字段从网页上取值,有几种情况:
1. 自动取值:有些采集类型可以自动获取网页上的内容。
2. 标准定位:通过在网页上定位选区,获取数据。
3. 特征定位:根据网页文本的特征定位选区,获取数据。
4. 模板取值:部分数据在另一个网页上,想存储在同一张表中。
5. 脚本取值:通过编写脚本获取数据。
一.自动取值的字段类型
当采集内容设置为以下内容时,系统会自动为字段赋值,无需额外操作。
采集内容大类 | 采集内容小类 | 说明 |
可见文本 | 网页内文字文本 | 采集整个页面中所有可见的文字文本。 |
主键 | 网页主键 |
|
自增ID主键 |
|
源码/图片/文件 | 网页全部内容 | 采集网页全部文本,包含html标签等,即整个页面的源代码。 |
网页信息 | 网页地址 | 自动采集网页的URL地址。 |
网页标题 | 采集网页的标题。即网页<title>中的内容。 |
文档数据大小 | 采集对象的质量大小[单位:字节]。 |
文档名称 | 当前文档(文件)的名称 |
文档后缀 | 文档的文件名后缀 |
文档后缀类型 | 文档后缀的枚举类型 |
文档视宽 | 文档的宽[如果是图片数据则为图片的宽] |
文档视高 | 文档的高[如果是图片数据则为图片的高] |
文档层级 | 文档被采集时的链接深度(层级) |
原始网页地址 | 当页面重定向以后,依然保存重定向以前的地址 |
时间信息 | 网页创建时间 | 文档创建或网页发布的时间。 |
网页更新时间 | 文档或网页更新的时间。 |
网页获取时间 | ForeSpider采集该网页的时间。 |
当前系统时间 | 数据采集入库的时间。 |
采集任务信息 | 任务ID | 采集当前任务的ID。 |
任务名称 | 采集当前任务的名称。 |
二.标准定位取值
1.标准定位含义
通过在内置浏览器上,定位有所需数据的区域,为字段取值。大多数情况都选择“标准定位”。
2.定位方法
①选择:按Ctrl点击页面上相应数据的区域。
②扩大选区:按Shift再次点击页面相应区域。
③确认选区:点击“确认选区”按钮,选区生效。
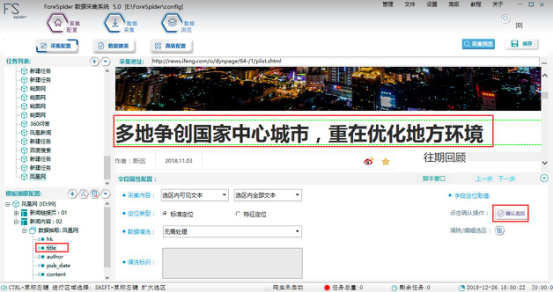
【标准定位】
三.特征定位取值
1.特征定位含义
当所需数据在不同网页的位置不固定,且数据前后具有特征性文字时,用标准定位容易错位,需要使用特征定位。
举例:对于字符串“作者:***”,采集作者名称时,可用“作者:”作为特征来定位。
2.操作方法
①选择:按Ctrl点击页面上所需数据的区域。
②识别特征:点击“识别特征”,出现红框,再次点击,红框移动到特征字符串时确认。
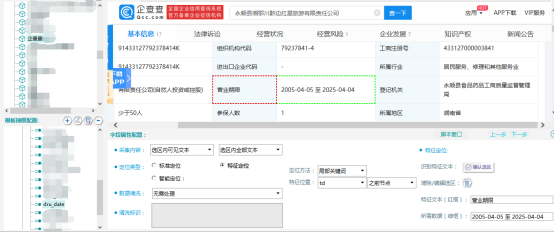
【特征定位】
③点击“确认选区”按钮,选区生效。
3.特征定位的类型
特征定位分为四种方式:
(1)局部关键词
当页面的数据前有特定的关键词,而各个页面的表格内容、各行次序、行数又各不相同时,采用标准定位的方式就会错乱。可以根据表头特征,采集表格后的数据。与全文关键词的区别是,局部关键词只在选定区域的附近采集。
(2)全文关键词
根据选定的特征关键词,在全页面采集该特征关键词前后对应的数据,如果出现多个特征关键词,以第一个为主。如果想采集多个的话,可以设定多值。>>查看多值的配置方式
(3)大文本
选定大文本区域后,自动识别各页面的大文本,相比标准定位更加精确。
(4)特殊标签
采集页面中只出现一次的特殊标签,如标题的<h1>标签等。
四.模板取值
当前字段的取值数据不在当前页面,在另一页面时,需要将该字段的取值类型选择为“模板取值”。用另外一个模板的内容来填充该字段的值。(注意:模板取值的id不能填自身)
以某网站为例,从“联系我们”界面进行字段定位取值获取数据,但content字段需在“公司介绍”界面进行取值。
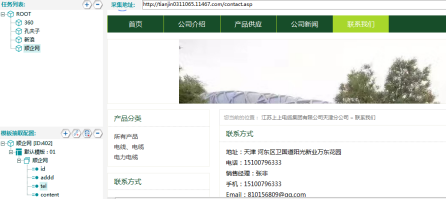
【模板取值示例】
①添加字段时,将content字段配置为模板取值。

