【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
背景
最近有项目中要用到nacos,因此就打算在本地先装个nacos玩玩。怎么装呢?当然使用docker了。既方便又简单。说实话自从装了docker之后,我这用了3年时间的ThinkPad着实有点卡。因此也有好长时间没运行过docker了。如果你还不会在windows下安装docker,请看以下两篇文章: windows下安装运行docker windows安装mysql
问题
当我启动docker后,打开cmd窗口,输入docker images。奇怪的事情发生了,
没有任何镜像,这不应该啊。以前pull过两个镜像,一个是hello-world,另一个是mysql:8.0。 可能是镜像路径错了,打开原来的文章,看了看配置, 然后根据以前设置的settings修改。
重启后镜像回来了。
然后一顿操作,nacos装好了,完事。
第二天继续打开docker,运行我的nacos,准备继续研究一波nacos。
怪事请!我的mysql 和 nacos 的镜像又没了,只剩下一个hello-world。
继续打开settings->daemon,发现没什么变化,配置文件也都跟昨天的一样。
解决
仔细看了看,发现experimental这个参数的值变成false了。
难道是这个参数的问题?改成true试试。
你还别说,真的成功了。镜像又回来了。
什么情况?
网上搜了一下午也没找到相关的资料。
只能去官网查看一波了。
https://docs.docker.com/engine/reference/commandline/dockerd/#daemon-configuration-file
在上面找到了一段描述: The --metrics-addr option takes a tcp address to serve the metrics API. This feature is still experimental, therefore, the daemon must be running in experimental mode for this feature to work.
意思大概是说: --metrics-addr需要一个tcp地址来运行metrics API。 此功能仍处于试验阶段,因此,the daemon必须在试验模式下运行才能起作用。
关于这个--metrics-addr也有一段相关解释: To serve the metrics API on localhost:9323 you would specify --metrics-addr 127.0.0.1:9323, allowing you to make requests on the API at 127.0.0.1:9323/metrics to receive metrics in the prometheus format.
我觉得应该是docker容器内的镜像启动后默认使用localhost去访问的,如果你想使用ip去访问,则需要使用这个--metrics-addr。
一般情况下,我们肯定不仅仅是在本地使用localhost去访问服务的,而是在其他地方使用ip来访问这个服务。
docker研究尚浅,仅可做为参考,如果有研究过docker的大佬,可以留言交流。
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
查看无线网卡工作模式
查看无线网卡工作模式, 一般情况下,无线网卡有四种工作模式,分别是Managed模式、Master模式、Ad hoc模式和Monitor模式。大学霸IT达人 查看无线网卡工作模式。 默认情况下,无线网卡工作模式为Managed,可以用来连接到无线网络。当用户实施无线渗透时,通常需要将无线网卡设置为监听模式(Monitor)。一些用户设置监听模式后,不确定是否设置成功。此时,可以使用iwconfig命令查看。例如,当前无线网卡工作为Managed(管理模式)。显示效果如下所示:
C:\root> iwconfig
eth0 no wireless extensions.
wlan0 IEEE 802.11 ESSID:off/any
Mode:Managed Access Point: Not-Associated Tx-Power=20 dBm
Retry short long limit:2 RTS thr:off Fragment thr:off
Encryption key:off
Power Management:off
lo no wireless extensions.
从输出的信息可以看到,Mode为Managed。由此可以说明,工作为Managed模式。
当无线网卡工作为Monitor(监听模式)。效果如下所示:
C:\root> iwconfig
wlan0mon IEEE 802.11 Mode:Monitor Frequency:2.457 GHz Tx-Power=20 dBm
Retry short long limit:2 RTS thr:off Fragment thr:off
Power Management:off
eth0 no wireless extensions.
从输出的信息可以看到,Mode为Monitor。由此可以说明,无线网卡工作为Monitor模式。
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
集群
我们的项目如果跑在一台机器上,如果这台机器出现故障的话,或者用户请求量比较高,一台机器支撑不住的话。我们的网站可能就访问不了。
那怎么解决呢?
就需要使用多台机器,部署一样的程序,让几个机器同时的运行我们的网站。那怎么怎么分发请求的我们的所有机器上。
所以负载均衡的概念就出现了。
负载均衡
负载均衡是指基于反向代理能将现在所有的请求根据指定的策略算法,分发到不同的服务器上。常用实现负载均衡的可以用nginx,lvs。
但是现在也有个问题,如果负载均衡服务器出现问题了怎么办?
所以冗余的概念就出现了。
冗余
冗余其实就是两个或者多台服务器 一个主服务器,一个从服务器。
假设一个主服务器的负载均衡服务器出现了问题,从服务器能够替代主服务器来继续负载均衡。
实现的方式就是使用keepalive来抢占虚拟主机。
分布式
分布式其实就是将一个大项目的拆分出来,单独运行。
举个上面的例子。
假设我们的访问量特别大,我们就可以做成分布式,跟cdn一样的机制。
在北京,杭州,深圳三个地方都搭建一个一模一样的集群。离北京近的用户就访问北京的集群,离深圳近的就访问深圳这边的集群。这样就将我们网战给拆分3个区域了,各自独立。
再举个例子比如我们redis分布式。
redis分布式是将redis中的数据分布到不同的服务器上面,每台服务器存储不同的内容,而mysql集群是每台服务器都放着一样的数据。这也就理解了分布式和集群的概念。
MySQL 主从
mysql master服务器会把sql操作日志写入到bin.log 日志里 slave服务器会去读master的bin.log 日志,然后执行sql语句。
主从有以下几个问题:
master服务器能写又能读,slave却只能写。
slave读取的数据还没有写入,这样该怎么解决呢? 假如缓存,从缓存中读取。强制从master读取。使用pxc集群,任何一个节点都是可读可写的,读写强一致性。
如何解决数据不一致?
在config/database.php mysql配置块中将sticky设置为true
sticky 是一个 可选值,它可用于立即读取在当前请求周期内已写入数据库的记录。
若 sticky 选项被启用,并且当前请求周期内执行过 「写」 操作,那么任何 「读」 操作都将使用 「写」 连接。
这样可确保同一个请求周期内写入的数据可以被立即读取到,从而避免主从延迟导致数据不一致的问题。
不过是否启用它,取决于应用程序的需求。
同步代码到多台服务器
Laravel为我们提供了扩展包laravel/envoy,它为定义远程服务器的日常任务,提供了一套简洁、轻量的语法。
Blade 风格语法即可实现部署任务的配置、Artisan 命令的执行等。
composer global require laravel/envoy
Envoy 任务都应在项目根目录下的 Envoy.blade.php 中定义。
写入一下内容
@servers(['web-1' => '192.168.1.1', 'web-2' => '192.168.1.2']) @task('deploy', ['on' => ['web-1', 'web-2']]) cd site git pull origin {{ $branch }} composer update php artisan migrate @endtask
以上代码意思就是在命令行envoy run deploy时候,我们会ssh到会web-1,web-2 执行
cd site git pull origin {{ $branch }} php artisan migrate 也可以自己手写一个Linux cron来实现代码同步
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
1、Docker CE 镜像源站
使用官方安装脚本自动安装 1 curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun
2、Ubuntu 14.04 16.04 (使用apt-get进行安装) # step 1: 安装必要的一些系统工具 sudo apt-get update sudo apt-get -y install apt-transport-https ca-certificates curl software-properties-common # step 2: 安装GPG证书 curl -fsSL http://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo apt-key add - # Step 3: 写入软件源信息 sudo add-apt-repository "deb [arch=amd64] http://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable" # Step 4: 更新并安装 Docker-CE sudo apt-get -y update sudo apt-get -y install docker-ce # 安装指定版本的Docker-CE: # Step 1: 查找Docker-CE的版本: # apt-cache madison docker-ce # docker-ce | 17.03.1~ce-0~ubuntu-xenial | http://mirrors.aliyun.com/docker-ce/linux/ubuntu xenial/stable amd64 Packages # docker-ce | 17.03.0~ce-0~ubuntu-xenial | http://mirrors.aliyun.com/docker-ce/linux/ubuntu xenial/stable amd64 Packages # Step 2: 安装指定版本的Docker-CE: (VERSION 例如上面的 17.03.1~ce-0~ubuntu-xenial) # sudo apt-get -y install docker-ce=[VERSION]
3、CentOS 7 (使用yum进行安装) # step 1: 安装必要的一些系统工具 sudo yum install -y yum-utils device-mapper-persistent-data lvm2 # Step 2: 添加软件源信息 sudo yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo # Step 3: 更新并安装 Docker-CE sudo yum makecache fast sudo yum -y install docker-ce # Step 4: 开启Docker服务 sudo service docker start # 注意: # 官方软件源默认启用了最新的软件,您可以通过编辑软件源的方式获取各个版本的软件包。例如官方并没有将测试版本的软件源置为可用,你可以通过以下方式开启。同理可以开启各种测试版本等。 # vim /etc/yum.repos.d/docker-ce.repo # 将 [docker-ce-test] 下方的 enabled=0 修改为 enabled=1 # # 安装指定版本的Docker-CE: # Step 1: 安装指定版本的docker-ce-selinux # yum install https://download.docker.com/linux/centos/7/x86_64/stable/Packages/docker-ce-selinux-17.03.2.ce-1.el7.centos.noarch.rpm # Step 2: 查找Docker-CE的版本: # yum list docker-ce.x86_64 --showduplicates | sort -r # Loading mirror speeds from cached hostfile # Loaded plugins: branch, fastestmirror, langpacks # docker-ce.x86_64 17.03.1.ce-1.el7.centos docker-ce-stable # docker-ce.x86_64 17.03.1.ce-1.el7.centos @docker-ce-stable # docker-ce.x86_64 17.03.0.ce-1.el7.centos docker-ce-stable # Available Packages # Step 3: 安装指定版本的Docker-CE: (VERSION 例如上面的 17.03.0.ce.1-1.el7.centos) # sudo yum -y install docker-ce-[VERSION]
4、Centos7 rpm包安装 如果您无法使用Docker的仓库来安装Docker,则可以下载该 .rpm文件以供手动安装。每次要升级Docker时,都需要下载一个新文件。 1、访问 https://download.docker.com/linux/centos/7/x86_64/stable/Packages/ 并下载.rpm您想要安装的Docker版本的文件。 2、安装Docker CE,安装docker之前需要安装docker-ce-selinux 将下面的路径更改为您下载Docker软件包的路径。 yum install docker-ce-selinux-***.ce-1.el7.centos.noarch.rpm yum install docker-ce-***.ce-1.el7.centos.x86_64.rpm 3、启动Docker。 systemctl start docker
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
历史原因:刚进公司时候,gitlab工具由于创建者已经离职,这个工具也就没有人维护了!主要是当时那个人是编译安装的,升级不方便!另外由于前端开发需要用到gitlab的page功能,所以我当时就自告奋勇的接了这个项目!
公司的大领导运维分配了一个虚拟机,使用centos7的,没办法,我个人比价喜欢debian的,哀求过,不过人家就是不鸟我,谁叫centos是服务器运维的宠儿咩.........原编译的版本是8.8, 我在最开始安装的版本是11.3, 后来升级过一次到了11.8!
转入正题:
系统:CentOS7
安装途径:按照官网的源安装
原版本:gitlab 11.8.0
数据库:postgresql 9.6
请参照: https://about.gitlab.com/install/#centos-7或者 https://about.gitlab.com/install/
查看gitlab系统所有版本(查最新版)
https://packages.gitlab.com/gitlab/ 或者通过 yum update查看有没有显示更新!
备份系统(数据库备份): gitlab-rake gitlab:backup:create #默认目录/var/opt/gitlab/backups
以及备份代码库(默认放在/var/opt/gitlab/data/git-data/repositories目录下) tar -zcpvf repositories.tgz /var/opt/gitlab/data/git-data/repositories
升级安装顺序 11.8.0---11.11.8---12.0.0--12.9.2(目前最新) yum -y install gitlab-ce-11.11.8-ce.0.el7.x86_64
升级到11.11.8版本之后,需要更新数据库,因为新版要求数据版本postgresql 10.7
因此需要单独升级 gitlab-ctl pg_upgrade
然后分别执行以下两个升级 yum -y install gitlab-ce-12.0.0-ce.0.el7.x86_64 yum -y install gitlab-ce-12.9.2-ce.0.el7.x86_64
然后就可以了
相对简单
Reference:
https://packages.gitlab.com/gitlab/
https://blog.csdn.net/julywind1/article/details/102740693
https://blog.csdn.net/love8753/article/details/88557036
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
下一篇:Elasticsearch - Kibana安装和简单使用
Head 插件
Head 相当于Elasticsearch的一个客户端
Github下载地址
安装 grunt(cmd 进入安装node.js的路径) npm install -g grunt -cli
安装pathomjs npm install
在你解压head的目录下运行(不要放置在elasticsearch目录下)
根目录下Gruntfile.js可以修改启动端口 grunt server
修改 elasticsearch 配置文件(路径:ES安装目录/config/elasticsearch.yml) http.cors.enabled: true http.cors.allow-origin: "*"
用 head 测试访问 elasticsearch( http://localhost:8084/head/ )
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
这篇文章,我们一起来到 Linux 的诡异的一面……
你知道吗?在我们日常使用的 Unix(和 Linux )及其各种各样的分支系统中,存在着一些诡异的命令或进程,它们让人毛骨悚然,有些确实是有害,但也有些却是有益的。下面就来简单介绍一下这些家伙吧。
1. daemon
daemon 有一个很高大上的中文名字,叫 守护进程 。
有句话是这么说的,如果 Unix 中没有了守护进程,那么 Unix 就不会是相同的。
它很有个性,是一个运行在后台且不受终端控制的进程,其大多数都是随着系统启动而启动,无特殊情况下会一直保持运行直到系统关闭。
它的存在为我们用户和系统本身提供有用的服务。常见的有 httpd,mysqld,syslogd 等,一般守护程序名称会以 d 结尾。 2020 精选 阿里/腾讯等一线大厂 面试、简历、进阶、电子书 公众号「 良许Linux 」后台回复「 资料 」免费获取
2. zombie
zombie ,僵尸?什么鬼?听着就让人害怕。
不过,它在 Linux 中指的是当一个进程被杀死后,其实它并不会马上消失,而是变成了 zombie ,即僵尸进程,然后等待其父进程搜集完它的信息才会被清除。
一般这种搜集信息的过程会很快完成,但有时它的父进程很忙,该僵尸进程就会一直呆在我们的系统中。
系统运行过程中时不时地会产生一些僵尸进程,我们无法直接杀死它们,因为它们已经死了,我们只能采取别的手段,比如说杀死它的父进程,然后由 init 来回收这个僵尸进程。
僵尸进程的出现通常表示产生它的进程除了问题,而且它会消耗资源,要防止它的出现。
3. kill
kill ,一个冷酷无情的单词。
顾名思义,kill 是一个用于杀死进程的命令,其使用方法简单粗暴。当你发现一个占用太多内存或者 CPU 资源的进程并造成了负面影响时,建议您可以直接用 kill 干掉它。
若你遇到僵尸进程杀不掉?别慌,去找它的父进程吧,按上面提到的方法来处理。
4. cat
cat ,猫?这又是什么奇怪的东西?Linux中除了僵尸还有猫?
