致分为几个阶段: 日志是给人看的,是用来查问题的。出现问题后根据某些条件,去查不同进程或服务的日志。日志的关键是不能漏掉信息,漏了关键日志,可能就断了关键的线索; 日志必须要被关联起来,上下文的日志比单个日志更重要。长连接需要根据会话关联日志;不同业务模型有不同的上下文,比如服务器管理把服务器作为关键信息,查询这个服务器的相关日志;全链路跨机器和服务的日志跟踪,需要定义可追踪的逻辑 ID; 海量日志是给机器看的,是结构化的,能主动报告问题,能从日志中分析潜在的问题。日志的关键是要被不同消费者消费,要输出不同主题的日志,不同的粒度的日志。日志可以用于排查问题,可以用于告警,可以用于分析业务情况。 Note: 推荐阅读 Kafka 对于 Log 的定义,广义日志是可以理解的消息, The Log: What every software engineer should know about real-time data's unifying abstraction 。 完善信息查问题 考虑一个服务,处理不同的连接请求: package main import ( "context" "fmt" "log" "math/rand" "os" "time" ) type Connection struct { url string logger *log.Logger } func (v *Connection) Process(ctx context.Context) { go checkRequest(ctx, v.url) duration := time.Duration(rand.Int()%1500) * time.Millisecond time.Sleep(duration) v.logger.Println("Process connection ok") } func checkRequest(ctx context.Context, url string) { duration := time.Duration(rand.Int()%1500) * time.Millisecond time.Sleep(duration) logger.Println("Check request ok") } var logger *log.Logger func main() { ctx := context.Background() rand.Seed(time.Now().UnixNano()) logger = log.New(os.Stdout, "", log.LstdFlags) for i := 0; i < 5; i++ { go func(url string) { connecton := &Connection{} connecton.url = url connecton.logger = logger connecton.Process(ctx) }(fmt.Sprintf("url #%v", i)) } time.Sleep(3 * time.Second) } 这个日志的主要问题,就是有了和没有差不多,啥也看不出来,常量太多变量太少,缺失了太多的信息。看起来这是个简单问题,却经常容易犯这种问题,需要我们在打印每个日志时,需要思考这个日志比较完善的信息是什么。上面程序输出的日志如下: 2019/11/21 17:08:04 Check request ok 2019/11/21 17:08:04 Check request ok 2019/11/21 17:08:04 Check request ok 2019/11/21 17:08:04 Process connection ok 2019/11/21 17:08:05 Process connection ok 2019/11/21 17:08:05 Check request ok 2019/11/21 17:08:05 Process connection ok 2019/11/21 17:08:05 Check request ok 2019/11/21 17:08:05 Process connection ok 2019/11/21 17:08:05 Process connection ok 如果完善下上下文信息,代码可以改成这样: type Connection struct { url string logger *log.Logger } func (v *Connection) Process(ctx context.Context) { go checkRequest(ctx, v.url) duration := time.Duration(rand.Int()%1500) * time.Millisecond time.Sleep(duration) v.logger.Println(fmt.Sprintf("Process connection ok, url=%v, duration=%v", v.url, duration)) } func checkRequest(ctx context.Context, url string) { duration := time.Duration(rand.Int()%1500) * time.Millisecond