【模板取值字段设置】
②新建模板,示例地址为“公司介绍”的地址。
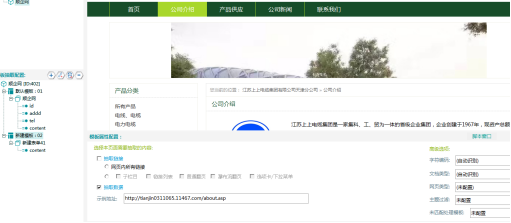
【新建模板】
③新建表单和字段,字段名为content与上个模板中字段名相同。
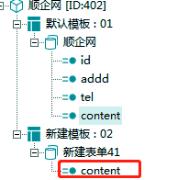
【新建表单字段】
④进行字段定位取值后,右键点击进行模板预览。
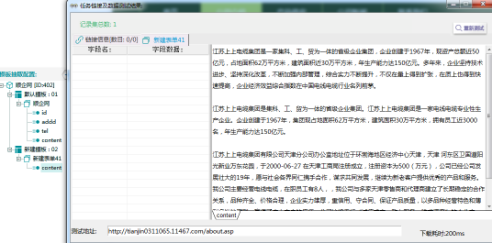
【模板预览1】
⑤由于页面上是个<a>链接,属性为href,取值的关联模板的ID为2。因此,在此处填写“href=[2]”,完成了该字段的配置后确认“公司介绍”页面的选区。
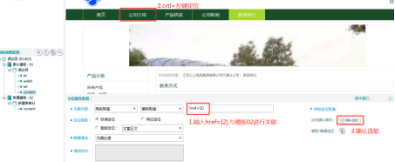
【模板取值配置】
⑥进行模板预览。
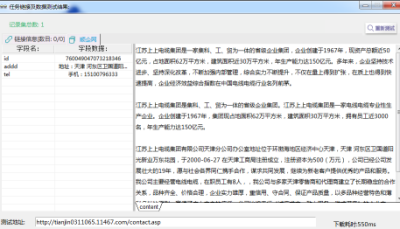
【模板预览2】

.png) 大数据引擎
大数据引擎.png) 大数据应用
大数据应用.png) 大数据底层技术
大数据底层技术.png) ForeSpider软件
ForeSpider软件
.png) 采集服务
采集服务.png) 软件学习
软件学习.png) 智能分析
智能分析.png) 特征提取
特征提取.png) 智能计算
智能计算.png) 数据可视化
数据可视化.png) 数据分析应用
数据分析应用.png) 系统集成服务
系统集成服务.png) 代码工具
代码工具.png) 金融方案
金融方案.png) 制造业&物流
制造业&物流.png) 企业数字化
企业数字化.png) 医疗方案
医疗方案.png) 政务方案
政务方案.png) 实时监测
实时监测.png) 智能分析
智能分析.png) 数据智能挖掘
数据智能挖掘.png) 全网自动采集
全网自动采集.png) 场景智慧采集
场景智慧采集.png) 主题识别采集
主题识别采集







 022-2345 2937
022-2345 2937 185 2247 0110
185 2247 0110 business@forenose.com
business@forenose.com









 022-2345 2937
022-2345 2937 185 2247 0110
185 2247 0110 business@forenose.com
business@forenose.com 前嗅大数据
前嗅大数据