【场景描述】采集前程无忧招聘信息。
【源网站介绍】
前程无忧(NASDAQ:JOBS)是中国具有广泛影响力的人力资源服务供应商,在美国上市的中国人力资源服务企业,创立了网站+猎头+RPO+校园招聘+管理软件的全方位招聘方案。
【使用工具】前嗅ForeSpider数据采集系统,点击下方链接可免费下载
http://www.forenose.com/view/forespider/view/download.html
【入口网址】https://search.51job.com/list/010000,000000,0000,32,9,99,%25E4%25BA%25A7%25E5%2593%2581%25E7%25BB%258F%25E7%2590%2586,2,1.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=
【采集内容】
采集产品经理相关的招聘信息的岗位名称、发布单位、薪资范围、福利介绍、职位标签、招聘内容等。
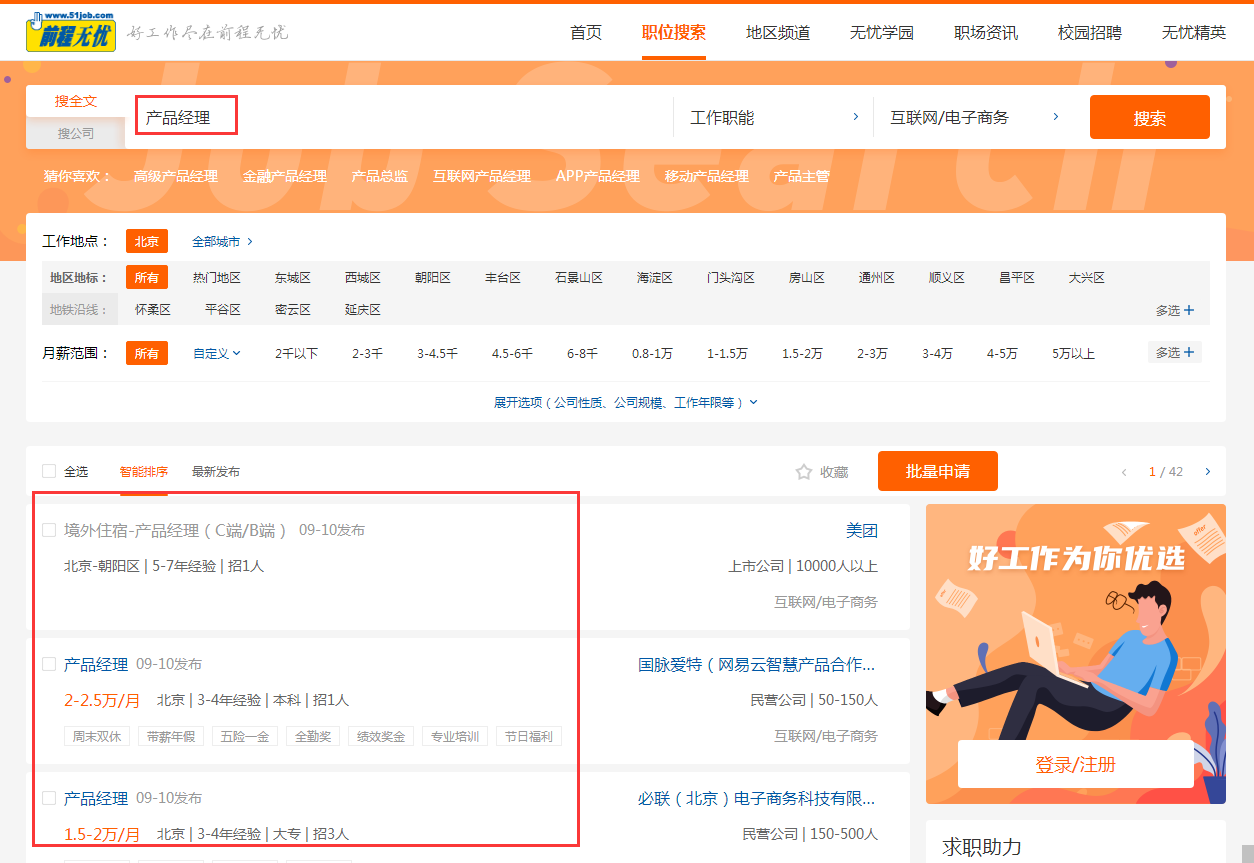

【采集效果】如下图所示:
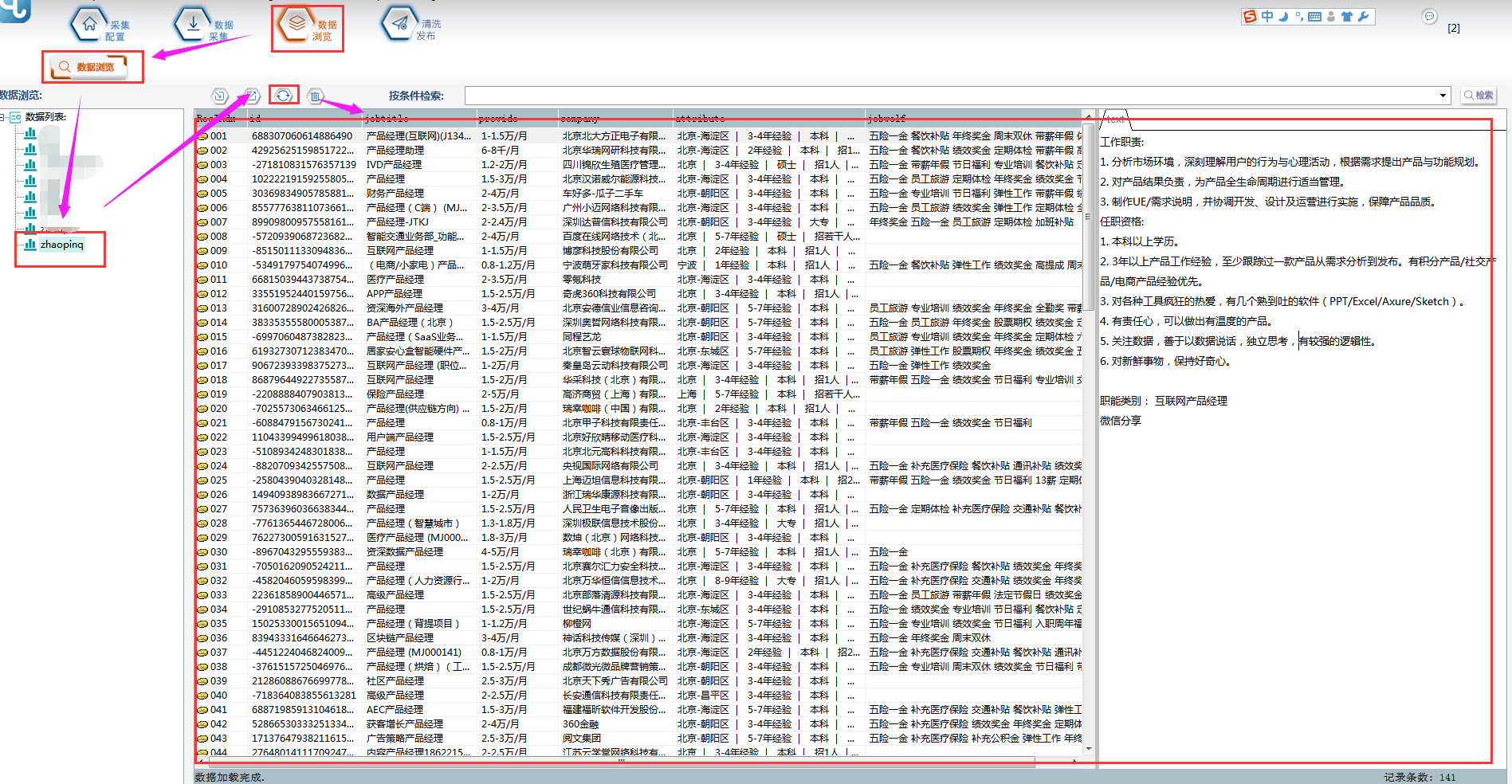
l 思路分析
配置思路概览:

l 配置步骤
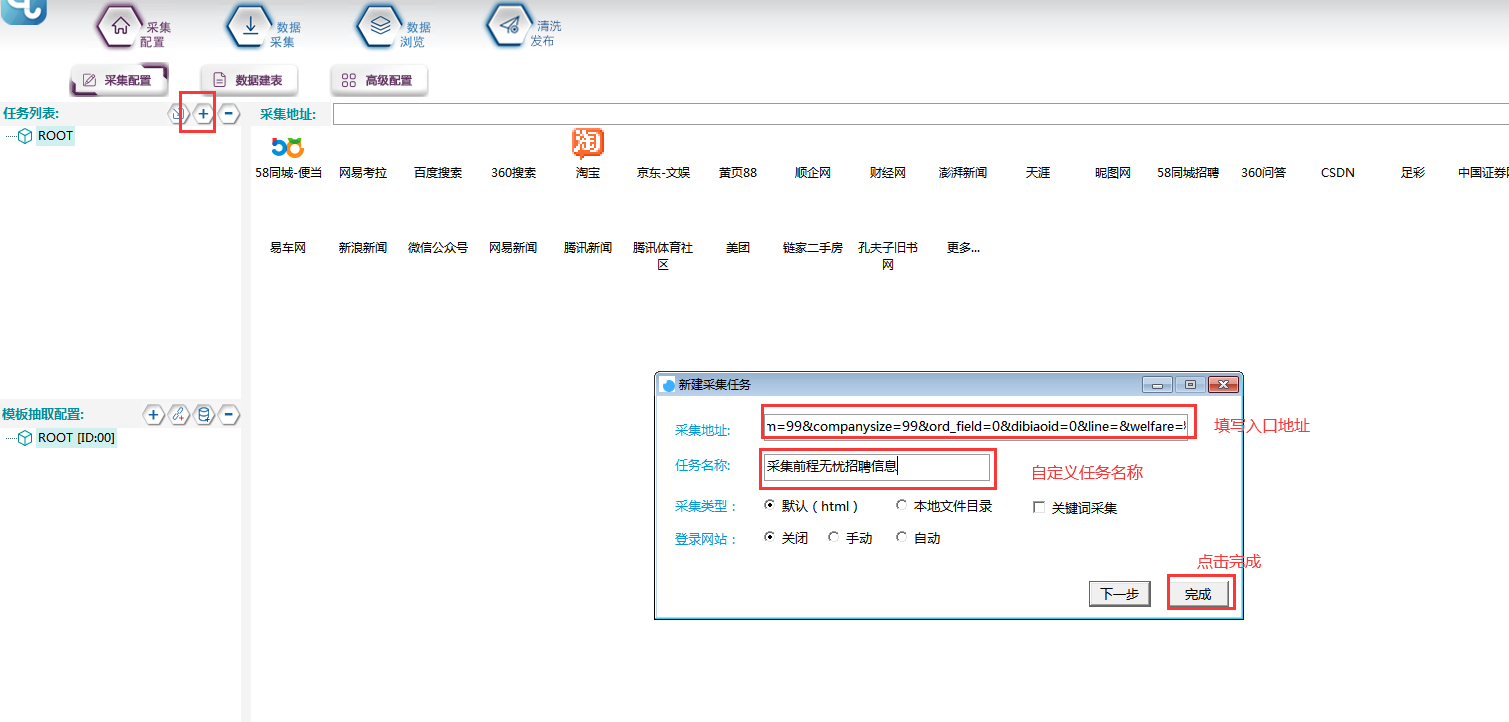
1. 新建采集任务
选择【采集配置】,点击任务列表右上方【+】号可新建采集任务,将采集入口地址填写在【采集地址】框中,【任务名称】自定义即可,点击下一步。
2.获取翻页链接
①在浏览器上观察该页面,发现翻页链接都不一样。

②复制前三页的链接,发现规律如下所示:

③写脚本,拼接链接,具体脚本如下所示:
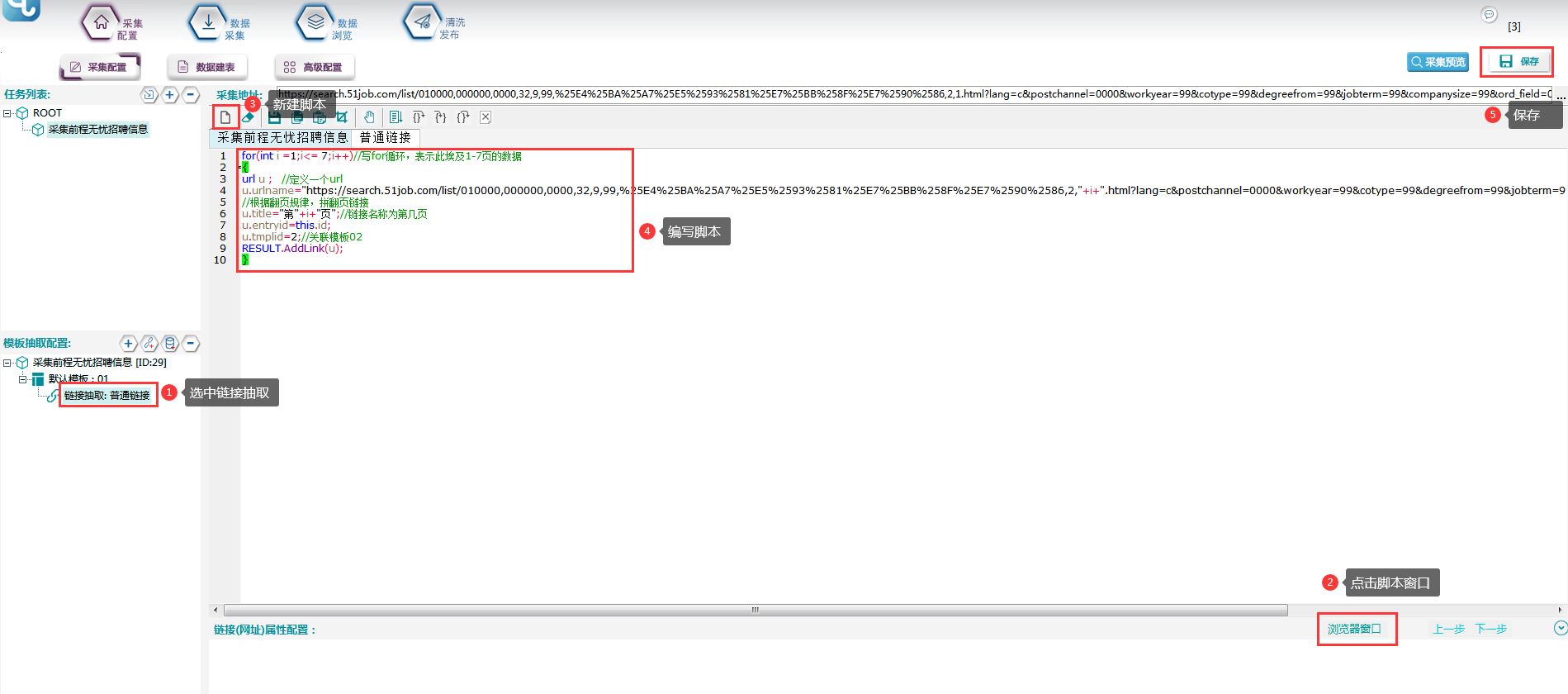
脚本文本:
for(int i =1;i<= 7;i++)
{
url u ;