其实,cat 命令是 concatenate 的简写,也就是连接的意思,这么解释你就懂了。
它的作用是组合文件。另外,你甚至可以用这个方便的命令来查看文件的内容。
5. tail
tail ,尾巴。这个怪怪的命令解释起来就比较容易了。
当你想要查看文件的最后 n 行时,使用 tail 命令就很方便了。
另外,当你想要监控文件时,你也可以用它。比如观察日志文件,tail 命令会显示尾部的内容并且可以实时更新,是不是很厉害呢? 2020 精选 阿里/腾讯等一线大厂 面试、简历、进阶、电子书 公众号「 良许Linux 」后台回复「 资料 」免费获取
6. which
which ,别看了前面几个诡异的命令就和 witch(女巫)搞混了。它不是那种童话中阴森恶毒的女巫,它是 which,是负责打印传递给它的任何命令相关联的文件的位置的家伙。
例如,我们想要获取 Python 的位置,我们就可以用 which python ,它就会在你的系统上打印每个版本的 Python 的位置。
7. crypt
crypt ,地下室,这个命令也很好懂。
当你想要保管好自己的东西不被别人知道,放到地下室锁起来是一个很好的办法。
crypt 在 Linux 中的含义是加密,现在被称为 mcrypt ,当你想要对文件进行加密而不被别人读取,这个命令会很方便。与大多数 Linux 命令一样,您可以单独使用 crypt ,也可以在系统脚本中使用。 2020 精选 阿里/腾讯等一线大厂 面试、简历、进阶、电子书 公众号「 良许Linux 」后台回复「 资料 」免费获取
8. shred
shred ,切碎。我想你看到这里已经对这些怪异的词语见怪不怪了。
它是个非常狠的家伙,作用是粉碎文件。当我们想要删除文件,我们会用 rm 命令,但这是有手段进行恢复的,那我们不想让别人恢复怎么办?没错,sherd 的作用就此。shred 能多次覆盖文件以前占用的空间。所以说,用这个命令一点要做好心理准备,因为神仙难救。
看完的都是真爱,点个赞再走呗?您的「三连」就是良许持续创作的最大动力! 关注 原创 公众号「 良许Linux 」,第一时间获取最新Linux干货! 公众号后台回复【资料】【面试】【简历】获取精选一线大厂面试、自我提升、简历等资料。 关注我的博客: lxlinux.net
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
| 在本篇文章里小编给各位分享的是关于nginx关闭/重启/启动的操作方法,有兴趣的朋友们可以学习参考下。 |
|---|
关闭 service nginx stop systemctl stop nginx
启动 service nginx start systemctl start nginx
重启 service nginx reload systemctl restart nginx
随系统启动自动运行 systemctl enable nginx
禁止随系统启动自动运行 systemctl disable nginx
知识点扩展: 首先利用配置文件启动nginx 命令 : nginx -c /usr/local/nginx/conf/nginx.conf 重启服务: service nginx restart 快速停止或关闭Nginx:nginx -s stop 正常停止或关闭Nginx:nginx -s quit 配置文件修改重装载 命令 :nginx -s reload 本文地址: https://www.linuxprobe.com/open-close-restart.html
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
1. 解决安装seafile server时的依赖关系
官方提供的安装包,大部分依赖都已经打包在包里了, 只有seahub依赖的部分Python包,因为使用了C语言,编译安装时必须和Python的版本对应(这也是之前Windows版本必须安装指定版本python的原因),由于无法预知客户端的Python版本,所以无法包含在安装包中。官方提供的安装包,大部分依赖都已经打包在包里了, 只有seahub依赖的部分Python包,因为使用了C语言,编译安装时必须和Python的版本对应(这也是之前Windows版本必须安装指定版本python的原因),由于无法预知客户端的Python版本,所以无法包含在安装包中。
具体请参考: Seafile Server 7.1.3避坑:解决依赖关系
2. MySQL/Mariadb数据库配置
有些系统安装的MySQL/Mariadb数据库,默认配置是不允许root用户通过网络连接服务器的,而安装脚本配置数据库一项有两个选项,分别是自动创建和使用已有的数据库,其中自动创建数据库需要使用root连接数据库。
具体请参考: Seafile Server 7.1.3避坑:配置 MySQL 数据库
3. 开机自动启动配置
由于每个人的安装路径和用户配置不同,Seafile安装包中无法附带现成的systemd服务脚本文件,致使部分新手无法配置开机自启动服务。
具体请参考: Seafile Server 7.1.3避坑:开机自启动配置
几个在安装和维护Seafile Server过程用可以用到的脚本
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
zabbix版本3.4.11
activemq5.9
系统centos6or7
监控硬件物理空间是否充足:
ActiveMQ有3个重要的参数,存储空间百分比,内存空间百分比和临时空间百分比。这三个参数的意义很明显,如果值到了100,则表明硬件空间已满,Broker不能再接受任何的消息了,除非有消息消费并且删除,Broker才可以再接收消息。
如果这些值长时间都比较高,接近阀值,则表示硬件的配置不能满足要求,建议更换硬件,或者给予ActiveMQ的环境配置比较小,建议给予更多的资源给ActiveMQ。
如果平时保持在一个稳定值,有一段时间突然增高,则有两种可能。一种可能是用户量大增(当然大家都希望是这样),另一种可能是某个或者某几个消息消费者死机了。需要人工干预重启。
还有一种可能是平时保持在一个稳定值,但是一段时间内突然降低了,则表示消息的生产者可能出现问题了。
监控队列:
如果ActiveMQ使用队列,需要监控队列的未消费消息数量,消费者数量,消息入队和出队的数量。
未消费消息数量的含义和监控硬件的内存和硬盘空间差不多,过多的消息堆积可能是有消息消费者死机。
消费者数量应该是一个相对固定的值,这个值减少,就直接表示有的消费者已经死机。
消息入队和出队数量如果增长缓慢或者不增长,则表示消息发送者已经死机。一般是通过增量监控。
监控方式 是访问 activemq的管理端口8161接口 Jolokia API
例如 [root@znhjkapp02 ~]# curl -u admin:admin http://9.1.8.247:8161/api/jolokia/read/org.apache.activemq:type=Broker,brokerName=localhost,service=Health/CurrentStatus 2>/dev/null |jq . { "value": "Good", "request": { "type": "read", "attribute": "CurrentStatus", "mbean": "org.apache.activemq:brokerName=localhost,service=Health,type=Broker" }, "status": 200, "timestamp": 1585721407 }
jq工具是 Linux下解析json的工具
最后取得value值如下 [root@znhjkapp02 ~]# curl -u admin:admin http://9.1.8.247:8161/api/jolokia/read/org.apache.activemq:type=Broker,brokerName=localhost,service=Health/CurrentStatus 2>/dev/null |jq .value "Good"
我们监控activem的几个指标如下 #当前服务器状态 curl -u admin:admin http://9.1.8.247:8161/api/jolokia/read/org.apache.activemq:type=Broker,brokerName=localhost,service=Health/CurrentStatus |jq . Memory percent used #内存使用情况 curl -u admin:admin http://9.1.8.247:8161/api/jolokia/read/org.apache.activemq:type=Broker,brokerName=localhost/MemoryPercentUsage |jq . Store percent used #磁盘使用情况 curl -u admin:admin http://9.1.8.247:8161/api/jolokia/read/org.apache.activemq:type=Broker,brokerName=localhost/StorePercentUsage |jq . Temp percent used #临时文件磁盘空间使用量 curl -u admin:admin http://9.1.8.247:8161/api/jolokia/read/org.apache.activemq:type=Broker,brokerName=localhost/TempPercentUsage |jq . Number Of Pending Messages #队列 未消费消息数量 curl -u admin:admin http://9.1.8.247:8161/api/jolokia/read/org.apache.activemq:type=Broker,brokerName=localhost,destinationType=Queue,destinationName=serviceQueue/QueueSize |jq . Number Of Consumers #消费队列数 curl -u admin:admin http://9.1.8.247:8161/api/jolokia/read/org.apache.activemq:type=Broker,brokerName=localhost,destinationType=Queue,destinationName=eventQueue/ConsumerCount |jq . Messages Enqueued #已接收的队列数 curl -u admin:admin http://9.1.8.247:8161/api/jolokia/read/org.apache.activemq:type=Broker,brokerName=localhost,destinationType=Queue,destinationName=eventQueue/EnqueueCount |jq . Messages Dequeued #已消费的队列数 curl -u admin:admin http://9.1.8.247:8161/api/jolokia/read/org.apache.activemq:type=Broker,brokerName=localhost,destinationType=Queue,destinationName=eventQueue/DequeueCount |jq . 生产者数量 http://9.1.8.247:8161/api/jolokia/read/org.apache.activemq:type=Broker,brokerName=localhost,destinationType=Queue,destinationName=eventQueue/ProducerCount 获取所有eventQueue http://9.1.8.247:8161/api/jolokia/read/org.apache.activemq:type=Broker,brokerName=localhost/Queues
开始修改自动发现队列脚本 #这个自动发现脚本来自网络 自己稍作修改 [root@znhjkapp02 zabbix_agentd.d]# cat activemq_discovery.sh #!/bin/bash discovery() { #MQ_IP=(172.16.8.119 172.16.8.120 172.16.8.118) MQ_IP=(9.1.8.247) for g in ${MQ_IP[@]} do curl -uadmin:admin http://${g}:8161/admin/queues.jsp >/dev/null 2>&1 if [ $? -eq 0 ];then i=$g fi port=($(curl -uadmin:admin http://${i}:8161/admin/queues.jsp 2>/dev/null| grep -A 5 "${QUEUENAME}"|awk -F '<' '{print $0}'|sed 's/<\/td>//g'|sed 's/<.*>//g;/^$/d;/--/d'|grep '^[a-Z]')) done printf '{\n' printf '\t"data":[\n' for key in ${!port[@]} do if [[ "${#port[@]}" -gt 1 && "${key}" -ne "$((${#port[@]}-1))" ]];then printf '\t {\n' printf "\t\t\t\"{#QUEUENAME}\":\"${port[${key}]}\"},\n" else [[ "${key}" -eq "((${#port[@]}-1))" ]] printf '\t {\n' printf "\t\t\t\"{#QUEUENAME}\":\"${port[${key}]}\"}\n" fi done printf '\t ]\n' printf '}\n' } discovery
本地测试 [root@znhjkapp02 zabbix_agentd.d]# ./activemq_discovery.sh { "data":[ { "{#QUEUENAME}":"eventQueue"}, { "{#QUEUENAME}":"serviceQueue"}, { "{#QUEUENAME}":"event_mmdb"}, { "{#QUEUENAME}":"transferQueue"}, { "{#QUEUENAME}":"mmdbQueue"}, { "{#QUEUENAME}":"IOMP_CLOUD_TO_CMPM"}, { "{#QUEUENAME}":"TEST"} ] }
状态监控脚本 [root@znhjkapp02 zabbix_agentd.d]# cat activemq_status.sh #/bin/sh QUEUENAME=$1 MQ_COMMAND=$2 #MQ_IP=(172.16.8.120 172.16.8.118 172.16.8.119) MQ_IP=(9.1.8.247) for g in ${MQ_IP[@]} do curl -uadmin:admin http://${g}:8161/admin/queues.jsp >/dev/null 2>&1 if [ $? -eq 0 ]; then i=$g case $MQ_COMMAND in Enqueued) curl -uadmin:admin http://${i}:8161/api/jolokia/read/org.apache.activemq:type=Broker,brokerName=localhost,destinationType=Queue,destinationName=${QUEUENAME}/EnqueueCount 2>/dev/null |/usr/bin/jq .value ;; Dequeued) curl -uadmin:admin http://${i}:8161/api/jolokia/read/org.apache.activemq:type=Broker,brokerName=localhost,destinationType=Queue,destinationName=${QUEUENAME}/DequeueCount 2>/dev/null |/usr/bin/jq .value ;; Pending) curl -uadmin:admin http://${i}:8161/api/jolokia/read/org.apache.activemq:type=Broker,brokerName=localhost,destinationType=Queue,destinationName=${QUEUENAME}/QueueSize 2>/dev/null |/usr/bin/jq .value ;; Consumers) curl -u admin:admin http://${i}:8161/api/jolokia/read/org.apache.activemq:type=Broker,brokerName=localhost,destinationType=Queue,destinationName=${QUEUENAME}/ConsumerCount 2>/dev/null |/usr/bin/jq .value ;; ServerStatus) curl -u admin:admin http://${i}:8161/api/jolokia/read/org.apache.activemq:type=Broker,brokerName=localhost,service=Health/CurrentStatus 2>/dev/null |jq .value ;; MemoryPercentUsage) curl -u admin:admin http://${i}:8161/api/jolokia/read/org.apache.activemq:type=Broker,brokerName=localhost/MemoryPercentUsage 2>/dev/null|jq .value ;; StorePercentUsage) curl -u admin:admin http://${i}:8161/api/jolokia/read/org.apache.activemq:type=Broker,brokerName=localhost/StorePercentUsage 2>/dev/null |jq .value ;; TempPercentUsage) curl -u admin:admin http://${i}:8161/api/jolokia/read/org.apache.activemq:type=Broker,brokerName=localhost/TempPercentUsage 2>/dev/null|jq .value ;; esac fi done
本地测试 [root@znhjkapp02 zabbix_agentd.d]# ./activemq_status.sh event_mmdb ServerStatus #需要传2个参数 一个队列名 一个监控项 "Good"
修改zabbix agent上的配置 [root@znhjkapp02 zabbix_agentd.d]# cat activemq.conf UserParameter=mq.mqScan,/etc/zabbix/zabbix_agentd.d/activemq_discovery.sh UserParameter=mq.status[*],/etc/zabbix/zabbix_agentd.d/activemq_status.sh $1 $2
zabbix添加自动发现模板
配置--模板--创建模板
创建自动发现规则
创建监控项原型
服务器端测试自动发现 [root@Zabbix_server_proxy ~]# /data/zabbix3.4-proxy/bin/zabbix_get -s 9.1.8.247 -p 10050 -k "mq.mqScan" { "data":[ { "{#QUEUENAME}":"eventQueue"}, { "{#QUEUENAME}":"serviceQueue"}, { "{#QUEUENAME}":"event_mmdb"}, { "{#QUEUENAME}":"transferQueue"}, { "{#QUEUENAME}":"mmdbQueue"}, { "{#QUEUENAME}":"IOMP_CLOUD_TO_CMPM"}, { "{#QUEUENAME}":"TEST"} ] } [root@Zabbix_server_proxy ~]# /data/zabbix3.4-proxy/bin/zabbix_get -s 9.1.8.247 -p 10050 -k "mq.status[event_mmdb,ServerStatus]" "Good"
查看zabbix最新数据
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
xargs 实用程序允许您从标准输入构建和执行命令。 它通常通过管道与其他命令组合使用。
使用 xargs,可以将标准输入作为参数提供给 mkdir 和 rm 等命令行实用程序。
如何使用 xargs 命令
xargs 从标准输入中读取参数(由空格或换行符分隔) ,并使用输入作为命令的参数执行指定的命令。 如果没有提供命令,则默认为/bin/echo。
xargs 命令的语法如下: xargs [OPTIONS] [COMMAND [initial-arguments]]
使用 xargs 的最基本示例是使用管道向 xargs 传递以空格分隔的几个字符串,并运行一个将这些字符串用作参数的命令。 echo "file1 file2 file3" | xargs touch
在上面的示例中,接下来将标准输入管道输送到 xargs,并为每个参数运行 touch 命令,创建三个文件。 这和你跑步的时候是一样的: touch file1 file2 file3
如何查看命令和提示用户
要在执行命令之前在终端上打印该命令,请使用-t (--verbose)选项: echo "file1 file2 file3" | xargs -t touch touch file1 file2 file3
如果您希望得到一个提示,在执行每个命令之前是否运行它,请使用-p (--interactive)选项: echo "file1 file2 file3" | xargs -p touch
键入 y 或 Y 以确认并运行命令: touch file1 file2 file3 ?...y
此选项在执行破坏性命令时非常有用, 比如 rm ,还有这个命令千万不要在服务器上运行
如何限制参数的数量
默认情况下,传递给命令的参数数量由系统的限制决定。 n (--max-args)选项指定传递给给定命令的参数数目。 xargs 根据需要多次运行指定的命令,直到所有参数都用完为止。
在下面的示例中,从标准输入中读取的参数数目被限制为1。 echo "file1 file2 file3" | xargs -n 1 -t touch
从下面的详细输出中可以看到,touch 命令针对每个参数分别执行: touch file1 touch file2 touch file3
如何运行多个命令
要使用 xargs 运行多个命令,请使用-i 选项。 它通过在-i 选项后定义一个 replace-str 来工作,并且所有 replace-str 的出现都被传递给 xargs 的参数替换。
下面的 xargs 示例将运行两个命令,首先使用 touch 创建文件,然后使用 ls 命令列出文件: echo "file1 file2 file3" | xargs -t -I % sh -c '{ touch %; ls -l %; }' -rw-r--r-- 1 linuxize users 0 May 6 11:54 file1 -rw-r--r-- 1 linuxize users 0 May 6 11:54 file2 -rw-r--r-- 1 linuxize users 0 May 6 11:54 file3
需要注意的是在MacOS上并没有-i这个参数,只有-I,用法差不多。 Replace-str 的一个常见选择是% 。但是,您可以使用另一个占位符,例如 ARGS: echo "file1 file2 file3" | xargs -t -I ARGS sh -c '{ touch ARGS; ls -l ARGS; }'
如何指定分隔符
使用-d (--delimiter)选项设置自定义分隔符,可以是单个字符,也可以是以开始的转义序列。
接下来正在使用下面的示例作为分隔符: echo "file1;file2;file3" | xargs -d \; -t touch touch file1 file2 file3
如何从文件中读取项目
xargs 命令还可以从文件而不是标准输入中读取项。 为此,请使用-a (--arg-file)选项后跟文件名。
在下面的示例中,xargs 命令将读取 ips.txt 文件并 ping 每个 IP 地址。 ips.txt 8.8.8.8 1.1.1.1
接下来还使用-l1选项,它指示 xargs 一次读取一行。 如果省略此选项,xargs 将把所有 ip 传递给单个 ping 命令。 xargs -t -L 1 -a ips.txt ping -c 1 ping -c 1 8.8.8.8 PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data. 64 bytes from 8.8.8.8: icmp_seq=1 ttl=50 time=68.1 ms ... ping -c 1 1.1.1.1 PING 1.1.1.1 (1.1.1.1) 56(84) bytes of data. 64 bytes from 1.1.1.1: icmp_seq=1 ttl=59 time=21.4 ms
使用xargs 与find
xargs 最常与 find 命令结合使用。 您可以使用 find 搜索特定的文件,然后使用 xargs 对这些文件执行操作。
为了避免包含换行符或其他特殊字符的文件名出现问题,始终使用 find-print0选项,这会导致 find 打印完整的文件名后面跟一个空字符。 xargs 可以使用-0,(-null)选项正确地解释这个输出。
在下面的示例中,find 将打印/var/www/中所有文件的完整名称。 Cache directory 和 xargs 将把文件路径传递给 rm 命令: find /var/www/.cache -type f -print0 | xargs -0 rm -f
使用 xargs 修剪空白字符
xargs 还可以用作从给定字符串的两侧删除空格的工具。 只需通过管道将字符串传递给 xargs 命令,它就会执行修整操作: echo " Long line " | xargs Long line
这在比较 shell 脚本中的字符串时非常有用。 #!/bin/bash VAR1=" chasays " VAR2="chasays" if [[ "$VAR1" == "$VAR2" ]]; then echo "Strings are equal." else echo "Strings are not equal." fi ## Using xargs to trim VAR1 if [[ $(echo "$VAR1" | xargs) == "$VAR2" ]]; then echo "Strings are equal." else echo "Strings are not equal." fi Strings are not equal. Strings are equal.