time.Sleep(duration) logger.Println(fmt.Sprintf("Check request ok, url=%v, duration=%v", url, duration)) } 输出的日志如下: 2019/11/21 17:11:35 Check request ok, url=url #3, duration=32ms 2019/11/21 17:11:35 Check request ok, url=url #0, duration=226ms 2019/11/21 17:11:35 Process connection ok, url=url #0, duration=255ms 2019/11/21 17:11:35 Check request ok, url=url #4, duration=396ms 2019/11/21 17:11:35 Check request ok, url=url #2, duration=449ms 2019/11/21 17:11:35 Process connection ok, url=url #2, duration=780ms 2019/11/21 17:11:35 Check request ok, url=url #1, duration=1.01s 2019/11/21 17:11:36 Process connection ok, url=url #4, duration=1.099s 2019/11/21 17:11:36 Process connection ok, url=url #3, duration=1.207s 2019/11/21 17:11:36 Process connection ok, url=url #1, duration=1.257s 上下文关联 完善日志信息后,对于服务器特有的一个问题,就是如何关联上下文,常见的上下文包括: 如果是短连接,一条日志就能描述,那可能要将多个服务的日志关联起来,将全链路的日志作为上下文; 如果是长连接,一般长连接一定会有定时信息,比如每隔 5 秒输出这个链接的码率和包数,这样每个链接就无法使用一条日志描述了,链接本身就是一个上下文; 进程内的逻辑上下文,比如代理的上下游就是一个上下文,合并回源,故障上下文,客户端重试等。 以上面的代码为例,可以用请求 URL 来作为上下文。 package main import ( "context" "fmt" "log" "math/rand" "os" "time" ) type Connection struct { url string logger *log.Logger } func (v *Connection) Process(ctx context.Context) { go checkRequest(ctx, v.url) duration := time.Duration(rand.Int()%1500) * time.Millisecond time.Sleep(duration) v.logger.Println(fmt.Sprintf("Process connection ok, duration=%v", duration)) } func checkRequest(ctx context.Context, url string) { duration := time.Duration(rand.Int()%1500) * time.Millisecond time.Sleep(duration) logger.Println(fmt.Sprintf("Check request ok, url=%v, duration=%v", url, duration)) } var logger *log.Logger func main() { ctx := context.Background() rand.Seed(time.Now().UnixNano()) logger = log.New(os.Stdout, "", log.LstdFlags) for i := 0; i < 5; i++ { go func(url string) { connecton := &Connection{} connecton.url = url connecton.logger = log.New(os.Stdout, fmt.Sprintf("[CONN %v] ", url), log.LstdFlags) connecton.Process(ctx) }(fmt.Sprintf("url #%v", i)) } time.Sleep(3 * time.Second) } 运行结果如下所示: [CONN url #2] 2019/11/21 17:19:28 Process connection ok, duration=39ms 2019/11/21 17:19:28 Check request ok, url=url #0, duration=149ms 2019/11/21 17:19:28 Check request ok, url=url #1, duration=255ms [CONN url #3] 