u.urlname="https://search.51job.com/list/010000,000000,0000,32,9,99,%25E4%25BA%25A7%25E5%2593%2581%25E7%25BB%258F%25E7%2590%2586,2,"+i+".html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=";
u.title="第"+i+"页";//将标题设置为关键词名称
u.entryid=this.id;
u.tmplid=2;
RESULT.AddLink(u);
}⑥采集预览,如下图所示,每日的新闻链接已生成,右键复制任意一条,在浏览器中打开,看是否为正确链接。
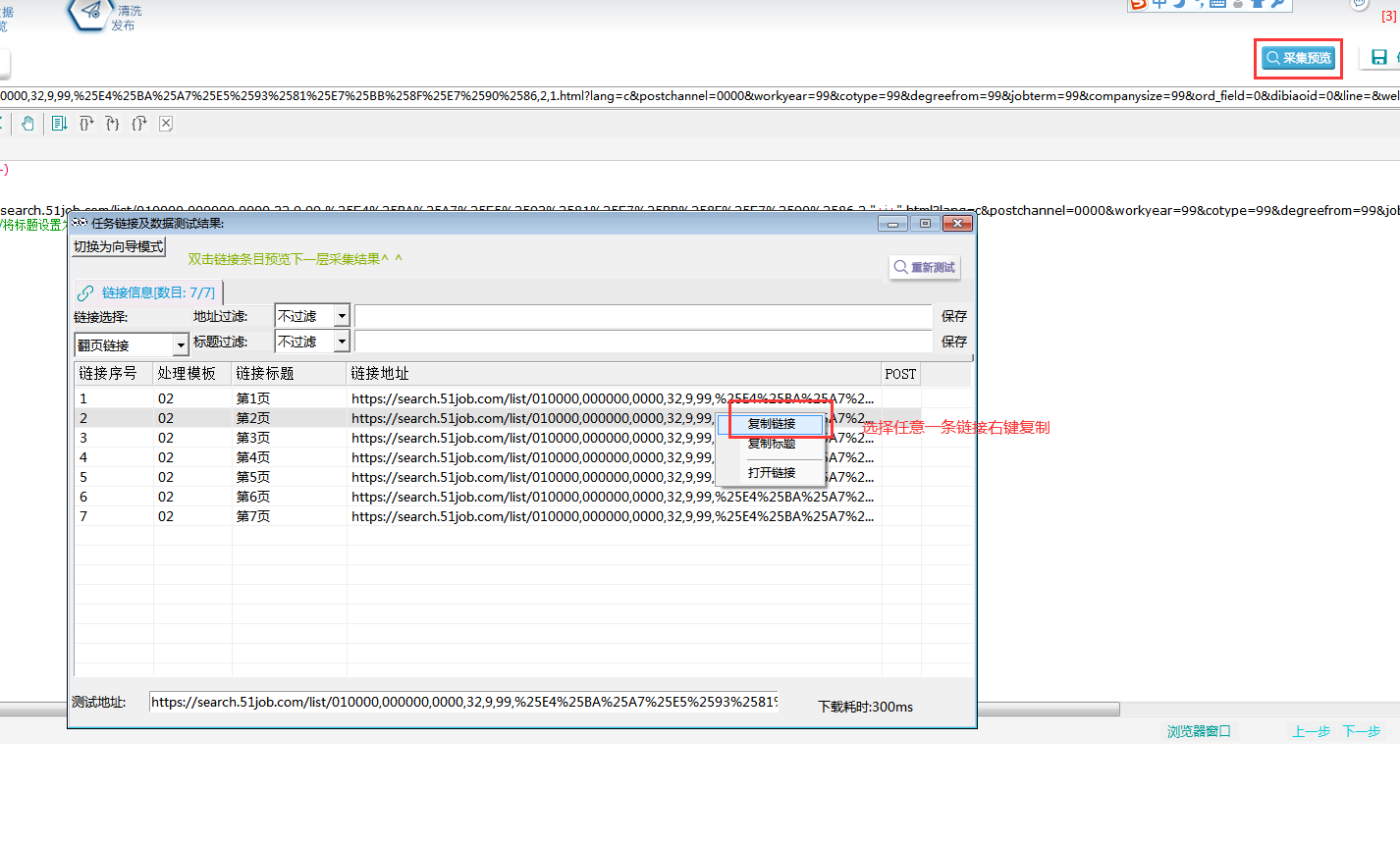
3.获取招聘列表链接
①在列表页单击鼠标右键,选择【查看源文件】,打开页面源码。
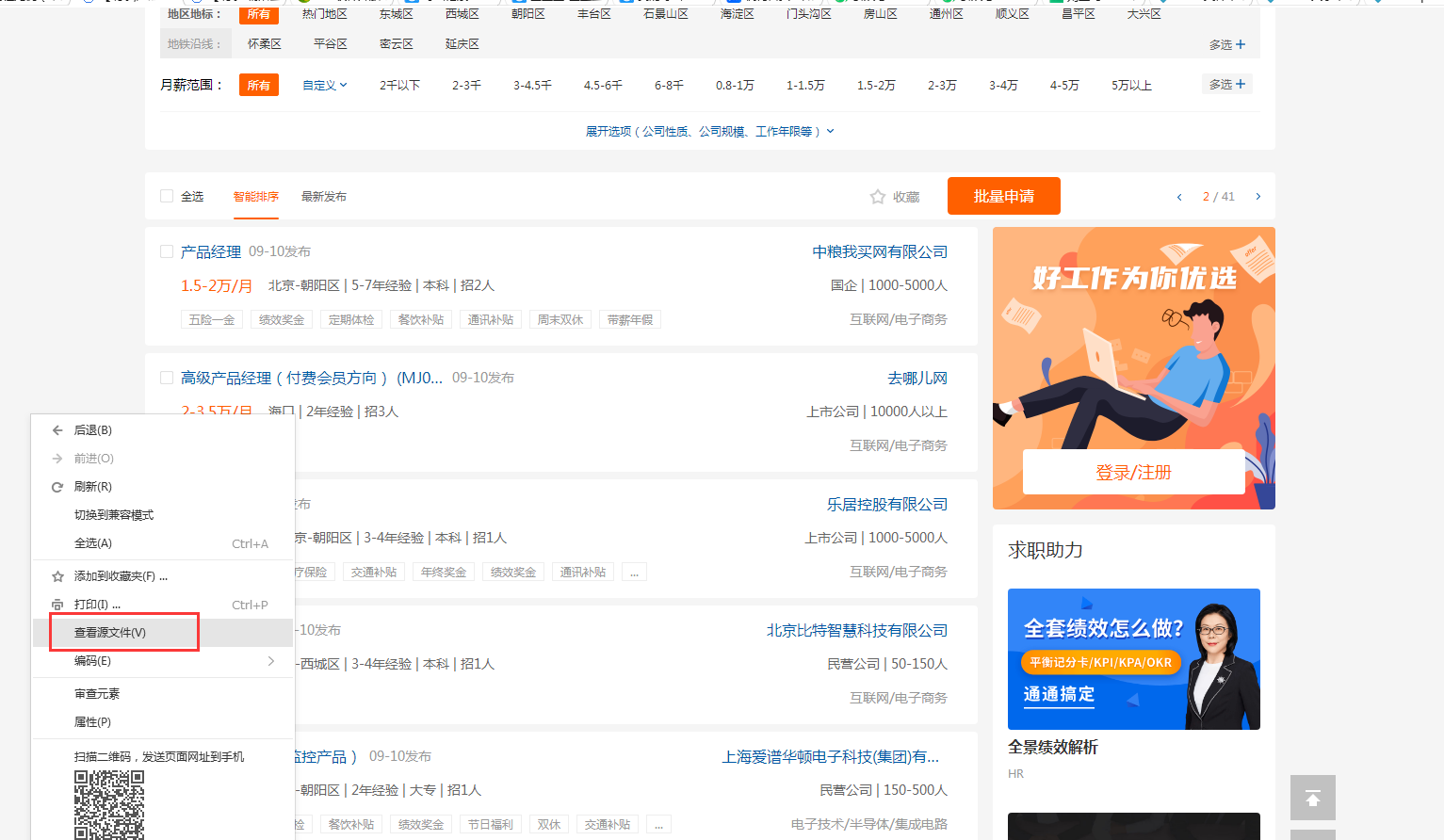
②观察发现,每个招聘信息的链接,均是job_href的属性值。