小结
xargs 是 Linux 上的命令行实用工具,能够搭配其他命令,使用出惊人的效果。 本篇文章由一文多发平台ArtiPub 自动发布
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>> 准备工作 配置好yum源,最好也把epel源配置上 准备两台服务器(247 server,241 client) 开始安装
启动并设置开机启动
配置共享目录
客户端挂载
写入到fstab
总结,nfs参数说明 rw 该主机对该共享目录有读写权限 sync 资料同步写入到内存与硬盘中,防止数据丢失 no_root_squash 客户机用root访问该共享文件夹时,不映射root用户 no_all_squash 保留共享文件的UID和GID references
nfs参数参考文档
nfs参数参考文档
nfs server配置参考文档
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
网络上的每一个Web站点都有一个惟一的身份标识,从而使客户机能够准确地访问。这一标识由三部分组成,即TCP端口号、IP地址和主机头名,通常有三种不同的实现途径。
通常情况下我们只会想到利用传统方式修改TCP端口号,IP地址和主机头名这三种途径进行多站点的添加和管理,但是今天小编想给大家介绍一种新的更快更便捷的方法,通过服务器管理面板直接创建多个WEB站点!
可实现部署多个站点面板有(可根据自己情况选择使用)
1. 宝塔
2. 云帮手
具体操作方法:
1. 登陆属于你的服务器管理工具帐号
2. 找到站点管理功能,点击进入
3. 选择创建新站点
4. 点击“创建新站点”,显示创建站点弹框,填写相关信息后,点击“下一步”
5. 点击下一步创建数据库
6. 点击下一步创建FTP
7. 点击下一步,完成站点添加
注意事项:
Windows 环境下的 Web 服务器有 IIS、Apache 和 Nginx 三种服务
Linux 环境下的 WEB 服务有 Apache 和 Nginx 两种服务
今天的分享就到这里了,如果大家有什么疑问和更好的方式方法推荐可以随时交流,最后附上站点管理工具下载地址( 点击下载) ,大家有兴趣可以自己研究下~~
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
| Kubernetes是一个开源的,用于管理云平台中多个主机上的容器化的应用,Kubernetes的目标是让部署容器化的应用简单并且高效(powerful),Kubernetes提供了应用部署,规划,更新,维护的一种机制。 |
|---|
前提条件是,有storageclass,利用pvc 创建持久化存储 创建kube-ops namespace
这里创建opspvc 另外把accessmode 换成readwritemany,因为会有多个pod 进行读写
然后部署jenkins master deployment如下 --- apiVersion: extensions/v1beta1 kind: Deployment metadata: name: jenkins namespace: kube-ops spec: template: metadata: labels: app: jenkins spec: terminationGracePeriodSeconds: 10 serviceAccountName: jenkins containers: - name: jenkins image: jenkins/jenkins:lts imagePullPolicy: IfNotPresent ports: - containerPort: 8080 name: web protocol: TCP - containerPort: 50000 name: agent protocol: TCP resources: limits: cpu: 2000m memory: 4Gi requests: cpu: 1000m memory: 2Gi livenessProbe: httpGet: path: /login port: 8080 initialDelaySeconds: 60 timeoutSeconds: 5 failureThreshold: 12 readinessProbe: httpGet: path: /login port: 8080 initialDelaySeconds: 60 timeoutSeconds: 5 failureThreshold: 12 volumeMounts: - name: jenkinshome subPath: jenkins mountPath: /var/jenkins_home env: - name: LIMITS_MEMORY valueFrom: resourceFieldRef: resource: limits.memory divisor: 1Mi - name: JAVA_OPTS value: -Xmx$(LIMITS_MEMORY)m -XshowSettings:vm -Dhudson.slaves.NodeProvisioner.initialDelay=0 -Dhudson.slaves.NodeProvisioner.MARGIN=50 -Dhudson.slaves.NodeProvisioner.MARGIN0=0.85 -Duser.timezone=Asia/Shanghai securityContext: fsGroup: 1000 volumes: - name: jenkinshome persistentVolumeClaim: claimName: opspvc --- apiVersion: v1 kind: Service metadata: name: jenkins namespace: kube-ops labels: app: jenkins spec: selector: app: jenkins ports: - name: web port: 8080 targetPort: web - name: agent port: 50000 targetPort: agent
分配权限,配置rbac如下 apiVersion: v1 kind: ServiceAccount metadata: name: jenkins namespace: kube-ops --- kind: Role apiVersion: rbac.authorization.k8s.io/v1beta1 metadata: name: jenkins namespace: kube-ops rules: - apiGroups: [""] resources: ["pods"] verbs: ["create","delete","get","list","patch","update","watch"] - apiGroups: [""] resources: ["pods/exec"] verbs: ["create","delete","get","list","patch","update","watch"] - apiGroups: [""] resources: ["pods/log"] verbs: ["get","list","watch"] - apiGroups: [""] resources: ["secrets"] verbs: ["get"] --- apiVersion: rbac.authorization.k8s.io/v1beta1 kind: RoleBinding metadata: name: jenkins namespace: kube-ops roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: jenkins subjects: - kind: ServiceAccount name: jenkins namespace: kube-ops
安装k8s 插件,与k8s 目标集群进行远程连接
因为是腾讯云,并没有提供tls 客户端认证,所以直接利用账号密码,进行认证,记得,禁用https 证书检查,jenkins和k8s 就集成好了
划重点!!!:jenkins地址,这里我这里写的是内网地址以及暴露了50000端口(用来与slave 建立通信使用),因为master 和slave 分别在不通的k8s 集群里,那么需要远程进行联通,而jenkins-ui 我是以ingress 的方式对外暴露
slave 的配置
这里需要注意的是标签列表,这里填写的标签,需要在slave 所在k8s 集群的节点上进行标注,而这个名字,是label这个字段里的key 并未是value,这里要注意
job 里配置
这个意思就是 slave 会尽可能的在这个节点build 本文地址: https://www.linuxprobe.com/k8s-jenkins.html
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
修改默认端口号,主要受防火墙和SELinux影响。
下面的例子是将ssh默认的22端口改成2222端口
1.编辑文件/etc/ssh/sshd_config。找到Port 22那一行,将前面的#号去掉,把22改成2222
2.打开防火墙的2222端口,并关闭防火墙的ssh服务
3.如果启用了SELinux,那么将2222端口的属性改成http_ssh_port
重启sshd服务后显示状态如上图时,时因为SELinux控制了。
semanage port -at ssh_port_t -p tcp 2222
4.重启ssh服务,用xshell测试一下
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
我们产品团队内部一直有一个需求,通过脚本轮询git仓库的方式来触发流水线,开发人员也可以通过脚本轮询来更新本地的代码,十分的方便。 仓库一有变更,轮询脚本便会拉取到最新的commit来触发流水线进行编译测试构建等操作,不需要再人工进行干预。 最近比较有空,就腾出时间来写了一个简单的轮询脚本, 流程大致如下:
1: 每隔5s轮询一遍我们组织下的所有仓库状态,
2: 有新提交之后,将新的commit拉取下来,
3: 触发编译构建等后续操作
写完之后将脚本放在我们的构建机器上面去跑,开始跑着感觉效果不错,推了几次commit,构建都成功触发了。结果脚本运行没过多久,就有同事在开发群里反馈本地拉不了代码了,开始还以为是公司自建的git平台服务出问题了,立马找到git平台同事一问,才知道是我们组织每小时的下载次数超过了5000次,触发了git平台的限流,需要等一段时间才能恢复正常的下载请求。看到开发同事都在吐槽拉不了代码,立马把新脚本下了线,过了差不多半个小时之后,我们组的代码下载才恢复正常,事后找到git平台支撑人员理论: 我们组只是用脚本去轮询组织下的仓库是否有新的commit提交,当一个仓库有新的commit时才会进行下载,并不是一直在轮询下载仓库代码,为什么会触发到限流呢? git平台那边的同学给的反馈是轮询也会消耗git平台的服务器的资源,当平台总并发量特别高时,会影响到所有用户的使用,包括界面访问和本地代码都会被拖慢,所以也限制了这种情况的没小时访问次数,在交流的过程中git平台的同学也给我们提了一个很好的建议,这里记录一下,分享给大家:
git平台一般支持推送事件触发webhook回调,在仓库设置界面中可以开启这个好用的功能。 使用wehook需要先在流水线机器上运行一个服务,服务的大致逻辑如下: 主要是需要运行一个监听程序,我这里是用springboot做的,大家可以参考一下 @RequestMapping("/Callback") public class GetCahngeController { @RequestMapping("/get") public String get(HttpServletRequest request){ request.request.getParameter('after') //取到最新的commit request.request.getParameter('repository') //获取仓库相关信息 doClone() //通过获取的仓库地址和最新的分支等信息,将仓库拉取下来 doBuild() //执行后续操作 } }
服务起好之后就可以将服务的地址填到webhook设置中,然后勾选push触发,如果是触发上线发布的流程的话,可以选择tag push,就可以实现打tag之后自动发布版本了,比原先的轮询方式还要方便。
替换到webhook之后,当有新的commit push到仓库时,webhook就会发一条消息到这个服务上来,消息中会包含提交人,commit推往的分支,最新的commit的信息和commit的父节点的信息,还会返回仓库的详细信息,如clone地址等,可以通过这个clone地址可commit id结合起来,取到最新的一次提交,然后发起构建,比轮询的实时性更高,而且不用当心轮询导致仓库的下载次数超限,影响公司的git服务。
如果你要是觉得组织下仓库太多设置webhook不方便的话,可以使用webhook相关的设置api,批量给仓库设置webhook。
在这里给大家分享一下,希望这个方法能对大家有帮助。
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
1、递归搜索文件内容,如果查找"hello,world!"字符串,可以这样:
grep -rn "hello,world!" *
* : 表示当前目录所有文件,也可以是某个文件名
-r 是递归查找
-n 是显示行号
-R 查找所有文件包含子目录
-i 忽略大小写
2、搜索文件
find / -name 'pay.html'
/:表示根目录,也可以自己指定搜索的目录。
-name:表示搜索文件名称。
pay.html:表搜索的文件名称。
3、批量替换。
替换server.xml文件中的”2020”为”8008”
sed -i 's/2020/8080/g' ./conf/server.xml
批量替换,替换server.xml文件中的”2020”为”8008”,将结果输出到result1.xml
sed -i 's/2020/8080/g' ./conf/server.xml > result1.xml
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
| docker client 是docker架构中用户用来和docker daemon建立通信的客户端,用户使用的可执行文件为docker,通过docker 命令 行工具可以发起众多管理container的请求。 |
|---|
概述
今天主要简单介绍下docker的技术架构及其中组成的各个模块。
distribution 负责与docker registry交互,上传洗澡镜像以及v2 registry 有关的源数据
registry负责docker registry有关的身份认证、镜像查找、镜像验证以及管理registry mirror等交互操作。
image 负责与镜像源数据有关的存储、查找,镜像层的索引、查找以及镜像tar包有关的导入、导出操作。
reference负责存储本地所有镜像的repository和tag名,并维护与镜像id之间的映射关系。
layer模块负责与镜像层和容器层源数据有关的增删改查,并负责将镜像层的增删改查映射到实际存储镜像层文件的graphdriver模块。
graghdriver是所有与容器镜像相关操作的执行者。
1、docker client
docker client 是docker架构中用户用来和docker daemon建立通信的客户端,用户使用的可执行文件为docker,通过docker 命令 行工具可以发起众多管理container的请求。
docker client发送容器管理请求后,由docker daemon接受并处理请求,当docker client 接收到返回的请求相应并简单处理后,docker client 一次完整的生命周期就结束了,当需要继续发送容器管理请求时,用户必须再次通过docker可以执行文件创建docker client。
2、docker daemon
docker daemon 是docker架构中一个常驻在后台的系统进程,功能是:接收处理docker client发送的请求。该守护进程在后台启动一个server,server负载接受docker client发送的请求;接受请求后,server通过路由与分发调度,找到相应的handler来执行请求。
docker daemon启动所使用的可执行文件也为docker,与docker client启动所使用的可执行文件docker相同,在docker命令执行时,通过传入的参数来判别docker daemon与docker client。
3、docker server
docker server在docker架构中时专门服务于docker client的server,该server的功能时:接受并调度分发docker client发送的请求,架构图如下:
在Docker的启动过程中,通过包gorilla/mux(golang的类库解析),创建了一个mux.Router,提供请求的路由功能。在Golang中,gorilla/mux是一个强大的URL路由器以及调度分发器。该mux.Router中添加了众多的路由项,每一个路由项由HTTP请求方法(PUT、POST、GET或DELETE)、URL、Handler三部分组成。
4、engine
Engine是Docker架构中的运行引擎,同时也Docker运行的核心模块。它扮演Docker container存储仓库的角色,并且通过执行job的方式来操纵管理这些容器。
在Engine数据结构的设计与实现过程中,有一个handler对象。该handler对象存储的都是关于众多特定job的handler处理访问。举例说明,Engine的handler对象中有一项为:{“create”: daemon.ContainerCreate,},则说明当名为”create”的job在运行时,执行的是daemon.ContainerCreate的handler。
5、job
一个Job可以认为是Docker架构中Engine内部最基本的工作执行单元。Docker可以做的每一项工作,都可以抽象为一个job。例如:在容器内部运行一个进程,这是一个job;创建一个新的容器,这是一个job,从Internet上下载一个文档,这是一个job;包括之前在Docker Server部分说过的,创建Server服务于HTTP的API,这也是一个job,等等。
Job的设计者,把Job设计得与Unix进程相仿。比如说:Job有一个名称,有参数,有环境变量,有标准的输入输出,有错误处理,有返回状态等。
6、docker registry
Docker Registry是一个存储容器镜像的仓库。而容器镜像是在容器被创建时,被加载用来初始化容器的文件架构与目录。
在Docker的运行过程中,Docker Daemon会与Docker Registry通信,并实现搜索镜像、下载镜像、上传镜像三个功能,这三个功能对应的job名称分别为”search”,”pull” 与 “push”。
其中,在Docker架构中,Docker可以使用公有的Docker Registry,即大家熟知的Docker Hub,如此一来,Docker获取容器镜像文件时,必须通过互联网访问Docker Hub;同时Docker也允许用户构建本地私有的Docker Registry,这样可以保证容器镜像的获取在内网完成。
7、Graph
Graph在Docker架构中扮演已下载容器镜像的保管者,以及已下载容器镜像之间关系的记录者。一方面,Graph存储着本地具有版本信息的文件系统镜像,另一方面也通过GraphDB记录着所有文件系统镜像彼此之间的关系。Graph的架构如下:
其中,GraphDB是一个构建在SQLite之上的小型图数据库,实现了节点的命名以及节点之间关联关系的记录。它仅仅实现了大多数图数据库所拥有的一个小的子集,但是提供了简单的接口表示节点之间的关系。
同时在Graph的本地目录中,关于每一个的容器镜像,具体存储的信息有:该容器镜像的元数据,容器镜像的大小信息,以及该容器镜像所代表的具体rootfs。
8、driver
Driver是Docker架构中的驱动模块。通过Driver驱动,Docker可以实现对Docker容器执行环境的定制。由于Docker运行的生命周期中,并非用户所有的操作都是针对Docker容器的管理,另外还有关于Docker运行信息的获取,Graph的存储与记录等。因此,为了将Docker容器的管理从Docker Daemon内部业务逻辑中区分开来,设计了Driver层驱动来接管所有这部分请求。
9、libcontainer
libcontainer是Docker架构中一个使用Go语言设计实现的库,设计初衷是希望该库可以不依靠任何依赖,直接访问内核中与容器相关的API。
正是由于libcontainer的存在,Docker可以直接调用libcontainer,而最终操纵容器的namespace、cgroups、apparmor、网络设备以及防火墙规则等。这一系列操作的完成都不需要依赖LXC或者其他包。libcontainer架构如下:
另外,libcontainer提供了一整套标准的接口来满足上层对容器管理的需求。或者说,libcontainer屏蔽了Docker上层对容器的直接管理。又由于libcontainer使用Go这种跨平台的语言开发实现,且本身又可以被上层多种不同的编程语言访问,因此很难说,未来的Docker就一定会紧紧地和 Linux 捆绑在一起。而于此同时,Microsoft在其著名云计算平台Azure中,也添加了对Docker的支持,可见Docker的开放程度与业界的火热度。
10、docker container
Docker container(Docker容器)是Docker架构中服务交付的最终体现形式。
Docker按照用户的需求与指令,订制相应的Docker容器:
用户通过指定容器镜像,使得Docker容器可以自定义rootfs等文件系统; 用户通过指定计算资源的配额,使得Docker容器使用指定的计算资源; 用户通过配置网络及其安全策略,使得Docker容器拥有独立且安全的网络环境; 用户通过指定运行的命令,使得Docker容器执行指定的工作。
本文地址: https://www.linuxprobe.com/docker-component.html
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
| 用户不必备份容器中的所有内容,但在发生灾难时备份运行和管理容器的配置是很重要的。用户的容器基础设施需要某种类型的备份。Kubernetes和Docker在灾难之后不会自己构建。用户无需备份每个容器的运行状态,但是需要备份用于运行和管理容器的配置。 |
|---|
用户的容器基础设施需要某种类型的备份。Kubernetes和Docker在灾难之后不会自己构建。用户无需备份每个容器的运行状态,但是需要备份用于运行和管理容器的配置。
以下是用户需要备份的内容。
配置和所需状态信息 Dockerfile用于构建镱像以及这些文件的所有版本 从Dockerfile创建并用于运行每个容器的镜像 Kubernetes etcd和其他有关集群状态的K8s数据库 Deployments用于描述每个部署的YAML文件
容器创建或更改的持久数据 持久卷 数据库
Dockerfiles
Docker容器从镜像运行,其镜像从Dockerfiles构建。正确的Docker配置将首先使用某种存储库(例如GitHub)作为所有Dockerfile的版本控制系统。不要使用从临时Dockerfile构建的临时镜像创建临时容器。所有Dockerfile都应存储在存储库中,如果当前版本存在问题,该存储库将允许用户提取这个Dockerfile的历史版本。
用户还应该具有存储与每个K8s部署关联的YAML文件的某种存储库,这些是可以从版本控制系统中受益的文本文件。
然后需要备份这些存储库。GitHub是比较受欢迎的存储库之一,它提供了许多备份存储库的方法。有多种 脚本 使用提供的API来下载存储库的当前备份。用户还可以使用第三方商业工具来备份GitHub或用户正在使用的任何存储库。
如果没有遵循上述建议,而是根据不再具有Dockerfile的镜像运行容器,则可以使用Docker 镜像历史 命令 或dfimage之类的工具从当前镜像创建Dockerfile。将这些Dockerfile放入存储库中,然后开始备份。但是不要陷入这种情况,应该始终存储和备份用于创建环境的Dockerfile和YAML文件。
Docker镜像
用于运行容器的当前镜像也应存储在存储库中(当然,如果用户正在Kubernetes中运行Docker镜像,那么已经在这样做了)。用户可以使用私有存储库(例如Docker注册表)或公共存储库(例如Dockerhub)。云计算提供商还可以为用户提供私人存储库来存储镜像。然后应备份该回购的内容。诸如“Dockerhub备份”之类的简单搜索就可以产生令人惊讶的众多选择。
如果用户没有用于运行容器的当前镜像,则可以使用docker commit 命令 创建一个。然后,使用Docker镜像历史记录或工具dfimage从该镜像创建Dockerfile。
Kubernetes etcd
Kubernetes etcd数据库非常重要,应使用etcdctl snapshot save db命令进行备份。这将在当前目录中创建文件snapshot.db。然后应将该文件备份到外部存储。
如果使用的是商业备份软件,则可以在创建snapshot.db的目录备份之前轻松触发etcdctl snapshot save命令。这是将备份集成到商业备份环境中的一种方法。
持久卷
容器可以通过多种方式访问持久性存储,而持久性存储可用于存储或创建数据。传统的Docker卷位于Docker配置的子目录中。绑定挂载只是Docker主机上安装在容器内(使用bind mount命令)的任何目录。出于多种原因,Docker社区首先选择传统卷,但出于备份目的,传统卷和绑定安装实质上是相同的。用户还可以将网络文件系统(NFS)目录或对象从对象存储系统作为卷装入容器中。
用于备份持久卷的方法将基于用于容器的上述选项。但是,它们都会有相同的问题:如果数据正在更改,则需要处理该问题才能获得一致的备份。
一种方法是关闭使用该特定卷的任何容器。这种做法虽然有些过时,但这是容器世界所面临的挑战之一,因为在容器中放置备份代理的典型方法并不是一种很好的选择。一旦关闭,便可以备份该卷。如果它是传统的Docker卷,则可以通过将其挂载到另一个在备份时不会更改其数据的容器中进行备份,然后在绑定安装的卷中创建该卷的tar镜像,然后使用备份系统使用的任何方法进行备份。
但是,这在Kubernetes中确实很难做到。这是有状态信息最好存储在数据库而不是文件系统中的原因之一。而在设计K8s基础设施时,需要考虑此问题。
另外,如果用户使用绑定安装目录、NFS安装文件系统或对象存储系统作为持久性存储系统,则可以使用优秀的方法来备份该存储系统。这可能是快照,然后是复制,或者只是在该系统上运行商业备份软件。与相同卷的典型文件级备份相比,这些方法可能提供更加一致的备份。
数据库
下一个备份挑战是容器使用数据库存储其数据。这些数据库需要以保证其完整性的方式进行备份。根据数据库的不同,上述方法可能会起作用:关闭访问数据库的容器,然后备份存储其文件的目录。但是,这种方法所需的停机时间可能不合适。
另一种方法是直接连接到数据库引擎本身,并要求它运行到文件的备份,然后可以对其进行备份。如果数据库在容器内运行,则首先需要使用绑定安装来附加一个可以备份的卷,因此其备份可以存在于容器外部。然后运行数据库使用的命令(例如mysqldump)创建备份。然后确保使用备份系统创建的文件。
如果用户不知道哪些容器正在使用什么样的存储或什么样的数据库怎么办?一种解决方案可能是使用docker ps命令列出正在运行的容器,然后使用docker inspect命令显示每个容器的配置。有一个名为“挂载”的部分,它将告诉用户将哪些卷挂载在何处。任何绑定安装也将在用户提交给Kubernetes的YAML文件中指定。
商业备份解决方案
有各种各样的商业备份解决方案可以保护上述部分或全部数据。以下是一个非常简短的摘要: Commvault的虚拟服务器代理可以充当备份容器及其镜像的代理。 Cohenity为K8s命名空间提供数据保护。 Heptio(现为VMware公司)提供为K8s设计的Velero备份。 Contino、Datacore和Portworx提供专为K8和容器设计的存储,并且还支持备份该信息。
鉴于K8和Docker的配置方式多种多样,很难涵盖所有内容。但是希望提供一些思考的机会,或者可以帮助用户备份一些应该但尚未备份的东西。 本文地址: https://www.linuxprobe.com/kubernetes-docker.html
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
IIS7服务器管理工具能够作为FTP的客户端,进行FTP的命令操作,可在客户端,下载,安装FTP软件!
同时,它也可以作为VNC的客户端,进行VNC的命令操作!它能够批量连接Windows和Linux系统下的服务器和VPS,并能够实时监测他们的连接状态,便于日常维护和操作!
下载地址: 服务器管理工具
第一步:点击主程序图中“上传下载”键;
第二步:点击“ Ftp”;
第三步:点击“添加”;
第四步:在弹出服务器信息框中填写Ftp信息,注意:FIP ip端口、账号、密码为必填项;
第五步:选择需要打开的FTP服务器;
第六步:点击打开,即刻见FTP效果图。
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>> RHEL/CentOS 6: # yum install https://dl.fedoraproject.org/pub/epel/epel-release-latest-6.noarch.rpm RHEL/CentOS 7: # yum install https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm on RHEL 7 it is recommended to also enable the optional, extras, and HA repositories since EPEL packages may depend on packages from these repositories: # subscription-manager repos --enable "rhel-*-optional-rpms" --enable "rhel-*-extras-rpms" --enable "rhel-ha-for-rhel-*-server-rpms" RHEL/CentOS 8: # yum install https://dl.fedoraproject.org/pub/epel/epel-release-latest-8.noarch.rpm on RHEL 8 it is required to also enable the codeready-builder-for-rhel-8-*-rpms repository since EPEL packages may depend on packages from it: # ARCH=$( /bin/arch ) # subscription-manager repos --enable "codeready-builder-for-rhel-8-${ARCH}-rpms" on CentOS 8 it is recommended to also enable the PowerTools repository since EPEL packages may depend on packages from it: # dnf config-manager --set-enabled PowerTools
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
IIS7服务器管理工具能够作为VNC的客户端,进行VNC的命令操作,可在客户端,下载,安装VNC软件!
同时,它也可以作为FTP的客户端,进行FTP的命令操作!它能够批量连接Windows和Linux系统下的服务器和VPS,并能够实时监测他们的连接状态,便于日常维护和操作!
下载地址: 服务器管理工具
第一步:打开iis7服务器管理程序,找到“Vnc”;
第二步:点击添加;注意IP端口和密码为必填项;
第三步:输入信息后,点击添加;
第四步:勾选需要打开VNC服务器;
第五步:点击打开,即刻见VNC效果图。
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>> RHEL/CentOS 6: # yum install https://dl.fedoraproject.org/pub/epel/epel-release-latest-6.noarch.rpm RHEL/CentOS 7: # yum install https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm on RHEL 7 it is recommended to also enable the optional, extras, and HA repositories since EPEL packages may depend on packages from these repositories: # subscription-manager repos --enable "rhel-*-optional-rpms" --enable "rhel-*-extras-rpms" --enable "rhel-ha-for-rhel-*-server-rpms" RHEL/CentOS 8: # yum install https://dl.fedoraproject.org/pub/epel/epel-release-latest-8.noarch.rpm on RHEL 8 it is required to also enable the codeready-builder-for-rhel-8-*-rpms repository since EPEL packages may depend on packages from it: # ARCH=$( /bin/arch ) # subscription-manager repos --enable "codeready-builder-for-rhel-8-${ARCH}-rpms" on CentOS 8 it is recommended to also enable the PowerTools repository since EPEL packages may depend on packages from it: # dnf config-manager --set-enabled PowerTools
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
IIS7服务器管理工具能够作为VNC的客户端,进行VNC的命令操作,可在客户端,下载,安装VNC软件!
同时,它也可以作为FTP的客户端,进行FTP的命令操作!它能够批量连接Windows和Linux系统下的服务器和VPS,并能够实时监测他们的连接状态,便于日常维护和操作!
下载地址: 服务器管理工具
今天,就给大家演示一下在Linux系统下如何进行VNC的相关操作吧!
1,首先打开服务器管理工具
2,安装VNC server
3,配置VNC
4,编辑VNC
5,启动VNC
6,打开连接,进入操作界面即可
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
Portworx on RedHat OpenShift
https://v.qq.com/x/page/g0975mnzln0.html
欢迎回到Portworx技术讲解系列视频。我们今天介绍红帽Openshift上的Portworx。我们讨论基本的OpenShift部署,包括本地部署或者云部署方式,以及Portworx如何在这样的架构里使用。我们从生产环境开始,或者是具备一系列master节点的有一定数量级的集群开始。这是3个master节点,它们提供了API,用户可以通过API进行交互。它们也Host ETCD集群,意味着每一个Master节点上都存有状态,包括OpenShift集群的信息。另一部分我会介绍的是,OpenShift可以本地部署或者云部署,如部署到AWS、微软Azure、Google GCP,这些云计算平台上。本地部署通常是裸金属,可以包括存储阵列,和一组服务器,来提供计算和存储资源。不论是云计算还是本地部署,你可以有一组节点,或者一组VM,部署了操作系统,这些操作系统可能是RHEL或者CentOS。
一旦操作系统部署完成,我们可以把OpenShift部署到RHEL节点里。这个方块代表OpenShift。Openshift被部署到一组节点上,包括Master节点。这些节点里的3个是master节点,其他的可以做为应用、或者各种开发系统的主机。Portworx部署在OpenShift的上面。Portworx是一个云原生存储,为OpenShift上的应用,例如数据库,提供持久卷和动态部署。但是它是部署在Kubernetes之上的。在现在的情况下,它是部署在OpenShift上的,Portworx也可以运行在这些节点的任何一个节点之上,不是master节点,而是worker节点。
如果说我们的本地部署的基础架构,为我们的节点提供了一系列的LUNs,在云架构中,它可能是EBS或者Google持久磁盘。本地部署情况下,它可能是附加的存储阵列-提供LUN,或者直接附加的存储,如SSD,NVME,SATA驱动器。Portworx在安装完成后,会深入操作系统来消耗LUN,或者驱动器。它为Portworx创建了一个全局化的、跨越每一个OpenShift节点的可用存储池。这样你就能够在OpenShift集群上部署应用,Portworx会处理如何把数据附加到容器上。如果容器发生错误,它会流动到其他容器上。
用户如何来与Portworx互动?用户首先需要有一些Github上的代码,这些代码可以引用一个存储类,作为YAML文件的一部分。这个存储类可以为应用,例如数据库,设定一系列的参数,例如复制集、I/O优先级,I/O profile:database,优先级可以选择高、中、低。如果我们选择高,对于REPL,复制集,我们选3个复制集,我们的存储集群就会有这样的信息,以及一个YAML文件,它们会定义一个数据库,或者一个staple服务,会引用这个存储类。现在已经部署到集群上了,起了一个服务,例如是一个数据库,或者是staple服务,Portworx会动态的按照这些参数部署一个卷,为数据库容器服务,这个我们在Kubernetes和OpenShift上称之为PV。
需要引用的是PVC,包括存储类的名称,以便完成动态部署。现在因为我们已经有了3个复制集,Portworx会把三个复制及存储在3个位置,因此3个复制及是跨OpenShift集群的,这样就可以达到数据高可用。如果OpenShift节点上的容器发生错误,Openshift就会重新调度到集群的其他节点上,实现数据库的高可用。不论基础架构是本地部署还是云部署,也不论LUN附加在哪里。因为它管理的是下面的复制集。
这是对Portworx onOpenShift的总体价值,后面我们会讨论如果有多个OpenShift集群的情况,OpenShift可以通过Portworx提供容灾恢复功能。另一个要提到的是OpenShift可以动态的扩展,Portworx也可以随之动态扩展,只要OpenShift集群里的配置正确。在后面的系列视频里,我们会继续介绍OpenShift容灾、备份、和恢复。谢谢!
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
大家好,我是良许。
文件是我们在电脑里最珍贵的财富,我们经常工作了老半天,然后出来的成果就只是一个文件而已。特别是程序员,我们写了半天的代码,结果也就是一个个代码文件而已。
但是,我们都有过这样惨痛的经历——工作了老半天,结果不小心把文件删除了……
这时候,你的心情是怎样的?痛苦?自责?无奈?
今天良许就给大家介绍一个命令,它将给你的重要文件加一把锁,防止误删除或误修改,为你的宝贝文件保驾护航!
chattr命令简介
这里我们需要使用到一个命令是: chattr ,这个命令在大部分的 Linux 发行版里都有,所以对于它的安装就不赘述了。它的基本用法如下: $ chattr 操作符 属性 文件名
对于操作符,有以下三种: + :给文件增加属性 - :去除文件属性 = :设置文件的仅有属性
注意,这里讲的属性不是文件对应的系统属性,而是 chattr 给文件赋予的属性。本文要讲的属性有以下两个: a - 允许给文件追加内容 i - 保护模式(不允许删除或修改)
但是,它的属性可以设置很多,有兴趣的小伙伴可以去看下它的 man 手册。 $ man chattr
防止文件被误删除或修改
假如我们现在有个国宝级重要文件 file.txt ,现在我们使用 chattr 对它进行保护。在这里,我们给文件增加 +i 属性: $ sudo chattr +i file.txt
然后,我们可以使用 lsattr 命令查看它的属性。类似的输出如下: $ lsattr file.txt ----i---------e---- file.txt
现在,我们来尝试一下,手贱去删除那个文件: $ rm file.txt rm: cannot remove 'file.txt': Operation not permitted
咦?不允许删除?难道权限不够?
那好,我 sudo 一下! $ sudo rm file.txt rm: cannot remove 'file.txt': Operation not permitted
我 X ,居然还是不能删除?
我们再来试一下,修改文件的内容。 $ echo 'hello world!' >> file.txt bash: file.txt: Operation not permitted
可以看出来,依然不能对文件进行修改了。
而且,即使你从 GUI 界面手动去删除这个文件,也还是不能耐他几何。
所以,可以看出来,现在这个文件得到了很好的保护,既不能被删除(各种方法都不行),也不能被修改。
那我们要怎么去除这个保护呢?很简单,只需加上 -i 这个选项。 $ sudo chattr -i file.txt
现在,文件又恢复原样了,我们想修改就修改,想删除就删除。 $ echo 'Hello World!' >> file.txt $ cat file.txt Hello World! $ rm file.txt
防止文件夹被误删除或修改
上面讲到的是保护文件,那么文件夹要如何保护呢?