2019/11/21 17:19:28 Process connection ok, duration=409ms 2019/11/21 17:19:28 Check request ok, url=url #2, duration=408ms [CONN url #1] 2019/11/21 17:19:29 Process connection ok, duration=594ms 2019/11/21 17:19:29 Check request ok, url=url #4, duration=615ms [CONN url #0] 2019/11/21 17:19:29 Process connection ok, duration=727ms 2019/11/21 17:19:29 Check request ok, url=url #3, duration=1.105s [CONN url #4] 2019/11/21 17:19:29 Process connection ok, duration=1.289s 如果需要查连接 2 的日志,可以 grep 这个 url #2 关键字: Mac:gogogo chengli.ycl$ grep 'url #2' t.log [CONN url #2] 2019/11/21 17:21:43 Process connection ok, duration=682ms 2019/11/21 17:21:43 Check request ok, url=url #2, duration=998ms 然鹅,还是发现有不少问题: 如何实现隐式标识,调用时如何简单些,不用没打一条日志都需要传一堆参数? 一般 logger 是公共函数(或者是每个类一个 logger),而上下文的生命周期会比 logger 长,比如 checkRequest 是个全局函数,标识信息必须依靠人打印,这往往是不可行的; 如何实现日志的 logrotate(切割和轮转),如何收集多个服务器日志。 解决办法包括: 用 Context 的 WithValue 来将上下文相关的 ID 保存,在打印日志时将 ID 取出来; 如果有业务特征,比如可以取 SessionID 的 hash 的前 8 个字符形成 ID,虽然容易碰撞,但是在一定范围内不容易碰撞; 可以变成 json 格式的日志,这样可以将 level、id、tag、file、err 都变成可以程序分析的数据,送到 SLS 中处理; 对于切割和轮转,推荐使用 lumberjack 这个库,程序的 logger 只要提供 SetOutput(io.Writer) 将日志送给它处理就可以了。 当然,这要求函数传参时需要带 context.Context,一般在自己的应用程序中可以要求这么做,凡是打日志的地方要带 context。对于库,一般可以不打日志,而返回带堆栈的复杂错误的方式,参考 Errors 错误处理部分。 点击下载《不一样的 双11 技术:阿里巴巴经济体云原生实践》 本书亮点 双11 超大规模 K8s 集群实践中,遇到的问题及解决方法详述 云原生化最佳组合:Kubernetes+容器+神龙,实现核心系统 100% 上云的技术细节 双 11 Service Mesh 超大规模落地解决方案 “ 阿里巴巴云原生 关注微服务、Serverless、容器、Service Mesh 等技术领域、聚焦云原生流行技术趋势、云原生大规模的落地实践,做最懂云原生开发者的技术圈。” | 
.png) 大数据引擎
大数据引擎.png) 大数据应用
大数据应用.png) 大数据底层技术
大数据底层技术.png) ForeSpider软件
ForeSpider软件
.png) 采集服务
采集服务.png) 软件学习
软件学习.png) 智能分析
智能分析.png) 特征提取
特征提取.png) 智能计算
智能计算.png) 数据可视化
数据可视化.png) 数据分析应用
数据分析应用.png) 系统集成服务
系统集成服务.png) 代码工具
代码工具.png) 金融方案
金融方案.png) 制造业&物流
制造业&物流.png) 企业数字化
企业数字化.png) 医疗方案
医疗方案.png) 政务方案
政务方案.png) 实时监测
实时监测.png) 智能分析
智能分析.png) 数据智能挖掘
数据智能挖掘.png) 全网自动采集
全网自动采集.png) 场景智慧采集
场景智慧采集.png) 主题识别采集
主题识别采集







 022-2345 2937
022-2345 2937 185 2247 0110
185 2247 0110 business@forenose.com
business@forenose.com














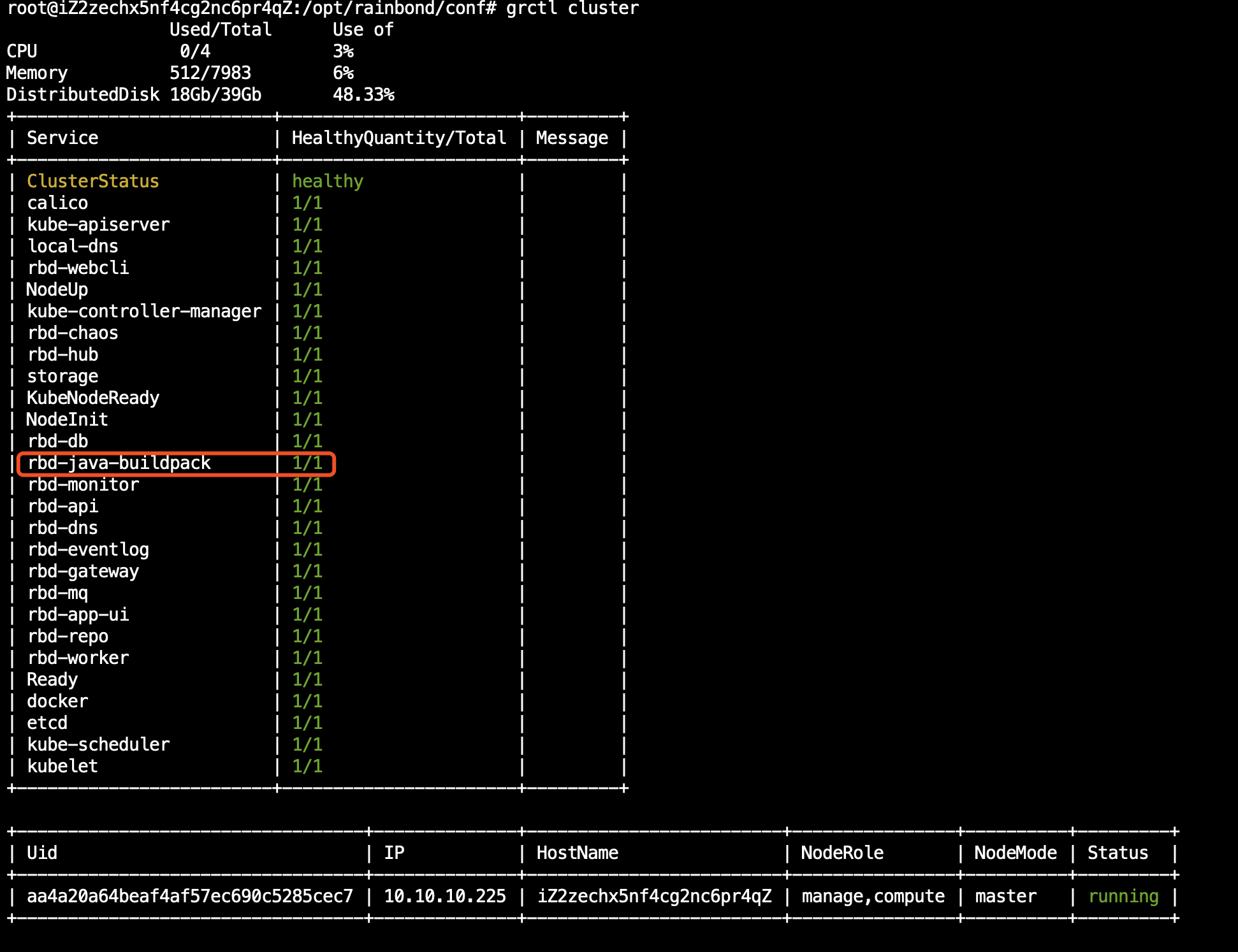 对接rbd-repo并修改远程仓库 所有节点rbd-repo都需要调整
对接rbd-repo并修改远程仓库 所有节点rbd-repo都需要调整  022-2345 2937
022-2345 2937 185 2247 0110
185 2247 0110 business@forenose.com
business@forenose.com 前嗅大数据
前嗅大数据