③将这段js格式化,可更好的查看数据结构。

④观察发现,所有招聘信息的链接,在源码中的js中的engine_jds数组中每个对象中的job_href属性值。
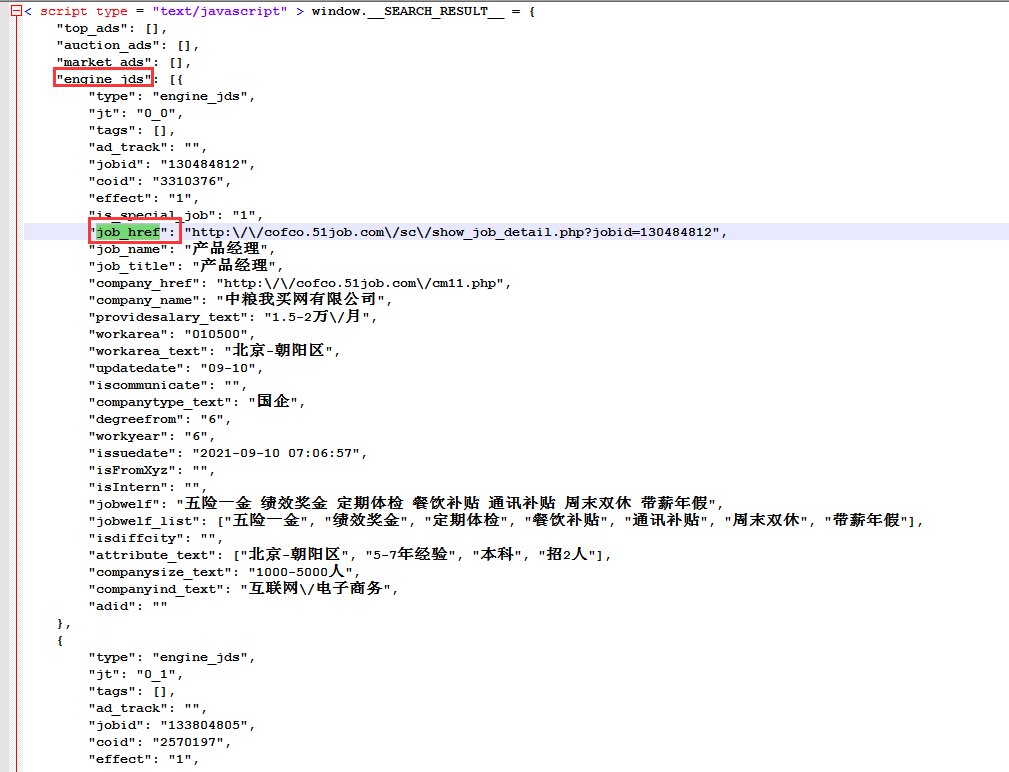
⑤根据以上观察,编写脚本将招聘列表链接抽取出来。具体操作如下:
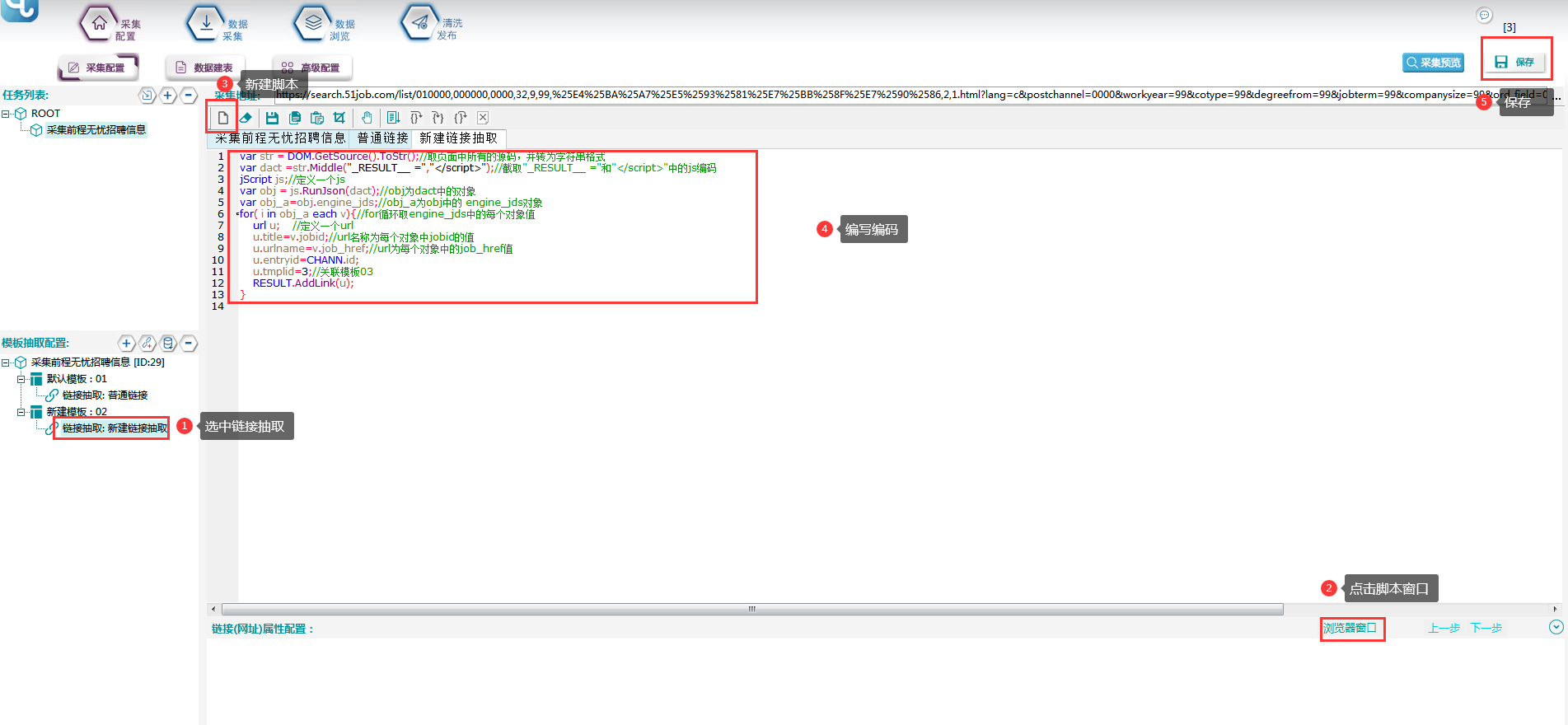
脚本文本为:
var str = DOM.GetSource().ToStr();//取页面中所有的源码,并转为字符串格式
var dact =str.Middle("_RESULT__ =","</script>");//截取"_RESULT__ ="和"</script>"中的js编码
jScript js;//定义一个js
var obj = js.RunJson(dact);//obj为dact中的对象
var obj_a=obj.engine_jds;//obj_a为obj中的 engine_jds对象