其实也是一样,使用 +i 这个选项。假如我们现在有个 dir1 目录,里面有个 file.txt 文件。我们来对这个文件夹进行保护。 $ sudo chattr -R +i dir1
在这里,我们使用 -R 选项表示可以递归作用到目录里所有的文件(包括子目录)。
现在,我们同样测试一下是否可以被删除或修改。 $ rm -rf dir1 $ sudo rm -rf dir1 rm: cannot remove 'dir1/file.txt': Operation not permitted $ echo 'hello world!' >> dir1/file.txt bash: file.txt: Operation not permitted
所以与文件一样,我们成功地对文件夹进行了保护。
防止文件/目录被删除,但允许追加内容
现在我们知道怎么防止文件/目录被误删除或修改了,但是,假如我们不想要文件已有内容被修改,但允许别人在文件末尾追加内容,要怎么操作?
这时候我们就需要使用 +a 这个选项了。
对文件: $ sudo chattr +a file.txt
对目录: $ sudo chattr -R +a dir1
现在,我们来确认一下,文件是否可以被追加内容。 $ echo 'Hello World!' >> file.txt $ echo 'Hello World!' >> dir1/file.txt
我们再使用 cat 命令去查看一下内容: $ cat file.txt Hello World! $ cat dir1/file.txt Hello World!
可以看出来,文件都是可以被追加的。
但是,file.txt 还有 dir1/file.txt 依然不能被删除。
如果你想去掉可追加的属性,可以使用 -a 这个选项。
对文件: $ sudo chattr -R -a file.txt
对目录: $ sudo chattr -R -a dir1/
最后,最近很多小伙伴找我要 Linux学习路线图 ,于是我根据自己的经验,利用业余时间熬夜肝了一个月,整理了一份电子书。无论你是面试还是自我提升,相信都会对你有帮助!目录如下:
免费送给大家,只求大家金指给我点个赞!
电子书 | Linux开发学习路线图
也希望有小伙伴能加入我,把这份电子书做得更完美!
有收获?希望老铁们来个三连击,给更多的人看到这篇文章
推荐阅读: 干货 | 程序员进阶架构师必备资源免费送 神器 | 支持搜索的资源网站
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
IIS7服务器管理工具是一款VNC远程连接的客户端,能够根据用户所需要进行操作的VNC远程产品数量来进行相应的批量操作!同时,它还能够作为FTP的客户端,进行FTP的相关操作,用来实现FTP的日常操作和管理!它也可以作为一个连接客户端,对Windows和Linux系统下的设备进行相对应的连接操作!
下载地址: IIS7服务器管理工具
1,打开服务器管理工具
2,安装VNC server
3,配置VNC
4,编辑VNC信息
5,启动VNC
6,打开服务器管理工具
7,等待连接成功,即可进入操作页面
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
IIS7服务器管理是windows一款常用的FTP操作软件,能够进行日常的FTP批量操作处理!同时还可以进行VNC的连接和操作!提高了远程处理的效率;还可连接windows、Linux系统下的服务器,并进行相关的管理和维护,方便于日常的操作!
第一步:点击主程序图中“上传下载”键; 第二步:点击“ Ftp”; 第三步:点击“添加”; 第四步:在弹出服务器信息框中填写Ftp信息,注意:FTP ip端口、账号、密码为必填项; 第五步:选择需要打开的FTP服务器; 第六步:点击打开,即刻见FTP效果图。
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
Failed to connect to repository : Command "git ls-remote -h git@192.168.91.11:test/dzp.git HEAD" returned status code 128:
stdout:
stderr: Permission denied, please try again.
Permission denied, please try again.
Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
fatal: Could not read from remote repository.
Please make sure you have the correct access rights
and the repository exists.
1.卸载自带的git,因为版本太低
本地服务器版本:
[root@vm_001034_op-test git-2.0.5]# cat /etc/redhat-release
CentOS release 6.5 (Final)
[root@vm_001034_op-test git-2.0.5]#
笔者从网上找了很多资料,最终参考几份资料才安装成功的。
原因很简单,就是没有安装git的依赖包。
以下yum是执行的一些解决依赖的yum命令,有些报错有些成功,应该是最后几条生效解决了 :
yum groupinstall “Development Tools”
yum install “Development Tools”
yum install zlib-devel perl-ExtUtils-MakeMaker asciidoc xmlto openssl-devel
yum install openssl-devel
yum install -y xmlto
yum install -y asciidoc
yum install zlib-devel perl-ExtUtils-MakeMaker
yum install zlib-devel
yum install perl-ExtUtils-MakeMaker
yum install curl-devel expat-devel gettext-devel openssl-devel zlib-devel
yum install gcc perl-ExtUtils-MakeMaker
yum remove git
下载安装git
cd /usr/src/
wget https://www.kernel.org/pub/software/scm/git/git-2.0.5.tar.gz
tar xzf git-2.0.5.tar.gz
cd git-2.0.5
make prefix=/usr/local/git all
make prefix=/usr/local/git install
echo "export PATH=$PATH:/usr/local/git/bin" >> /etc/bashrc
source /etc/bashrc
git --version
2.将ssh的私钥添加到验证信息中(不是xxx.pub)
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
1、 关于本来生活网
本来生活网创办于 2012 年,是一个专注于食品、水果、蔬菜的电商网站,从优质食品供应基地、供应商中精挑细选,剔除中间环节,提供冷链配送、食材食品直送到家服务。
致力于通过保障食品安全、提供冷链宅配、基地直送来改善中国食品安全现状,成为中国优质食品提供者。
2、挑战
互联网、电商公司的核心业务集中在线上进行,IT 架构决定公司的命脉。
本来生活网原本的 IT 基础设施以传统虚拟化的方式部署在 IDC 机房,物理机日常占用率达到了 95% 以上,资源紧缺,应用弹性扩容缓慢,无法满足线上业务的需求。
同时,本来生活网虽然是一家互联网电商公司,但很早就停止了烧钱模式,开始追求盈利,对 IT 建设也提出了尽量平衡成本、开源节流的要求。
所以,本来生活网迫切需要重构基础设施,建设一套 更为灵活、更为敏捷的 IT 架构 , 以优化开发运维流程 ,最大程度提高应用开发效率并 降低 IT 生产环境运维成本 。
最终,本来生活网决定将生产环境容器化,把生产环境从虚拟化迁移到 Kubernetes 上,以提高资源利用率,实现应用弹性伸缩,最终降低运维人员的工作复杂度。
此外,本来生活的应用发布由测试团队完成,但测试人员缺乏一定的开发运维经验,无法快速上手 Kubernetes 实现版本快速迭代。
想要打通开发、测试与运维的 DevOps 一体化流程,需要一个统一的平台配合应用开发和上线发布的整套流程。
然而,本来生活网通过调研发现,市场上大部分容器平台,都不能满足他们目前的需求。
3、解决方案
本来生活网选择 KubeSphere 解决上述问题。
KubeSphere 是青云QingCloud 旗下容器平台,也是一款开源的 Kubernetes 发行版,通过极简的人机交互提供完善的多集群管理、CI / CD、微服务治理、应用管理等功能,帮助企业在云、虚拟化及物理机等异构基础设施上快速构建、部署及运维容器架构,实现应用的敏捷开发与全生命周期管理。
本来生活网通过 KubeSphere,逐步把生产环境从虚拟化迁移到 Kubernetes 之上。
基于 KubeSphere 向导式的交互,让测试团队在还不熟悉 Kubernetes 的情况下,也能对应用进行持续发布,实现应用与基础设施的监控与告警。
KubeSphere 自动采集应用与基础设施的日志,可以方便测试团队进一步调试,从而实现统一的 DevOps 管理。
对于物理机部署的 Kubernetes 集群,Kubernetes 不提供类似 LoadBalancer 服务暴露的功能,而本来生活正是这样的部署方式。
为了实现突破,本来生活网选择了 KubeSphere 的子项目 —— Porter( 一款适用于物理机部署 Kubernetes 的负载均衡器,提供用户在物理环境暴露服务和在云上暴露服务一致性体验的插件 ),作为在物理环境下暴露 Kubernetes 服务的解决方案。
4、用户证言
在没使用 KubeSphere 之前,本来生活网架构团队也调研过其他的平台,都不能满足大部分需求。
当发现 KubeSphere 并邀请应用发布团队试用后,得到了非常正向的反馈,尤其是良好的用户体验以及容器部署的便捷性,测试效率的提升也非常明显。
除此之外,KubeSphere 还极大降低了运维团队的工作复杂度,节省了应用从开发到上线发布的时间成本。
本来生活网不需要再花费大量时间去开发一个可视化平台,并且还能实现自定义的 CI/CD 流程,这对于技术团队来说至关重要。
广告时间:
扫码报名,邀您云见面
参会即有机会赢精美定制奖品!
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
编辑host 文件保存不了咋办 win+R 启动运行 -- 这样就是管理员身份运行了 输入打开对应文件夹 C:Windows\System32\drivers\etc 用编辑器打开 Hosts 文件编辑保存即可
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
一.成员可见性 python 类是有分内部与外部的. 一个类里面定义了各种各样的变量 & 静态方法 类方法,都可以从外部来调用访问,这就造成类不安全,为什么
Step 1.什么叫一个类的外部访问 class Student(): sum = 1 def __init__(self, name, age): self.name = name self.age = age self.__class__.sum += 1 print('当前班级学生总数为:' + str(self.__class__.sum )) def do_homework(self): print('homework') @classmethod def plus_sum(cls): cls.sum += 1 print(cls.sum) @staticmethod def add(x,y): print('This is a static method') student1 = Student('小明', 18) student1.do_homework() //student1调用了do_homework(一个类在外部访问调用do_homework方法)
Step 2.什么叫一个类内部访问 def do_homework(self): self.do_work() //在do_homework调用do_work就叫做一个类的内部调用 print('homework') def do_work(self) print()
Step 3.例子1 $ vim s4.py class Student(): sum = 1 def __init__(self, name, age): self.name = name self.age = age self.score = 0 self.__class__.sum += 1 #print('当前班级学生总数为:' + str(self.__class__.sum )) def marking(self, score): self.score = score print(self.name + '同学本次考试分数为:' + str(self.score)) def do_homework(self): self.do_work() print('homework') def do_work(self): print() @classmethod def plus_sum(cls): cls.sum += 1 print(cls.sum) @staticmethod def add(x,y): print('This is a static method') student1 = Student('小明', 18) student1.marking(59) //实例化marking方法,并进行打分 #student1.do_homework() #执行结果 $ python s4.py 小明同学本次考试分数为:59
Step 4.例子2 student1.marking(-1) 与 student1.score = -1 的区别: student1.score = -1: 直接修改了数据变量,修改了就修改了,没有任何的限制 student1.marking(-1):通过方法对数据操作,比直接对[student1.score]数据变量做修改要安全,但通过方法呢,是可以进行判断的. $ vim s4.py class Student(): sum = 1 def __init__(self, name, age): self.name = name self.age = age self.score = 0 self.__class__.sum += 1 #print('当前班级学生总数为:' + str(self.__class__.sum )) def marking(self, score): self.score = score print(self.name + '同学本次考试分数为:' + str(self.score)) def do_homework(self): self.do_work() print('homework') def do_work(self): print() @classmethod def plus_sum(cls): cls.sum += 1 print(cls.sum) @staticmethod def add(x,y): print('This is a static method') student1 = Student('小明', 18) student1.marking(-1) #student1.do_homework() student1.score = -1class Student(): sum = 1 def __init__(self, name, age): self.name = name self.age = age self.score = 0 self.__class__.sum += 1 #print('当前班级学生总数为:' + str(self.__class__.sum )) def marking(self, score): self.score = score print(self.name + '同学本次考试分数为:' + str(self.score)) def do_homework(self): self.do_work() print('homework') def do_work(self): print() @classmethod def plus_sum(cls): cls.sum += 1 print(cls.sum) @staticmethod def add(x,y): print('This is a static method') student1 = Student('小明', 18) student1.marking(-1) #student1.do_homework() student1.score = -1 //实例化数据变量 # 执行结果 $ python s4.py 小明同学本次考试分数为:-1
Step 5.对方法进行判断 为什么可以对student1.score进行赋值,是因为score成员可见性是公开的,公开 & 私有的 区别,如果一个变量或者函数是公开的话, 就可以在类的外部直接访问 如果是私有的变量或者函数在类的外部是不能直接访问或读取 def marking(self, score):
if score < 0: //如果score 值小于0
score = 0 //强行赋值score 等于0;或者使用:return '不能打负分'
self.score = score
print(self.name + '同学本次考试分数为:' + str(self.score)) $ vim s4.py class Student(): sum = 1 def __init__(self, name, age): self.name = name self.age = age self.score = 0 self.__class__.sum += 1 #print('当前班级学生总数为:' + str(self.__class__.sum )) def marking(self, score): if score < 0: return '不能打负分' self.score = score print(self.name + '同学本次考试分数为:' + str(self.score)) def do_homework(self): self.do_work() print('homework') def do_work(self): print() @classmethod def plus_sum(cls): cls.sum += 1 print(cls.sum) @staticmethod def add(x,y): print('This is a static method') student1 = Student('小明', 18) result = student1.marking(-1) print(result) #执行结果 $ python s4.py 不能打负分
Step 6.如何把方法变成私有 python一旦在方法或变量前面加双下划线'__',那就表示这个变量是私有的,是不能在类的外部读取访问的 在marking方法前面加入双下滑线,可见执行结果是报错的 $ vim s4.py class Student(): sum = 1 def __init__(self, name, age): self.name = name self.age = age self.score = 0 self.__class__.sum += 1 #print('当前班级学生总数为:' + str(self.__class__.sum )) def __marking(self, score): if score < 0: return '不能打负分' self.score = score print(self.name + '同学本次考试分数为:' + str(self.score)) def do_homework(self): self.do_work() print('homework') def do_work(self): print() @classmethod def plus_sum(cls): cls.sum += 1 print(cls.sum) @staticmethod def add(x,y): print('This is a static method') student1 = Student('小明', 18) result = student1.__marking(78) print(result) #执行结果 $ python s4.py Traceback (most recent call last): File "s4.py", line 40, in result = student1.__marking(78) AttributeError: Student instance has no attribute '__marking'
Step 7.1 把变量变成私有 前面的实验把marking方法前面添加双下滑线'__' 之后,在类的外部读取是会报错的 在这里把score变量前面添加双下滑线'__' 之后,在类的外部读取是不会报错的,这是为什么呢? $ s4.py class Student(): sum = 1 def __init__(self, name, age): self.name = name self.age = age self.__score = 0 self.__class__.sum += 1 #print('当前班级学生总数为:' + str(self.__class__.sum )) def marking(self, score): if score < 0: return '不能打负分' self.__score = score print(self.name + '同学本次考试分数为:' + str(self.__score)) def do_homework(self): self.do_work() print('homework') def do_work(self): print() @classmethod def plus_sum(cls): cls.sum += 1 print(cls.sum) @staticmethod def add(x,y): print('This is a static method') student1 = Student('小明', 18) result = student1.marking(78) print(result) #student1.do_homework() student1.__score = -1 #print(student1.__score)
Step 7.2 把变量变成私有 前面说到私有变量是不可读取,不可赋值,但在这里可以正常赋值,并且可读取到双下滑线score的值,这是为什么呢? 并不是因为设置__score实例变量没有生效,而是因为python 动态语言的特性,student1.__score = -1 实际上给student1新添加了一个实例变量,python 是可以通过点'.'的方式添加一个新的实例变量 $ s4.py class Student(): sum = 1 def __init__(self, name, age): self.name = name self.age = age self.__score = 0 self.__class__.sum += 1 #print('当前班级学生总数为:' + str(self.__class__.sum )) def marking(self, score): if score < 0: return '不能打负分' self.__score = score print(self.name + '同学本次考试分数为:' + str(self.__score)) def do_homework(self): self.do_work() print('homework') def do_work(self): print() @classmethod def plus_sum(cls): cls.sum += 1 print(cls.sum) @staticmethod def add(x,y): print('This is a static method') student1 = Student('小明', 18) result = student1.marking(78) print(result) #student1.do_homework() student1.__score = -1 print(student1.__score) #执行结果 $ python s4.py 小明同学本次考试分数为:78 None -1
Step 7.3 实例化另外一个student2 student1 = Student('小明', 18)
student2 = Student('小芳', 18) //实例化另外一个student2
result = student1.marking(78)
student1.__score = -1
print(student1.__score)
print(student2.__score) //读取student2私有属性 执行结果是报错的,为什么读取student1.__score没有报错,但读取student2.__score却报错了. 原因在于有强行赋值的操作[student1.__score = -1],因为python 动态语言的特性,student1.__score = -1 实际上给student1新添加了一个实例变量,python 是可以通过点'.'的方式添加一个新的实例变量 $ vim s4.py class Student(): sum = 1 def __init__(self, name, age): self.name = name self.age = age self.__score = 0 self.__class__.sum += 1 #print('当前班级学生总数为:' + str(self.__class__.sum )) def marking(self, score): if score < 0: return '不能打负分' self.__score = score print(self.name + '同学本次考试分数为:' + str(self.__score)) def do_homework(self): self.do_work() print('homework') def do_work(self): print() @classmethod def plus_sum(cls): cls.sum += 1 print(cls.sum) @staticmethod def add(x,y): print('This is a static method') student1 = Student('小明', 18) student2 = Student('小芳', 18) //实例化另外一个student2 result = student1.marking(78) student1.__score = -1 print(student1.__score) print(student2.__score) //读取student2私有属性 #执行结果 $python s4.py 小明同学本次考试分数为:78 -1 Traceback (most recent call last): File "s4.py", line 47, in print(student2.__score) AttributeError: Student instance has no attribute '__score'
Step 7.4 打印student1属性 在执行结果中可见到 '_Student__score' ,可没设置过这样变量;其实'_Student__score'变量,也就是我们设置的私有 self.__score = score,只不过python 在存储私有变量时会做一个更改,会自动把__score,更改为_Student__score 新的名称 在执行结果中还有一个'__score',是动态添加的 student1.__score = -1 为什么前面访问私有变量,报错提示找不到,因为python 把私有变量的名称改了. vim s4.py class Student(): sum = 1 def __init__(self, name, age): self.name = name self.age = age self.__score = 0 self.__class__.sum += 1 #print('当前班级学生总数为:' + str(self.__class__.sum )) def marking(self, score): if score < 0: return '不能打负分' self.__score = score print(self.name + '同学本次考试分数为:' + str(self.__score)) def do_homework(self): self.do_work() print('homework') def do_work(self): print() @classmethod def plus_sum(cls): cls.sum += 1 print(cls.sum) @staticmethod def add(x,y): print('This is a static method') student1 = Student('小明', 18) #student2 = Student('小芳', 18) result = student1.marking(78) student1.__score = -1 print(student1.__dict__) //打印类属性 #执行结果 $ python s4.py 小明同学本次考试分数为:78 {'age': 18, '_Student__score': 78, '__score': -1, 'name': 'å°æ'}
【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
安装Erlang
由于RabbitMQ依赖Erlang, 所以需要先安装Erlang。
Erlang的安装方式大概有两种:
从Erlang Solution安装(推荐)
# 添加erlang solutions源
$ wget https://packages.erlang-solutions.com/erlang-solutions-1.0-1.noarch.rpm
$ sudo rpm -Uvh erlang-solutions-1.0-1.noarch.rpm
$ sudo yum install erlang
从EPEL源安装(这种方式安装的Erlang版本可能不是最新的,有时候不能满足RabbitMQ需要的最低版本)
# 启动EPEL源
$ sudo yum install epel-release
# 安装erlang
$ sudo yum install erlang
完成后安装RabbitMQ:
先下载rpm:
wget http://www.rabbitmq.com/releases/rabbitmq-server/v3.6.6/rabbitmq-server-3.6.6-1.el7.noarch.rpm
下载完成后安装:
yum install rabbitmq-server-3.6.6-1.el7.noarch.rpm
安装时如果遇到下面的依赖错误
Error: Package: socat-1.7.2.3-1.el6.x86_64 (epel)
Requires: libreadline.so.5()(64bit)
可以尝试先执行
$ sudo yum install socat
关于RabbitMQ的一些基本操作
$ sudo chkconfig rabbitmq-server on # 添加开机启动RabbitMQ服务
$ sudo /sbin/service rabbitmq-server start # 启动服务
$ sudo /sbin/service rabbitmq-server status # 查看服务状态
$ sudo /sbin/service rabbitmq-server stop # 停止服务
# 查看当前所有用户
$ sudo rabbitmqctl list_users
# 查看默认guest用户的权限
$ sudo rabbitmqctl list_user_permissions guest
# 由于RabbitMQ默认的账号用户名和密码都是guest。为了安全起见, 先删掉默认用户
$ sudo rabbitmqctl delete_user guest
# 添加新用户
$ sudo rabbitmqctl add_user username password
# 设置用户tag
$ sudo rabbitmqctl set_user_tags username administrator
# 赋予用户默认vhost的全部操作权限
$ sudo rabbitmqctl set_permissions -p / username ".*" ".*" ".*"
# 查看用户的权限
$ sudo rabbitmqctl list_user_permissions username
更多关于rabbitmqctl的使用,可以参考帮助手册。
开启web管理接口
如果只从命令行操作RabbitMQ,多少有点不方便。幸好RabbitMQ自带了web管理界面,只需要启动插件便可以使用。
$ sudo rabbitmq-plugins enable rabbitmq_management
然后通过浏览器访问
http://localhost:15672
输入用户名和密码访问web管理界面了。
配置RabbitMQ
关于RabbitMQ的配置,可以下载RabbitMQ的配置文件模板到/etc/rabbitmq/rabbitmq.config, 然后按照需求更改即可。
关于每个配置项的具体作用,可以参考官方文档。
更新配置后,别忘了重启服务哦!
开启用户远程访问
默认情况下,RabbitMQ的默认的guest用户只允许本机访问, 如果想让guest用户能够远程访问的话,只需要将配置文件中的loopback_users列表置为空即可,如下:
{loopback_users, []}
另外关于新添加的用户,直接就可以从远程访问的,如果想让新添加的用户只能本地访问,可以将用户名添加到上面的列表, 如只允许admin用户本机访问。
{loopback_users, ["admin"]}
更新配置后,别忘了重启服务哦!
sudo /sbin/service rabbitmq-server status # 查看服务状态
这里可以看到log文件的位置,转到文件位置,打开文件:
这里显示的是没有找到配置文件,我们可以自己创建这个文件
cd /etc/rabbitmq/
vi rabbitmq.config
编辑内容如下:
[{rabbit, [{loopback_users, []}]}].
这里的意思是开放使用,rabbitmq默认创建的用户guest,密码也是guest,这个用户默认只能是本机访问,localhost或者127.0.0.1,从外部访问需要添加上面的配置。
保存配置后重启服务:
service rabbitmq-server stop
service rabbitmq-server start
此时就可以从外部访问了,但此时再看log文件,发现内容还是原来的,还是显示没有找到配置文件,可以手动删除这个文件再重启服务,不过这不影响使用
rm rabbit\@mythsky.log
service rabbitmq-server stop
service rabbitmq-server start
注意:记得要开放5672和15672端口
/sbin/iptables -I INPUT -p tcp --dport 5672 -j ACCEPT
/sbin/iptables -I INPUT -p tcp --dport 15672 -j ACCEPT
---------------------
作者:MC-闰土
来源:CSDN
原文:https://blog.csdn.net/qq_22075041/article/details/78855708
版权声明:本文为博主原创文章,转载请附上博文链接!
6. rabbitmq常用命令
add_user
delete_user
change_password
list_users
add_vhost
delete_vhost
list_vhostsset_permissions [-p ]
clear_permissions [-p ]
list_permissions [-p ]
list_user_permissions
list_queues [-p ] [ ...]
list_exchanges [-p ] [ ...]
list_bindings [-p ]
list_connections [ ...] 【围观】麒麟芯片遭打压成绝版,华为亿元投入又砸向了哪里?>>>
现在验证码的种类真的是越来越多,短信验证码、语音验证码、图片验证码、滑块验证码 ... 我们在 PC 的网页端或者手机上的 app 进行登录或者注册时,应该总会遇见图片验证码,比如下面这类:
#Pillow库
Pillow是一个非常强大的图片处理模块,其中Image是Pillow中最为重要的类,实现了Pillow中大部分的功能,这个类的主要用来表示图片对象。生成图片验证码需要下面这四个类: 1、Image:含有图片对象主体上的一些应用 2、ImageDraw:画笔,用来向图片上添加验证码 3、ImageFont:设置验证码的字体形式 4、ImageFilter:对图片验证码进行模糊处理 先贴上生成验证码的代码: from PIL import Image,ImageDraw,ImageFont,ImageFilter import random,string #获取随机4个字符组合 def getRandomChar(): chr_all = string.ascii_letters+string.digits chr_4 = ''.join(random.sample(chr_all,4)) return chr_4 #获取随机颜色 def getRandomColor(low,high): return (random.randint(low,high),random.randint(low,high),random.randint(low,high)) #制作验证码图片 def getPicture(): width,height = 180,60 #创建空白画布 image = Image.new('RGB',(width,height),getRandomColor(20,100)) #验证码的字体 font = ImageFont.truetype('C:/Windows/fonts/stxinwei.ttf',40) #创建画笔 draw = ImageDraw.Draw(image) #获取验证码 char_4 = getRandomChar() #向画布上填写验证码 for i in range(4): draw.text((40*i+10,0),char_4[i],font = font,fill=getRandomColor(100,200)) #绘制干扰点 for x in range(random.randint(200,600)): x = random.randint(1,width-1) y = random.randint(1,height-1) draw.point((x,y),fill=getRandomColor(50,150)) #模糊处理 image = image.filter(ImageFilter.BLUR) image.save('./%s.jpg' % char_4) ``` 我们都知道图片验证码一般都是以一张图片为底,有不同的背景颜色,然后上面印有4个不同的字符,可能是数字、可能是字母、 也可能是这两种的组合,并且这些字符看起来不会很清晰。 上面代码中的三个函数就分别实现生成图片验证码的某个需求,首先 getRandomChar 函数就用来生成4个随机字符的组合,其中 chr_all 包含了大写字母、小写字母和数字:
abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789 random.sample 方法就是在这些字符的组合中随机挑出若干个(这里我们选的是4个)生成一个新的列表。 getRandomColor 函数则是用来设置RGB三个阈值,RGB是一种最常用的颜色系统,是通过对红(R)、绿(G)、蓝(B)三个颜色通道的变化以及它们相互之间的叠加来得到各式各样的颜色的,每个通道的阈值都在[0,255]之间。 getPicture 函数用来制作图片验证码,具体代码作用都有注释,这里建议字体的颜色与背景颜色的阈值不要重叠,容易出现某个字符可见度很低的情况,这种方式生成的图片验证码是这种形式的:  #captcha库 如果你像我一样好奇这个库的中文意思可以有道一下,你会发现它的中文含义就是验证码,也就是说这个库可能就是用来专门制作验证码的:  你可以先利用清华镜像安装captcha库:
pip install captcha -i https://pypi.tuna.tsinghua.edu.cn/simple 利用captcha库生成图片验证码的代码:
from captcha.image import ImageCaptcha import random,string
chr_all = string.ascii_letters + string.digits chr_4 = ''.join(random.sample(chr_all, 4)) image = ImageCaptcha().generate_image(chr_4) image.save('./%s.jpg' % chr_4) 可以看到我们需要的操作就是将随机生成的4个字符组合传入 ImageCaptcha 类下的 generate_image 方法中,然后他就会自动生成一个图片验证码,形式如下:  #gvcode库 最后一种方法是最简单的,简单到仅需要3行代码就可以实现上面的操作,首先我们也需要安装这个库,注意利用pip安装时要用下面名字:
pip install graphic-verification-code -i https://pypi.tuna.tsinghua.edu.cn/simple 然后贴上生成图片验证码的代码:
import gvcode s,v = gvcode.generate() s.save('./%s.jpg' % v) 你没看错~这三行代码就可以生成一张图片验证码,其中还有一行用来导包,也就说有效代码仅两行!
print(type(s)) print(v) print(type(v)) 其中 s 就是最终生成的图片验证码,v 就是图片验证码上的4个字符,也就是字符串类型,打印一下: 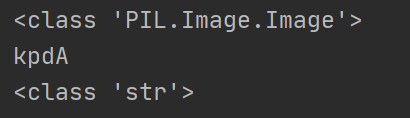 最后这种方法生成的图片验证码形式如下:  #说在最后 这三种方法生成图片验证码各有利弊,第一种方法虽说复杂,但是可以DIY呀,第二种方法生成的图片验证码应该是与我们平时接触的最相似,第三种方法虽说操作最为简单,但是生成的图片验证码有那么一点点看不清。也算是比较有趣的小知识,伙伴们可以去自己试一下啦! >更多文章和资料|点击下方文字直达 ↓↓↓ >[阿里云K8s实战手册 ](https://mp.weixin.qq.com/s/y3fS1tGCWRWSHWq6Ps78hg) >[阿里云CDN排坑指南][CDN](https://mp.weixin.qq.com/s/tedaOubuMo6MjI9d5raclA) >[ECS运维指南](https://mp.weixin.qq.com/s/HbvVUnWJxi4ioZGw8l3jIw) >[DevOps实践手册 ](https://mp.weixin.qq.com/s/GuGgx4NhHtGPaXmfF8Derg) >[Hadoop大数据实战手册](https://mp.weixin.qq.com/s/f7TZQYKeY4_s35ElCrSHFA) >[Knative云原生应用开发指南](https://mp.weixin.qq.com/s/pIDELbr4UPMF6rfwW4AyPw) >[OSS 运维实战手册](https://mp.weixin.qq.com/s/cpOpIL8Hq8iEngAdP5Uduw)
「深度学习福利」大神带你进阶工程师,立即查看>>>
配置 Docker Swarm 配置信息 配置:4核心 4GB内存 系统:CentOS-7.6 1810 Minimal 注意:开始安装前确保系统时间正常 注意: 1.所有命令只需要在部署节点(192.168.2.71)执行 角色信息: harbor: 192.168.2.75 manager: 192.168.2.71 192.168.2.72 worker: 192.168.2.73 192.168.2.74 配置变量 # 替换变量值为实际IP地址 注意主机名与IP个数对应 以空格分隔 HARBOR=192.168.0.75 SERVER_NAME=(node01 node02 node03 node04 node05) SERVER_IP=(192.168.0.71 192.168.0.72 192.168.0.73 192.168.0.74 192.168.0.75) 设置本地Host解析 # 清理 hosts(只保留2行 新增 swarm 集群主机hosts解析) sed -i '3,$d' /etc/hosts echo -e "\n# swarm cluster" >> /etc/hosts let SER_LEN=${#SERVER_IP[@]}-1 for ((i=0;i<=$SER_LEN;i++)); do echo "${SERVER_IP[i]} ${SERVER_NAME[i]}" >> /etc/hosts done 配置ssh秘钥登录 # 替换 list 中的IP为实际IP 替换 SSH_RROT_PASSWD 值为 root SSH 密码 SSH_RROT_PASSWD=redhat curl -sSL -o ssh-key-copy.sh https://dwz.cn/S0NQWllm chmod +x ssh-key-copy.sh && ./ssh-key-copy.sh "$(echo ${SERVER_IP[@]})" root $SSH_RROT_PASSWD # 同步hosts文件 for node in ${SERVER_IP[@]}; do scp /etc/hosts $node:/etc/hosts done 设置主机名 for node in ${SERVER_IP[@]}; do ssh -T $node <<'EOF' HOST_IF=$(ip route|grep default|cut -d ' ' -f5) HOST_IP=$(ip a|grep "$HOST_IF$"|awk '{print $2}'|cut -d'/' -f1) hostnamectl set-hostname $(grep $HOST_IP /etc/hosts | awk '{print $2}') EOF done 优化参数 for node in ${SERVER_IP[@]}; do ssh -T $node <<'EOF' # 优化ssh连接速度 sed -i "s/#UseDNS yes/UseDNS no/" /etc/ssh/sshd_config sed -i "s/GSSAPIAuthentication .*/GSSAPIAuthentication no/" /etc/ssh/sshd_config systemctl restart sshd # 配置yum源 rm -f /etc/yum.repos.d/*.repo curl -so /etc/yum.repos.d/epel-7.repo http://mirrors.aliyun.com/repo/epel-7.repo curl -so /etc/yum.repos.d/Centos-7.repo http://mirrors.aliyun.com/repo/Centos-7.repo sed -i '/aliyuncs.com/d' /etc/yum.repos.d/Centos-7.repo /etc/yum.repos.d/epel-7.repo # 防火墙 firewall-cmd --set-default-zone=trusted firewall-cmd --complete-reload iptables -P INPUT ACCEPT iptables -F iptables -X iptables -F -t nat iptables -X -t nat iptables -F -t raw iptables -X -t raw iptables -F -t mangle iptables -X -t mangle # 内核参数 echo 'net.ipv4.ip_forward = 1' >> /etc/sysctl.conf echo 'net.bridge.bridge-nf-call-iptables = 1' >> /etc/sysctl.conf echo 'net.bridge.bridge-nf-call-ip6tables = 1' >> /etc/sysctl.conf modprobe br_netfilter sysctl -p -w /etc/sysctl.conf # stop selinux setenforce 0 sed -i 's#SELINUX=.*#SELINUX=disabled#' /etc/selinux/config EOF done 安装 Docker # 定义变量 SOURCE_DIR=/home DOCKER_VER=18.09.8 DOCKER_DATA=/var/lib/docker DOCKER_HOME=/usr/local/docker INSECURE=$HARBOR MIRROR=http://3272dd08.m.daocloud.io # 下载二进制包 DOCKER_URL="https://mirrors.tuna.tsinghua.edu.cn/docker-ce/linux/static/stable/x86_64/docker-${DOCKER_VER}.tgz" mkdir -p $SOURCE_DIR $DOCKER_HOME/bin && cd $SOURCE_DIR curl -C- -O --retry 3 "$DOCKER_URL" --progress # 解压 tar zxf $SOURCE_DIR/docker-${DOCKER_VER}.tgz -C $DOCKER_HOME/bin --strip-components 1 ln -sf $DOCKER_HOME/bin/docker /bin/docker # 创建 docker 服务管理脚本 cat > /etc/systemd/system/docker.service <<-EOF [Unit] Description=Docker Application Container Engine Documentation=http://docs.docker.io [Service] Environment="PATH=$DOCKER_HOME/bin:/bin:/sbin:/usr/bin:/usr/sbin" ExecStart=$DOCKER_HOME/bin/dockerd ExecStartPost=/sbin/iptables -I FORWARD -s 0.0.0.0/0 -j ACCEPT ExecReload=/bin/kill -s HUP \$MAINPID Restart=on-failure RestartSec=5 LimitNOFILE=infinity LimitNPROC=infinity LimitCORE=infinity Delegate=yes KillMode=process [Install] WantedBy=multi-user.target EOF # 创建docker配置文件 mkdir -p $DOCKER_DATA /etc/docker cat > /etc/docker/daemon.json <<-EOF { "registry-mirrors": ["$MIRROR"], "insecure-registries": ["$INSECURE"], "max-concurrent-downloads": 10, "log-driver": "json-file", "log-level": "warn", "log-opts": { "max-size": "10m", "max-file": "3" }, "data-root": "/var/lib/docker" } EOF # 启动服务 systemctl enable docker systemctl daemon-reload systemctl restart docker # 验证 docker info && docker --version 命令补全 curl -sSL https://dwz.cn/ivKazMlX -o /etc/bash_completion.d/docker curl -sSL https://dwz.cn/SV7woGp8 -o /usr/share/bash-completion/bash_completion echo -e "\nsource /usr/share/bash-completion/bash_completion" >> ~/.bashrc 同步 Docker 到其他节点 for node in node0{2..5}; do echo "-------------------- $node --------------------" scp -r ${DOCKER_HOME} ${node}:${DOCKER_HOME} ssh ${node} 'mkdir -p /etc/docker' scp /etc/docker/daemon.json ${node}:/etc/docker/daemon.json scp /etc/systemd/system/docker.service ${node}:/etc/systemd/system/docker.service ssh ${node} 'systemctl enable docker' ssh ${node} 'systemctl daemon-reload' ssh ${node} 'systemctl restart docker' ssh ${node} "ln -sf $DOCKER_HOME/bin/docker /bin/docker" scp /etc/bash_completion.d/docker ${node}:/etc/bash_completion.d/docker scp /usr/share/bash-completion/bash_completion ${node}:/usr/share/bash-completion/bash_completion scp ~/.bashrc ${node}:~/.bashrc done 防火墙(swarm 集群通信)(貌似可以忽略) for node in node0{1..5}; do ssh -T ${node} < # manager # docker swarm 常用命令 docker swarm init # 初始化集群 docker swarm join-token worker # 查看工作节点的 token docker swarm join-token manager # 查看管理节点的 token docker swarm join # 加入集群中 #docker node 常用命令 docker node ls # 查看所有集群节点 docker node rm # 删除某个节点(-f强制删除) docker node inspect # 查看节点详情 docker node demote # 节点降级,由管理节点降级为工作节点 docker node promote # 节点升级,由工作节点升级为管理节点 docker node update # 更新节点 docker node ps # 查看节点中的 Task 任务 # docker service 常用命令 docker service create # 部署服务 docker service inspect # 查看服务详情 docker service logs # 产看某个服务日志 docker service ls # 查看所有服务详情 docker service rm # 删除某个服务(-f强制删除) docker service scale # 设置某个服务个数 docker service update # 更新某个服务 # docker stack 常用命令 docker stack deploy # 部署新的堆栈或更新现有堆栈 docker stack ls # 列出现有堆栈 docker stack ps # 列出堆栈中的任务 docker stack rm # 删除堆栈 docker stack services # 列出堆栈中的服务 docker stack down # 移除某个堆栈(不删数据) # 活动的主节点Down 在另一个主节点执行 docker swarm init --force-new-cluster # 将分配了任务的工作节点 node03 下线: docker node update --availability drain node03 # 再次将被下线的节点重置为活动状态 docker node update --availability active node03 GUI管理界面 curl -L https://downloads.portainer.io/portainer-agent-stack.yml -o portainer-agent-stack.yml docker stack deploy -c portainer-agent-stack.yml portainer https://docs.docker.com/engine/reference/commandline/stack_services/
「深度学习福利」大神带你进阶工程师,立即查看>>> Ansible是一个系列文章,我会尽量以通俗易懂、诙谐幽默的总结方式给大家呈现这些枯燥的知识点,让学习变的有趣一些。
前言
对于任何一个框架,一个应用,为了更便于推广,便于使用,便于商业化,都会顺便提供很多常用的模块,这样让大家也很容易使用起来。Ansible也是一样的,所以这些常用的模块,就好比基本功,基本招式一样,我们需要掌握这些基本功,掌握这些基本招式。这篇文章,就对这些常用的模块进行一个比较全面的总结。
ping模块
ping 是测试远程节点的SSH连接是否就绪的常用模块,但是它并不像Linux命令那样简单地ping一下远程节点,而是先检查能否通过SSH登陆远程节点,再检查其Python版本能否满足要求,如果都满足则会返回pong,表示成功。使用方式如下: ansible web -m ping
ping 无须任何参数。上述命令输出结果如下所示: 192.168.1.2 | SUCCESS => { "changed": false, "ping": "pong" } 192.168.1.4 | SUCCESS => { "changed": false, "ping": "pong" }
debug模块
打印输出信息,类似Linux上的echo命令。在后续的学习过程中,我们会经常用这个命令来调试我们写的playbook。
对于 debug 模块有两种用法。下面就对这两种用法都进行详细的总结。 通过参数msg定义打印的字符串 msg中可以嵌入变量,比如我先定义了以下的一个playbook。 --- - hosts: web vars: name: jellythink tasks: - name: display debug: msg="I am {{name}}" 通过参数var定义需要打印的变量 变量可以是系统变量,也可以是动态的执行结果,通过关键字 register 注入变量中。对于变量,我们可以这样玩: --- - hosts: web vars: name: jellythink tasks: - name: display debug: var: name
对于注入变量,可以这样玩: --- - hosts: web tasks: - name: register var shell: hostname register: result - name: display debug: var: result
copy模块
从当前的机器上复制静态文件到远程节点上,并且设置合理的文件权限。 copy 模块在复制文件的时候,会先比较一下文件的checksum,如果相同则不会复制,返回状态为OK;如果不同才会复制,返回状态为changed。
一般情况的使用,就是这样的: --- - hosts: server1 tasks: - name: copyDemo copy: src: /home/jelly/nameList.txt dest: /home/test1/nameList.txt
在实际的工作中,一般会在进行文件分发时,需要备份原文件,这个时候就需要我们加上 backup 选项: --- - hosts: server1 tasks: - name: copyDemo copy: src: /home/jelly/nameList.txt dest: /home/test1/nameList.txt backup: yes
加上 backup: yes 后,在目标主机上,就会对原来的文件进行备份,比如这样子的备份文件: nameList.txt.8648.2019-09-28@06:27:18~
template模块
如果只是复制静态文件,使用 copy 模块就可以了;但是如果在复制的同时需要根据实际情况修改部分内容,那么就需要用到 template 模块了。
比如我们在分发配置文件时,每个配置文件需要根据远程主机的一些属性不同而配置不同的值,对于需要替换的部分,我们就可以使用 template 模块来进行替换。 template 模块使用的是Python中的Jinja2模板引擎,这里我们不需要过多的去关注这个模板引擎,只需要知道变量的表示法是 {{}} 就可以了。比如这里就有一个http.conf.j2的模板文件,文件内容如下: Listen {{ansible_default_ipv4.address}} Port {{http_port}}
其中 {{ansible_default_ipv4.address}} 就是需要根据不同的主机,动态变化的。接下来,我们就可以这样使用 template 模块来完成变量的替换。 --- - hosts: server1 vars: http_port: 8080 tasks: - name: Write Config File template: src: http.conf.j2 dest: /home/test1/http.conf
在目的主机上,文件内容如下: Listen 192.168.1.3 Port 8080
和 copy 模块一样, template 模块也可以进行权限设置和文件备份等功能。
file模块
file 模块可以用来设置远程主机上的文件、软链接和文件夹的权限,也可以用来创建和删除它们。
我们可以使用 mode 参数进行权限修改,可以直接赋值数字权限(必须以0开头)。 --- - hosts: server1 tasks: - name: Modify Mode file: path: /home/test1/http.conf mode: 0777
我们还可以根据 state 参数的不同,实现不同的行为,比如创建软链接: --- - hosts: server1 tasks: - name: Create Soft Link file: src: /home/test1/http.conf dest: /home/test1/conf state: link
也可以设置 state: touch 创建一个新文件,比如这样: --- - hosts: server1 tasks: - name: Create a new file file: path: /home/test1/touchfile state: touch mode: 0700
还可以设置 state: directory 新建一个文件夹,比如这样: --- - hosts: server1 tasks: - name: Create directory file: path: /home/test1/testDir state: directory mode: 0755
user模块
user 模块可以对用户进行管理,实现增、删、改Linux远程节点的用户账户。比如增加用户: --- - hosts: server1 tasks: - name: Add user user: name: test3
删除用户: --- - hosts: server1 tasks: - name: Add user user: name: test3 state: absent remove: yes
但是在使用这个 user 模块时,需要注意权限问题。
shell模块
在远程节点上通过 /bin/sh 执行命令。如果一个命令可以通过模块 yum 、 copy 模块实现时,那么建议不要使用 shell 或者 command 这样通用的命令模块。因为通用的命令模块不会根据具体操作的特点进行状态判断,所以当没有必要再重新执行的时候,它还是会重新执行一遍。 支持 < 、 > 、 | 、 ; 和 & --- - hosts: server1 tasks: - name: Test shell shell: echo "test1" > ~/testDir/test1 && echo "test2" > ~/testDir/test2 调用脚本 --- - hosts: server1 tasks: - shell: ~/test.sh >> somelog.txt
在执行命令之前,我们可以改变工作目录,并且仅在文件somelog.txt不存在时执行命令,除此之外,还可以指定用bash运行命令: --- - hosts: server1 tasks: - shell: ~/test.sh >> somelog.txt args: chdir: ~/testDir creates: somelog.txt executable: /bin/bash
command模块
在远程节点上执行命令。和 shell 模块类似,但不支持 < 、 > 、 | 、 ; 和 & 等操作,其它的大抵都是相似的。
总结
Ansible提供了非常多的常用模块,我们可以使用 ansible-doc -l 命令查看这些模块。这篇文章只是总结了几个用的频率更高一点的,对于这里总结的常用模块,我们需要做到“手到擒来”,熟练到上手就能写的地步,大家需要在理解的基础上,多上手写,多练习。在今后的工作中多用这些常用的模块来提升自己的工作效率。
夜,又静了!
2019年9月29日,于内蒙古呼和浩特。
「深度学习福利」大神带你进阶工程师,立即查看>>>
firewall和netfilter 临时关闭防火墙 selinux 使用命令 setenforce 0 如果想永久关闭防火墙,需要修改配置文件 配置文件地址是 /etc/selinux/config 可以使用 vi /etc/selinux/config 进行修改 如图,打开config文件后,可以看到上图内容 这里需要把 SELINUX=enforcing 的值 修改为 disabled 也就是 SELINUX=disabled ,然后保存退出,重启系统就生效了 如图,命令 getenforce 可以查看 selinux 的状态 上图显示为 Enforcing 表示是打开状态 使用 setenforce 0 命令把 selinux 临时关闭 然后再使用 getenforce 查看 selinux 的状态 可以看到变成了 Permissive Permissive的意思是,一些会触发防火墙的操作,系统会提出警告 如果是 Enforcing 状态,系统会直接打断操作 而 Permissive 状态下,系统不会打断操作,但是会在后台记录警告信息 也就是说,可以进行一些会触发 selinux 的操作 除了selinux这个防火墙外,还有另外一个防火墙叫做 netfilter selinux防火墙是对内的,而 netfilter 是对外的 网络过来的包会被netfilter处理,如果通过了netfilter 进入到系统内部,则会受到 selinux 的限制 想要控制 netfilter 工作 可以使用 iptables 和 firewalld 这两个工具来操作netfilter centOS7 之前的版本,都是使用 iptables 来操作 netfilter 从centOS7开始,新增了 firewalld 工具也可以操作 netfilter firewalld 本质上是 iptables 的封装 firewalld 的命令实际上也是由 iptables 来实现的 等于是把复杂的iptables命令封装起来,变成一条简单的firewalld命令 与iptables相比,firewalld操作简单一些,也有更强大的功能 centOS7 的默认防火墙工具是 firewalld 而不是 iptables 在firewalld里面也可以使用iptables的命令 但是不推荐使用,在firewalld工具里面最好还是使用firewalld命令为佳 因为firewalld也是用iptables来实现的,很多公司也在用centOS6,不支持firewalld 所以 iptables 也是要了解清楚的 centOS7 默认使用的是 firewalld 如果想使用 iptables 需要先关闭 firewalld 如图,systemctl disable firewalld 关闭firewalld,这样重启后就不会启动firewalld 下面的命令 systenctl stop firewalld 是停止正在运行的firewalld服务 这样就把 firewalld 设置为关闭,并且停止了正在运行的firewalld 要使用 iptables 要先安装一个包,如上图 关闭了 firewalld 服务后,需要开启 iptables 服务 如图,systemctl enable ipptables 命令将iptables 设置为可开启状态 然后 systemctl start iptables 打开 iptables 服务 如图,使用命令 iptables -nvL 可以查看 iptables 的默认规则信息
netfilter5表5链介绍 使用命令 man iptables 往下翻页,可以看到上图中的信息 filter,nat,mangle,raw,security 代表5张表 默认的表是 filter 如图,filter 解释里面有三个链的信息 filter内置了3个链,分别是 input,output,forward 三个链 input 可以对进入本机系统内核的数据包进行处理 forward 是指进入机器的数据包,但是不进入系统内核 因为有些数据包经过本机,但是目标地址并不是本机 如果数据包的目标地址不是本机,只是路过本机就会进入 forward 链 forward链就可以对这些数据包进行操作,比如 修改目标地址 output链可以对 本机内核出去的数据包进行一些操作 举例说明,本机要发一个数据包到一个ip地址去 但是管理员不希望本机有任何数据包被发送到这个ip地址 这时就可以在output链设置规则,所有目标地址是这个ip地址的包都不能出去 前提是这些数据包是本机产生的,因为output只对本机产生的包有效 如图所示,外面发送数据包到本机 数据包会从 in 的位置进入,首先经过 prerouting 链 在 prerouting 链里面,会经过三张表的策略进行判断数据包的去向 每个链里面,都有显示 表 的名称 就说明,经过这个链的时候,这些表里面写好的规则会起作用 比如说,prerouting 里面有三个表,nat,mangle,raw 这说明,在这三个表里面,可以写一些针对经过 prerouting 链的数据包的规则 每一个经过 prerouting 链的数据包,都会被这些规则处理一遍 从链的流向来看,数据包到达 prerouting链,这里会判断数据包的目的地 目的地是本机,数据包会进入 input 链,然后到达本机内核 经过内核处理,本机发出的数据包会进入 output 链,然后到达postrouting链 如果数据包的目的地不是本机,而是由本机进行转发 prerouting链 就会判断将数据包发向 forward链 数据包经过 forward链 进入 postrouting链,然后从网卡出去 每经过一条链的时候,如果在相应的表里面写了规则 那么数据包经过这条链的时候,就会按照这些规则进行处理 如果没写规则,就直接放行了 每条链有不同的表可以设置规则,每条链并不可以使用所有表的规则 只有 对应的表的规则 可以使用 filter,nat,mangle,raw,security 这5个表里面 常用的就是 filter 和 nat 剩下的三个都不怎么常用,主要了解 filter 和 nat filter 主要是用来过滤数据包的,可以设置怎样的数据包不能通过之类的 nat 则是处理网络地址转换,也就是跟ip有关的规则