for( i in obj_a each v){//for循环取engine_jds中的每个对象值
url u; //定义一个url
u.title=v.jobid;//url名称为每个对象中jobid的值
u.urlname=v.job_href;//url为每个对象中的job_href值
u.entryid=CHANN.id;
u.tmplid=3;//关联模板03
RESULT.AddLink(u);
}
⑥采集预览,如下图所示:
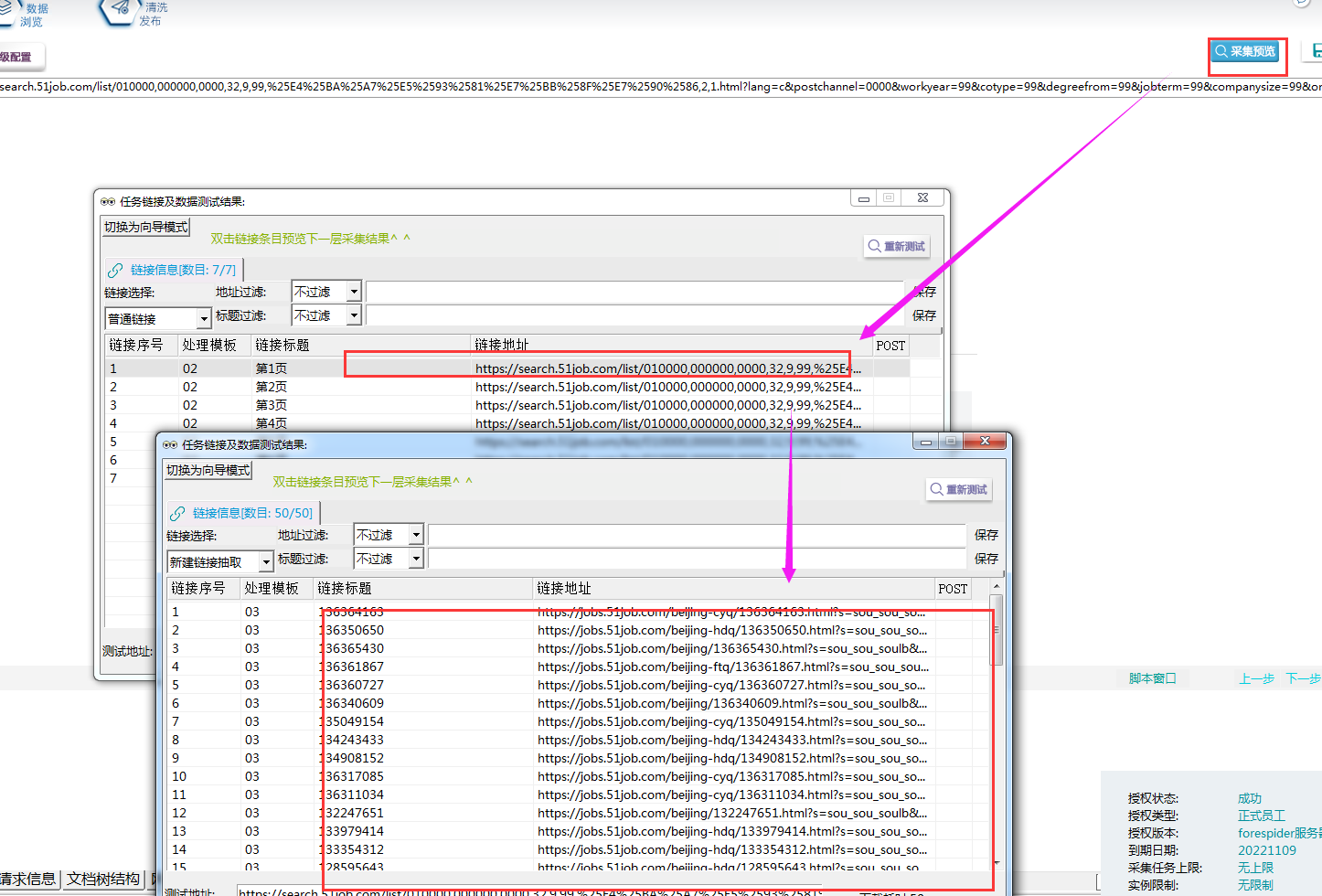
4.抽取招聘数据
①新建模板03,在该模板下新建一个数据抽取。
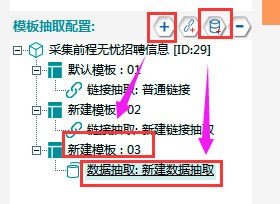
②新建一个数据表单,具体步骤和字段属性如下所示:

③填写示例地址
采集预览,双击进入下一层,复制任意一条招聘链接,复制在示例地址位置:
④设置refer,具体如下图所示:

⑤关联数据表单,如下图所示:
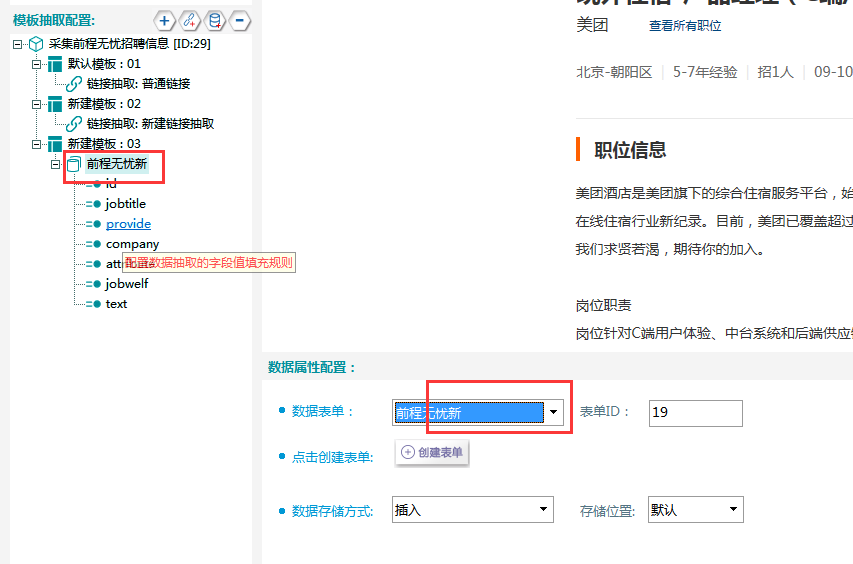
⑥抽取数据采用定位取值法,以jobtitle为例进行演示,具体操作如下图所示:
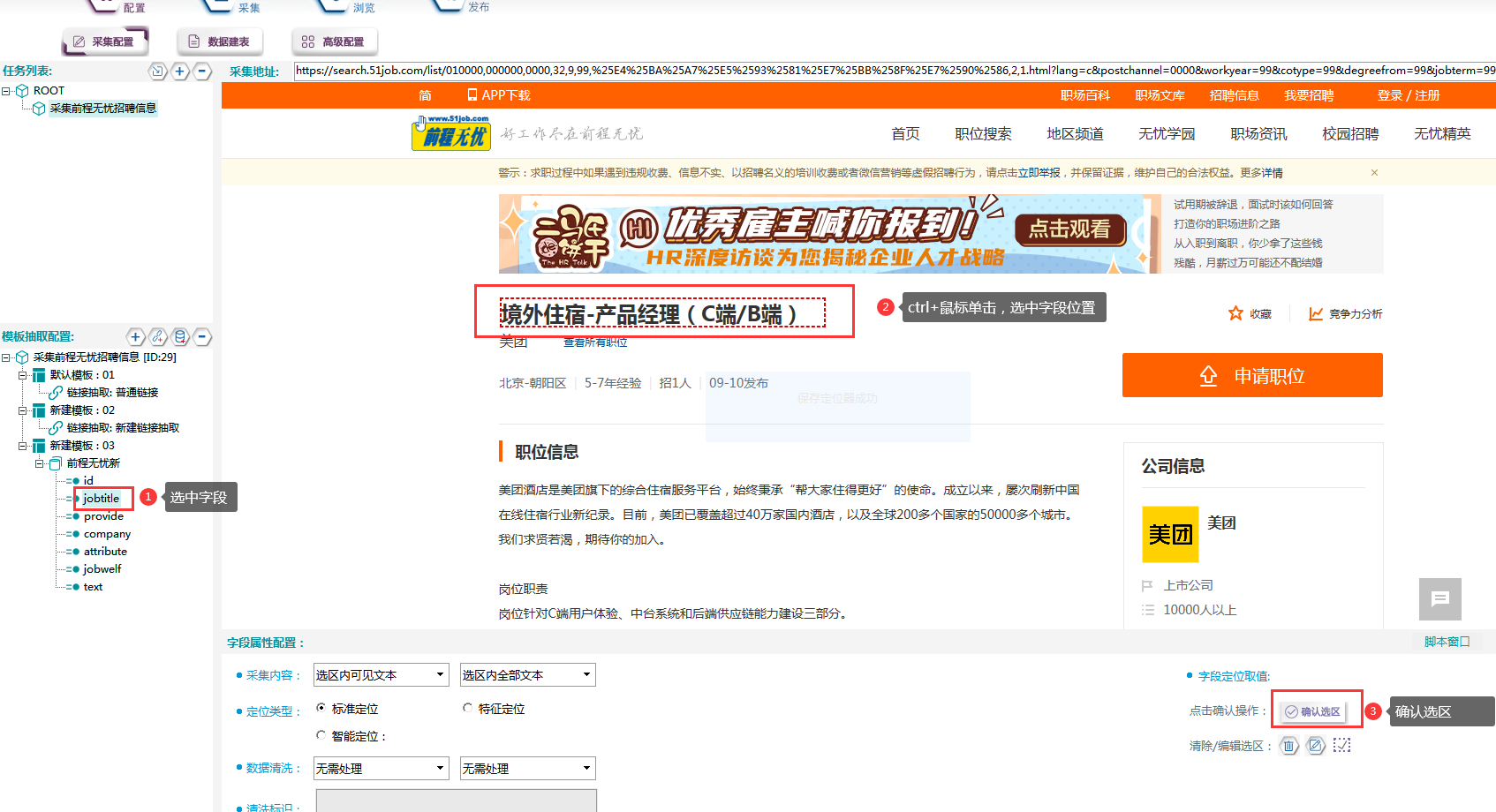
Jobwelf字段:
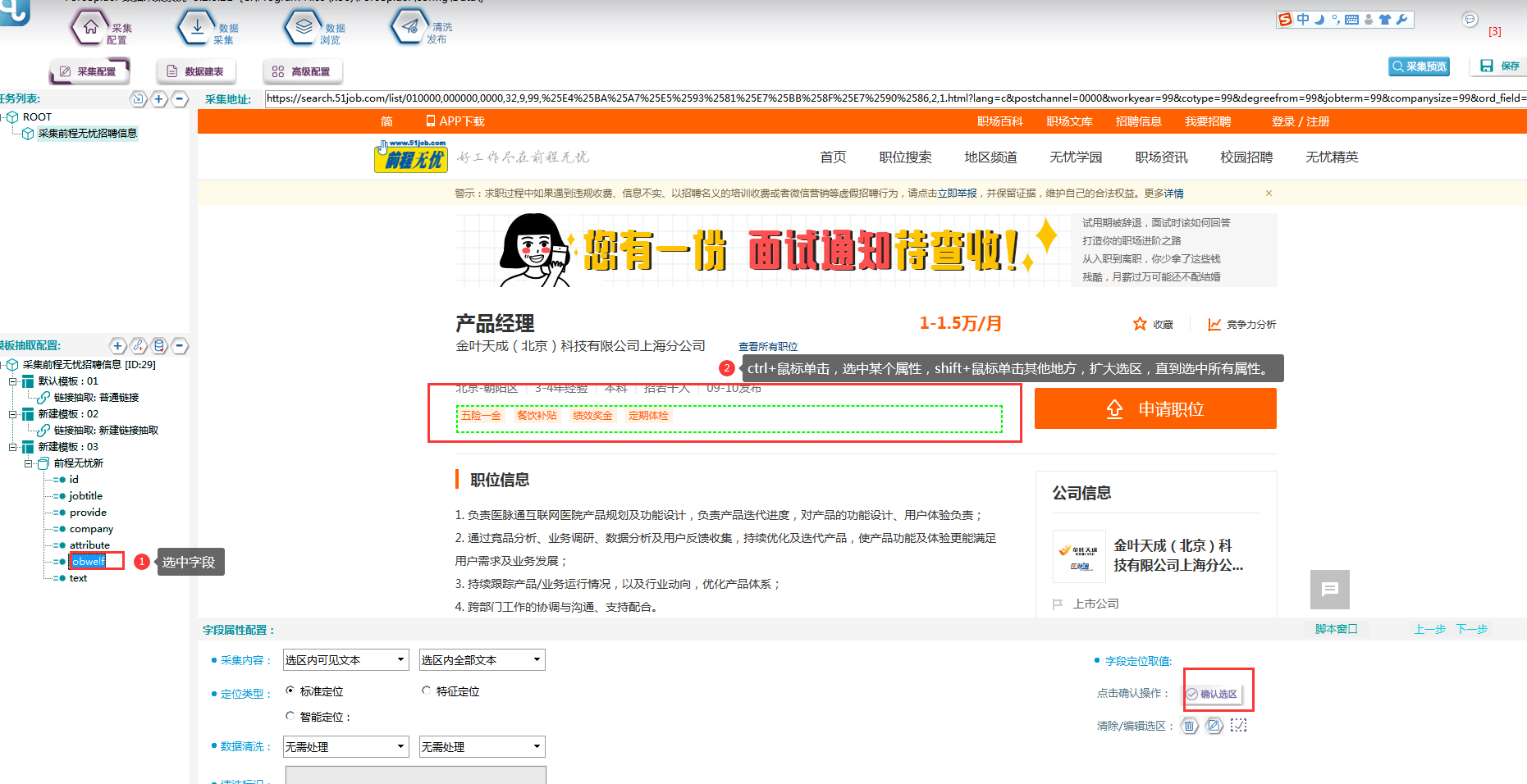
⑦其他字段以此类推,进行定位取值后,点击采集预览,如下图所示:

l 采集步骤
模板配置完成,采集预览没有问题后,可以进行数据采集。
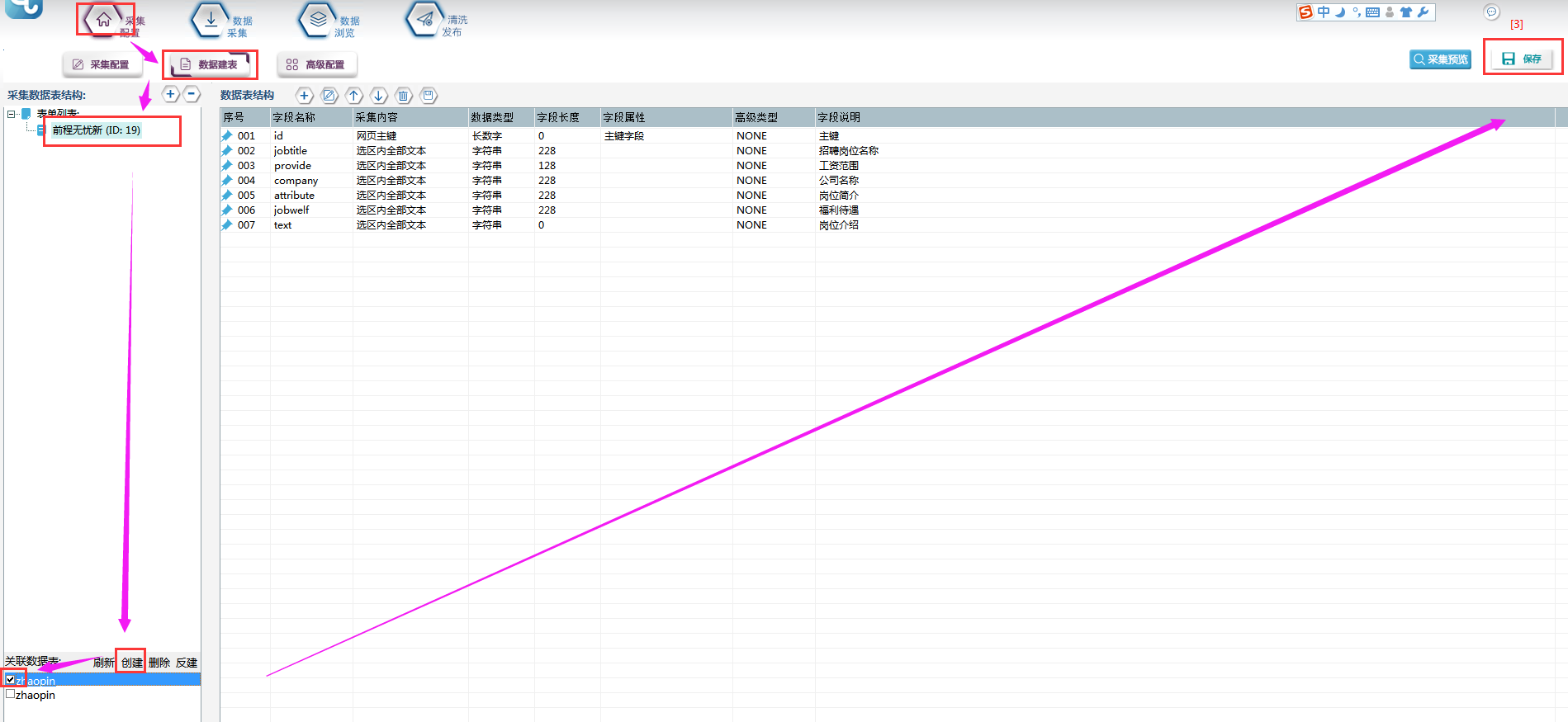
①首先要建立采集数据表:
选择【数据建表】,点击【表单列表】中该模板的表单,在【关联数据表】中选择【创建】,表名称自定义,这里命名为【zhaopin】(注意命名不能用数字和特殊符号),点击【确定】。创建完成,勾选数据表,并点击右上角保存按钮。
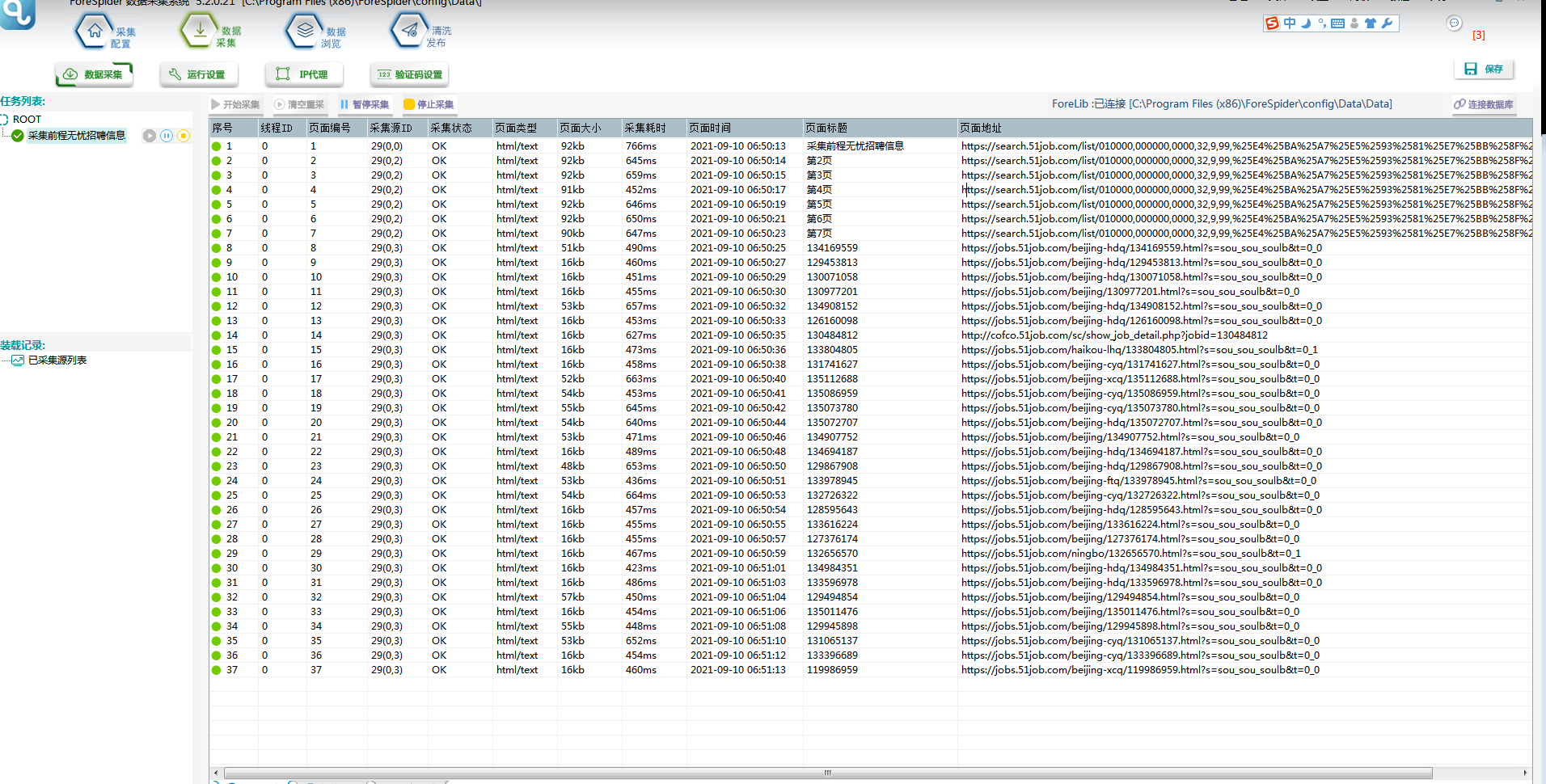