iptables语法 使用 iptables -nvL 查看规则信息 如图,可以看到 input,forward,output三条链上的规则 iptables 如果不指定表的话,默认就是显示 filter 的规则信息 所以图中显示的链是 filter 可以操作的链 上图命令可以重启 iptables 上图是 cat 默认规则的配置文件,/etc/sysconfig/iptables 就是规则的配置文件 每次重启iptables后,都会从这个配置文件里面导入规则 所以如果不把自己修改的规则保存到这个配置文件里面的话 每次重启,之前自己修改的规则就会消失,因为会重新加载这个配置文件的规则 如图, iptables -F 命令可以把目前正在运行的规则清空 执行上面命令后,再使用 iptables -nvL 查看规则 可以看到,下面的规则表已经清空了,没有任何规则信息了 但是 -F 参数只能清空正在运行的规则列表 这时打开 iptables配置文件查看的话,就会发现 iptables配置文件里面还是有规则,并没有清空 如果重启 iptables 的话,配置文件里面的规则会被重新加载 如果想把当前运行状态的规则保存到配置文件里面 可以使用上图命令 例如,当前状态是 空规则,如果使用 service iptables save 那么配置文件里面的规则就会被空规则覆盖掉,也就是说没有任何规则 不过一般不这样做,因为可以在需要的时候重新加载配置文件 把清空的规则加载回来 因为不指定表的话,默认表就是 filter 所以上面的操作都是针对 filter表的,包括清空规则 如果想指定修改的表 如图,可以使用 -t 参数 上图中,-t nat 就是指定显示 nat 表的规则 如上图所示,规则信息,第一列是包的数量 第二列是数据包总的大小,单位是字节 这两列数据是可以清空的 使用命令 iptables -Z 就可以清空这两列数据 参数 -Z 可以把计数器清零 上图命令是添加规则的命令 iptables 后面的参数里面,没有 -t 说明没有指定表 在没有指定表的情况下,就是对默认表 filter 进行操作 参数 -A 是 add 增加规则的意思 后面接 INPUT 是指增加的规则是针对 input链的 也就是说,这条规则会对 input链的数据包进行操作 后面的 -s 参数是指定数据包来源的 ip,后面接来源 ip地址 参数 -p 是指定数据包传输协议的,后面接协议名称,这里是 tcp 参数 --sport 是指定数据包来源端口的,后面是端口号 1234 参数 -d 是指定数据包目标ip的,后面接目标ip地址 参数 --dport 是指定数据包目标ip端口的,后面接端口号,这里是80 参数 -j 是指定操作规则的,后面接规则名称,这里是 DROP DROP 是指符合以上设置的数据包会被直接扔掉,不能通过 也可以使用 REJECT 规则,这个规则也是不让数据包通过 与 DROP的区别是,drop会直接扔掉,reject会通知对方自己扔掉了数据包 一般都是使用 DROP 执行完增加规则的命令后,使用 -nvL 查看filter规则信息 如上图,input链所有规则,最下面增加了一条规则 第三列是 DROP 表示这是 drop 规则 后面是他 tcp 表示协议,然后是来源ip 和 目标ip 最后是 来源端口 和 目标端口 一般来说,增加规则后,新规则都会出现在原来规则的最下面,优先级是靠后的 上图命令也可以增加规则 参数 -I 是插入一条规则的意思, INPUT 是规则插入input链 后面指定了 -p tcp 协议,还有 --dport 80 指定端口,前面必须先指定协议,不然会报错 最后是规则 -j DROP 这条命令是把 目标地址端口号为 80 的数据包 drop掉 如上图,插入的规则出现在所有规则的最上面 如果是使用 -A 增加规则,新规则会出现在所有规则的最下面 插入 -I 的意义就是可以把新规则插入到所有规则最上面,提高优先级 一条链里面规则的执行顺序是从上到下的,会先执行上面的,一条一条往下执行 所以 I 参数可以让新规则插入到最高优先级 上图是删除命令,如果想删除刚才插入的规则 把 -I 参数 换成 -D 参数 后面跟插入命令一模一样,就可以删除刚才插入的命令 但是有一个问题,如果忘记了后面的命令怎么写,应该怎样删除旧的命令 上图是显示规则编号的命令 iptables -nvL --line-number 可以多显示一列,num列 参数 --line-number 可以显示规则的编号 然后使用命令 iptables -D INPUT + 规则编号 就可以删除相应编号的规则 如图,参数 -D表示删除,INPUT表示规则是input链的,7表示编号7的规则 执行这条命令后,如图,编号7的规则就已经删除了 如图所示,policy 是指默认的策略,后面接 ACCEPT 说明,默认的规则就是 ACCEPT 如果一条链上面没有设置任何规则 那么通过这条链的数据包就会按照默认策略进行处理 比如这里,默认策略是 ACCEPT ,如果没有设置规则的话,数据包都是直接通过的 默认策略是可以更改的,上图命令 iptables -P OUTPUT DROP 就可以把 OUTPUT链上的默认策略改为DROP 参数 -P 就是设置 policy的意思,OUTPUT是指output链,DROP就是具体策略 所以上面命令就是,设置 OUTPUT链的policy为 DROP 如果是通过xshell远程连接,执行上面命令的话就会直接断线 因为远程连接需要跟主机有数据包的往返操作 这条命令把主机出来的数据包drop掉了,主机就没办法跟外界有交流 如果执行了这条命令断线后,需要在主机的终端 重新把默认策略修改为 ACCEPT 才能恢复远程连接 所以,默认策略一般不用修改,都是保持 ACCEPT 状态 需要拦截数据包就添加规则
iptables filter表小案例 这个案例是把 80端口,21端口,22端口的数据放行 22端口指定一个ip段,只有这个ip段才可以访问 如上图,编辑一个iptables.sh文件 在iptables.sh内输入上图内容 #!/bin/bash ipt="/usr/sbin/iptables" $ipt -F $ipt -P INPUT DROP $ipt -P OUTPUT ACCEPT $ipt -P FORWARD ACCEPT $ipt -A INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT $ipt -A INPUT -s 192.168.133.0/24 -p tcp --dport 22 -j ACCEPT $ipt -A INPUT -p tcp --dport 80 -j ACCEPT $ipt -A INPUT -p tcp --dport 21 -j ACCEPT 然后 wq 保存退出,这是一个脚本 /usr/sbin/iptables 是iptables命令的文件路径 把这个文件赋值给了变量 ipt 下面的命令,$ipt -F 就是执行了清空规则的命令 $ipt -P INPUT DROP 是把input链的策略修改为DROP $ipt -P OUTPUT ACCEPT,$ipt -P FORWARD ACCEPT 就是把output和forward链的策略 设置为 ACCEPT $ipt -A INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT input策略是DROP,这条命令是设置通过条件 符合上面规则的数据包就可以通过 参数 -m 是设置模块,模块指定为 state 指定了state模块后,就可以使用 --state 指定状态 RELATED,ESTABLISHED 表示两个状态 参数 -j 指定规则为 ACCEPT 所以条件就是 状态为 RELATED,ESTABLISHED 的数据包可以通过 $ipt -A INPUT -s 192.168.133.0/24 -p tcp --dport 22 -j ACCEPT 上面命令是指定特定网段的数据才可以通过 参数 -s 指定来源ip端口为 192.168.133.0/24 参数 -p指定协议为 tcp tcp的扩展模块 --dport 指定目标端口为 22 所以来自于192.168.133.0/24 这个网段/端口的数据包,如果目标端口是22就可以通过 $ipt -A INPUT -p tcp --dport 80 -j ACCEPT $ipt -A INPUT -p tcp --dport 21 -j ACCEPT 以上两条命令是 目标端口为 80 或者 21 的数据包都可以通过 也就是开放了80和21端口,向这两个端口发送数据就可以通过 如图,sh 执行这个脚本 如图,查看filter规则,可以看到,input链的规则已经变成脚本设置的规则了 上图命令的作用是,使外部的机器无法 ping 通本机 本机网络是通的,使用了这条规则后 本机ping外面的ip是可以通的,外面的ip ping进来是无法ping通的 但是本机网络却是通的,也就是说,这条命令就是让外面无法ping通本机 不影响本机网络的使用
「深度学习福利」大神带你进阶工程师,立即查看>>>
学习Linux的最佳方法是将它用于日常工作。 阅读Linux书籍,观看Linux视频不仅仅是足够的。 学习 Linux 没有捷径可走。 你不可能在一夜之间在Linux中掌握。 这需要时间和持久性。 刚刚潜入。最好的学习方法就是去做。 如果你卡住 了,百度会解决 你的问题。从那里开始,你会有意想不到的收获。
我不会说我是Linux忍者,但我知道如何在Linux中快速轻松地完成工作。 以下是我过去几年学习Linux所做的工作。
一旦我决定使用Linux,我就从笔记本电脑上卸载了Windows,尽管我不知道如何正确使用Linux。 我开始使用Ubuntu作为我个人和官方使用的主要操作系统。 现在,我正式和个人使用Arch Linux作为我的主要操作系统。
我在 从百度 上搜索了Windows应用程序的最佳替代品。 在以下链接中,您可以找到Windows应用程序的最佳替代方案。 然后我从未使用过Windows操作系统及其应用程序。 我完全转向了Linux
一开始我对linux ’ 不大熟悉,在朋友的推荐下,我买了本 《linux就该这么学》 ,总体的知识点通俗易懂,最棒的是,他去除了那些繁琐的东西,真可谓是详略得当,可以让读者快速掌握一门系统,更秒的是,老师全篇都已一种朋友的语气教你学知识,看着这本书,你无意间会发现老师的很多幽默点。让你更有精神,也更容易读下去,所以,我强烈推荐想学linux的小白入门这一书。
一旦我熟悉Linux,我安装了Oracle VirtualBox来测试各种操作系统。 从那以后,我测试了很多Linux操作系统。 我目前的Arch linux桌面拥有100多个虚拟机。 我将它们用于测试,学习和工作目的。
我订阅了 很多 流行的Linux博客,例如 Linux就该这么学 的网站,叫 Linux probe , 这个网站是刘遄老师建立的,上面每天都会发布一些关于 Linux 的最新资讯,还有技术干货,网站还有配套的课程,如果你是个初学者,你可以从这个网站看到很多有趣的内容。不会觉得枯燥乏味。 还有china-unix网站,这个最初是鸟哥创办的网站,目前在中国已经发展成 Linux 爱好者最大的集群网站 , 如果平时你在学习 Linux 中有遇到一些问题,可以在这个论坛上面发布出来 。 当然,我 也 有自己的博客 ,比方说,博客园,我经常把自己学到的内容在这上面分享, 我建议您 查看 这些网站。 这些网站每天,每周发布有用且高质量的Linux相关内容。
然后我开始测试所有服务器概念,例如在流行的Linux操作系统中逐个安装和配置DNS服务器,DHCP服务器,FTP,Samba服务器等。 我建议你在虚拟机上测试它们。 这是virtualbox提供帮助的地方。 在生产系统中实施之前,请在虚拟环境中彻底了解所有服务器。 有关所有服务器相 关指南,请参阅以下博客。 它几乎包含所有服务器配置指南。 “服务器世界 - 构建网络服务器”这个网站, 不要经常使用GUI。 学习如何从终端做东西。 命令行模式更强大,更容易。 我大多使用命令行来做东西。 这是学习几乎所有命令的 最好方式 。
不要使用双启动。 它会降低你的学习能力。 你不会努力寻找Linux替代品。 如果您对使用Linux感到厌倦或厌倦,您可以轻松切换到Windows。 所以,不要这样做。 仅使用Linux。 每天你都会学到新东西。 我已经使用Linux 5年以上了,还在学习新东西。就像Linux有着无穷无尽的学习曲线。 自从我切换到Linux后,我从未对使用我的电脑感到厌倦。 我切换到Linux的那天从未回到过Windows。
最后但不是 至少,不要害怕犯错误。 试错 法 是解决问题的基本 方法 。 如果你做了可怕的错误,不要放弃或讨厌Linux。 一年前,我意外地格式化(销毁了整个数据)我的Linux桌面,它有很多重要的东西。 我天真,好奇。 所以,我运行了一个致命的Linux命令,并在几秒钟内摧毁了多年的备份。 这是我做过的最蠢的事。 但是,我并没有停止学习Linux。 如果您做错了什么,请随时询问Linux社区或在 Linux一些博客 上发布您的问题。 Linux社区真的很有帮助。
这就是我学习Linux的方式。 我只是通过经验学到了它。
「深度学习福利」大神带你进阶工程师,立即查看>>>
基本使用 把标准输入转换成命令行参数,传递给 xargs 后的命令使用 echo 'one two three' | xargs mkdir # 等于 mkdir one two three 默认命令 echo seq 1 8 | xargs # 等于 seq 1 8 | xargs echo -d 指定分隔符,默认是换行和空格 echo -e "a\tb\tc" | xargs -d "\t" echo -p 打印出要执行的命令,并询问用户是否执行 -t 打印出要执行的命令,直接执行 -0 指定 null 当作分隔符,一般用于分隔包含空格的字符串列表 find /path -type f -print0 | xargs -0 rm -L 指定标准输入中的多少行作为一个参数 -n 一行中可能包含空格分隔的多项,该参数指定每次将多少项作为命令行参数 -I 指定每一项命令行参数的替代字符串 seq 1 8 | xargs -I PAT echo PAT -P 指定同时使用多少个进程执行命令,默认只用一个,0 表示不限制 --show-limits 查看系统命令行缓冲上限
「深度学习福利」大神带你进阶工程师,立即查看>>>
1. 为什么连接的时候是三次握手,关闭的时候却是四次握手?
因为当Server端收到Client端的SYN连接请求报文后,可以直接发送SYN+ACK报文。其中ACK报文是用来应答的,SYN报文是用来同步的。但是关闭连接时,当Server端收到FIN报文时,很可能并不会立即关闭SOCKET,所以只能先回复一个ACK报文,告诉Client端,"你发的FIN报文我收到了"。只有等到我Server端所有的报文都发送完了,我才能发送FIN报文,因此不能一起发送。故需要四步握手。
2. 为什么不能用两次握手进行连接?
这主要是为了防止已失效的连接请求报文段突然又传到了B,因而产生错误。
现假定一种异常情况,即A发出的第一个连接请求报文段并没有丢失,而是在某些网络节点长时间滞留了,以致延误到连接释放后的某个时间才到达B。本来这是一个早已失效的报文段。但B受到此失效的连接请求报文段后,就误以为是A又发出一次新的连接请求,于是就向A发出确认报文段,同意建立连接。假定不采用第三次报文握手,那么只要B发出确认,新的连接就建立了。
由于现在A并没有发出建立连接的请求,因此不会理睬B的确认,也不会向B发送数据,但B却以为新的运输连接已经建立了,并一直等待A发来的数据。B的许多资源就这样白白浪费了。
采用三次握手连接,可以防止上述现象的发生。例如在刚才的异常情况下,A不会向B的确认发出确认,B由于收不到确认,就知道A并没有要求建立连接,于是B就不会再建立连接。
3. 为什么TIME_WAIT状态需要经过2MSL才能返回到CLOSE状态? 第一,为了保证A发送的最后一个ACK报文段能够到达B。假设网络是不可靠的,有可以最后一个ACK丢失。所以TIME_WAIT状态就是用来重发可能丢失的ACK报文。在Client发送出最后的ACK回复,但该ACK可能丢失。Server如果没有收到ACK,将不断重复发送FIN片段。所以Client不能立即关闭,它必须确认Server接收到了该ACK。Client会在发送出ACK之后进入到TIME_WAIT状态。Client会设置一个计时器,等待2MSL的时间。如果在该时间内再次收到FIN,那么Client会重发ACK并再次等待2MSL。所谓的2MSL是两倍的MSL(Maximum Segment Lifetime)。MSL指一个片段在网络中最大的存活时间,2MSL就是一个发送和一个回复所需的最大时间。如果直到2MSL,Client都没有再次收到FIN,那么Client推断ACK已经被Server成功接收,则结束TCP连接。 第二,防止“已失效的连接请求报文段”出现在本连接中。A在发送完最后一个ACK报文段后,再经过时间2MSL,就可以使本连接持续的时间内所产生的所有报文段都从网络中消失。这样就可以使下一个新的连接中不会出现这种旧的连接请求报文段。
4. 如果已经建立了连接,但是客户端突然出现故障了怎么办?
TCP还设有一个保活计时器,显然,客户端如果出现故障,服务器不能一直等下去,白白浪费资源。服务器每收到一次客户端的请求后都会重新复位这个计时器,时间通常是设置为2小时,若两小时还没有收到客户端的任何数据,服务器就会发送一个探测报文段,以后每隔75分钟发送一次。若一连发送10个探测报文仍然没反应,服务器就认为客户端出了故障,接着就关闭连接。

.png) 大数据引擎
大数据引擎.png) 大数据应用
大数据应用.png) 大数据底层技术
大数据底层技术.png) ForeSpider软件
ForeSpider软件
.png) 采集服务
采集服务.png) 软件学习
软件学习.png) 智能分析
智能分析.png) 特征提取
特征提取.png) 智能计算
智能计算.png) 数据可视化
数据可视化.png) 数据分析应用
数据分析应用.png) 系统集成服务
系统集成服务.png) 代码工具
代码工具.png) 金融方案
金融方案.png) 制造业&物流
制造业&物流.png) 企业数字化
企业数字化.png) 医疗方案
医疗方案.png) 政务方案
政务方案.png) 实时监测
实时监测.png) 智能分析
智能分析.png) 数据智能挖掘
数据智能挖掘.png) 全网自动采集
全网自动采集.png) 场景智慧采集
场景智慧采集.png) 主题识别采集
主题识别采集







 022-2345 2937
022-2345 2937 185 2247 0110
185 2247 0110 business@forenose.com
business@forenose.com














 022-2345 2937
022-2345 2937 185 2247 0110
185 2247 0110 business@forenose.com
business@forenose.com 前嗅大数据
前嗅大数据