②选择【数据采集】,勾选任务名称,点击【开始采集】,则正式开始采集。

③采集中:
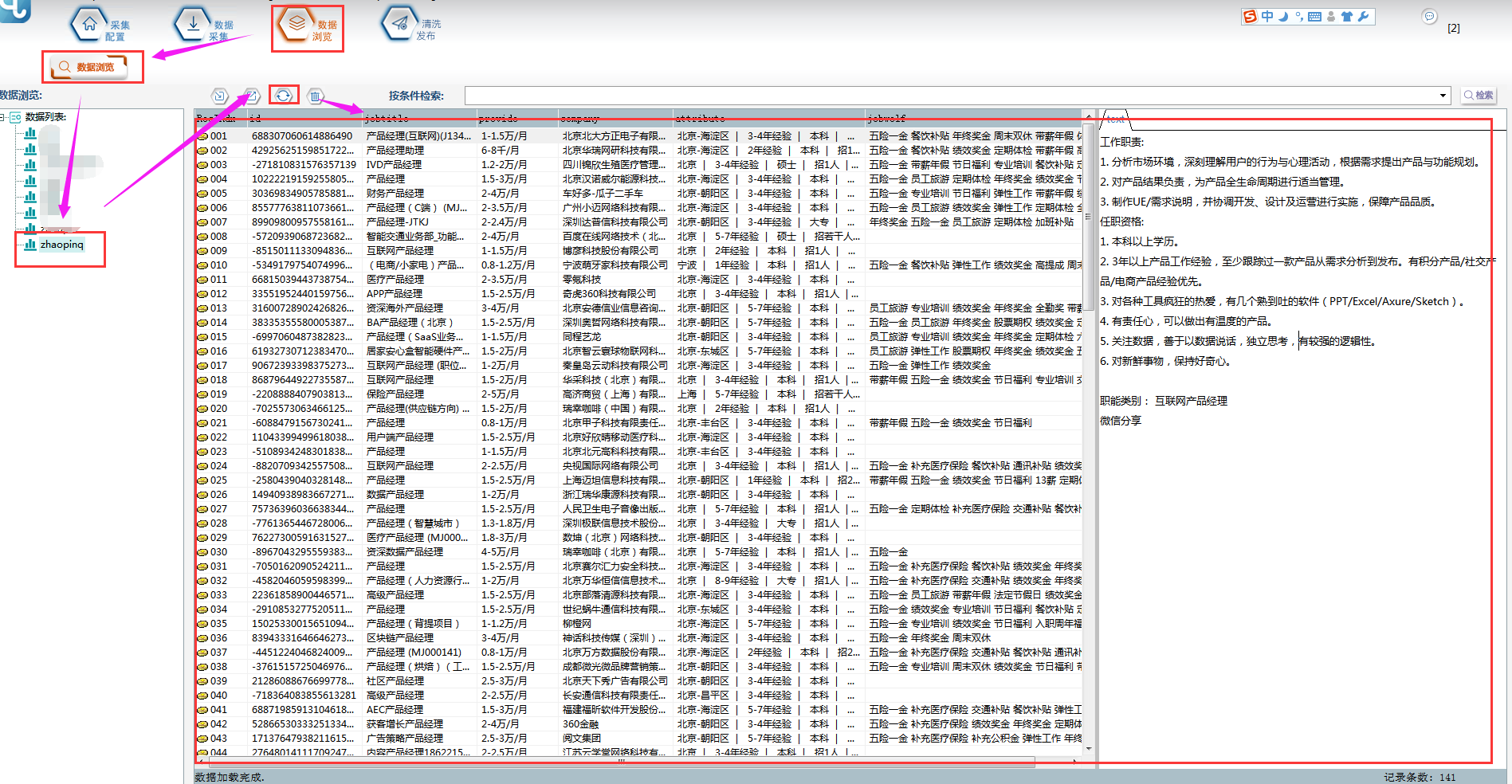
④采集结束后,可以在【数据浏览】中,选择数据表查看采集数据,并可以导出数据。
在采集的过程中,可能会遇到因网站封IP而导致的采集异常情况,建议您购买适量代理IP进行采集。代理IP介绍与设置可参考文章:看完之后,不要再说不懂代理IP了!
*本教程仅供学习交流,严禁用于商业用途!

.png) 大数据引擎
大数据引擎.png) 大数据应用
大数据应用.png) 大数据底层技术
大数据底层技术.png) ForeSpider软件
ForeSpider软件
.png) 采集服务
采集服务.png) 软件学习
软件学习.png) 智能分析
智能分析.png) 特征提取
特征提取.png) 智能计算
智能计算.png) 数据可视化
数据可视化.png) 数据分析应用
数据分析应用.png) 系统集成服务
系统集成服务.png) 代码工具
代码工具.png) 金融方案
金融方案.png) 制造业&物流
制造业&物流.png) 企业数字化
企业数字化.png) 医疗方案
医疗方案.png) 政务方案
政务方案.png) 实时监测
实时监测.png) 智能分析
智能分析.png) 数据智能挖掘
数据智能挖掘.png) 全网自动采集
全网自动采集.png) 场景智慧采集
场景智慧采集.png) 主题识别采集
主题识别采集







 022-2345 2937
022-2345 2937 185 2247 0110
185 2247 0110 business@forenose.com
business@forenose.com









 022-2345 2937
022-2345 2937 185 2247 0110
185 2247 0110 business@forenose.com
business@forenose.com 前嗅大数据
前嗅大数据